 半监督学习算法的现实性评价
半监督学习算法的现实性评价
编者按:半监督学习是近年来非常热门的一个研究领域,毕竟机器学习模型的本质是个“吃”数据的“怪兽”,虽然现实世界拥有海量数据,但针对某个问题的标记数据却仍极度稀缺。为了用更少的标记数据完成更多现实任务,研究人员想出了这种从无标记数据中提取数据结构的巧妙做法。那么它能被用于现实任务吗?今天论智带来的是NIPS 2018收录的一篇Google Brain论文:Realistic Evaluation of Semi-Supervised Learning Algorithms。
摘要
当遇到标签有限或没有足够经费请人标记数据等问题时,半监督学习(SSL)提供了一个强大的框架。近年来,基于深层神经网络的SSL算法在标准基准测试任务中被证明是有用的。但是,我们认为这些基准测试并不能解决在应用于实际任务时,这些算法将面临的各种问题。
我们为一些广泛使用的SSL算法重新创建了统一实现,并在一系列任务中对它们进行了测试。实验发现:那些不使用未标记数据的简单基线的性能通常被低估了;对于不同数量的标记数据和未标记数据,SSL算法的敏感程度也不同;并且当未标记数据集中包含不属于该类的数据时,网络性能会大幅降低。
为了帮助指导SSL研究真正能适应现实世界,我们公开了论文的统一重新实现和评估平台。
简介
无数实验已经证实,如果我们对大量数据进行标记,那么深层神经网络就能在某些监督学习任务上实现和人类相仿,甚至超人的表现。然而,这种成功是需要代价的。也就是说,为了创建大型数据集,我们往往要耗费大量的人力、财力和风险在数据标记上。因此对于许多现实问题,它们没有足够的资源来构建足够大的数据集,这就限制了深度学习的广泛应用。
解决这一问题的一种可行方法是使用半监督学习框架。和需要标记数据的监督学习算法相比,SSL算法能从未标记数据中提取数据结构,进而提高网络性能,这降低了操作门槛。而最近的一些研究结果也表明,在某些情况下,即便给定数据集中的大部分数据都遗失了标签,SSL算法也能接近纯监督学习的表现。
面对这些成功,一个自然而然的问题就是:SSL算法能否被用于现实世界的任务?在本文中,我们认为答案是否定的。具体而言,当我们选择一个大型数据集,然后去除其中的大量标签对比SSL算法和纯监督学习算法时,我们其实忽略了算法本身的各种常见特征。
下面是我们的一些发现:
如果两个神经网络在调参上花费相同资源,那么用SSL和只用标记数据带来的性能差异会小于以往论文的实验结论。
不使用未标记数据的、高度正则化的大型分类器往往具有强大性能,这证明了在同一底层模型上评估不同SSL算法的重要性。
如果先在不同的标记数据集上预训练模型,之后再在指定数据集上训练模型,它的最终性能会比用SSL算法高不少。
如果未标记数据中包含与标记数据不同的类分布,使用SSL算法的神经网络的性能会急剧下降。
事实上,小的验证集会妨碍不同方法、模型和超参数设置之间的可靠比较。
评估方法改进
科研人员评估SSL算法一般遵循以下流程:首先,选择一个用于监督学习的通用数据集,删去其中大多数数据的标签;其次,把保留标签的数据制作成小型数据集D,把未标记数据整理成数据集DUL;最后,用半监督学习训练一些模型,在未经修改的测试集上检验它们的性能。
但下面是现有方法的缺陷及其改进:
P.1 一个共享的实现
现有SSL算法比较没有考虑底层模型的一致性,这是不科学的。在某些情况下,同样是简单的13层CNN,不同实现会导致一些细节,比如参数初始化、数据预处理、数据增强、正则化等,发生改变。不同模型的训练过程(优化、几个epoch、学习率)也是不一样的。因此,如果不用同一个底层实现,算法对比不够严谨。
P.2 高质量监督学习基线
SSL的目标是基于标记数据集D和未标记数据集DUL,使模型的性能比单独用D训练出来的完全相同的基础模型更好。虽然道理很简单,但不同论文对于这个基线的介绍却存在出入,比如去年Laine&Aila和Tarvainen&Valpola在论文中用了一样的基线,虽然模型是一样的,但它们的准确率差竟然高达15%。
为了避免这种情况,我们参考为SSL调参,重新调整了基线模型,确保它的高质量。
P.3 和迁移学习的对比
在实践中,如果数据量有限,通常我们会用迁移学习,把在相似大型数据集上训练好的模型拿过来,再根据手头的小数据集进行“微调”。虽然这种做法的前提是存在那么一个相似的、够大的数据集,但如果能实现,迁移学习确实能提供性能强大的、通用性好的基线,而且这类基线很少有论文提及。
P.4 考虑类分布不匹配
需要注意的是,当我们选择数据集并删去其中大多数数据的标签时,这些数据默认DUL的类分布和D的完全一致。但这不合理,想象一下,假设我们要训练一个能区分十张人脸的分类器,但每个人的图像样本非常少,这时,你可能会选择使用一个包含随机人脸图像的大型未标记数据集来进行填充,那么这个DUL中的图像就并不完全是这十个人的。
现有的SSL算法评估都忽略了这种情况,而我们明确研究了类分布相同/类分布不同数据之间的影响。
P.5 改变标记和未标记数据的数量
改变两种数据的数量这种做法并不罕见,研究人员通常喜欢通关删去不同数量的底层标记数据来改变D的大小,但到目前为止,以系统的方式改变DUL确不太常见。这可以模拟两种现实场景:一是未标记数据集非常巨大(比如用网络数十亿未标记图像提高模型分类性能),二是未标记数据集相对较小(比如医学影像数据,它们的成本很高)。
P.6 切合实际的小型验证集
人为创建的SSL数据集往往有个特征,就是验证集会比训练集大很多。比如SVHN的验证集大约有7000个标记数据,许多论文在用这个数据集做研究时,往往只从原训练集里抽取1000个标记数据,但会保留完整验证集。这就意味着验证集是训练集的7倍,而在现实任务中,数据更多的集一般是会被作为训练集的。
实验
这个实验的目的不是产生state-of-art的结果,而是通过建立一个通用框架,对各种模型性能进行严格的比较分析。此外,由于我们使用的模型架构和超参数调整方法和以前的论文很不一样,它们也没法和过去的工作直接比较,只能单独列出。
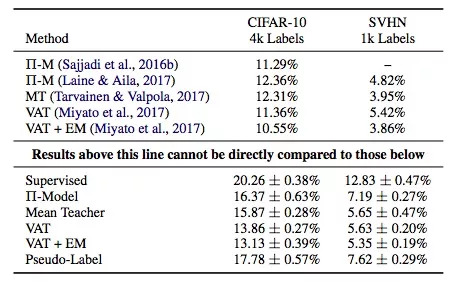
上表是实用各SSL算法的模型在验证集上的错误率,它们使用了同样的底层模型——Wide ResNet,纵坐标是监督学习和各类常用的SSL算法:Π-Model, Mean Teacher, Virtual Adversarial Training, PseudoLabeling,以及Entropy Minimization。
需要注意的是,表格上部是前人的工作,下部是本文的成果,它们不能直接对比(本文模型使用的参数是上面的一半,所以性能会差一些)。但是,透过数据我们还是可以发现:
结论1:Mean Teacher和VAT的表现总体不错。
结论2:监督学习模型和半监督学习模型之间的性能差异并没有其他论文中描述的那么大。
结论3:基于这个表格的数据,我们用迁移学习训练了一个模型,发现它在CIFAR-10验证集上的错误率是12%,这个结果比SSL算法更好。
上图是各模型在CIFAR-10上的错误率,已知标记训练集有6类图像,每类图像400个样本。其中纵坐标是错误率,横坐标是未标记数据相对标记数据的不同类分布占比,比如25%表示未标记数据集中有1/4的类是标记数据集上没有的。阴影区是五次实验标准差。
结论4:和不使用任何未标记数据相比,如果我们在未标记数据集中加入更多的额外类,模型的性能会降低。
结论5:SSL算法对标记数据/未标记数据的不同数据量很敏感。
上图是各算法模型的平均验证错误对比,使用的是10个大小不同的随机采样非重叠验证集。实线是平均值,阴影是标准差,训练集是包含1000个标记数据的SVHN。图中的纵坐标是错误率,横坐标是验证集相对于训练集的大小,比如10%表示验证集只包含100个标记数据。
结论6:10%是个合适的比例,因此对于严重依赖大型验证集做超参数调整的SSL算法,它们的实际适用性很有限,即便是交叉验证也没法带来太多改善。
总结
通过上述实验结果,我们已经证实把SSL算法用于现实实践暂时是不恰当的,那么今后该怎么评估它们呢?下面是一些建议:
在比较不同SSL算法时,使用完全相同的底层模型。模型结构的差异,甚至是细节,都会对最终结果产生很大影响。
仔细调整基线的在使用监督学习和迁移学习时的准确率,SSL的目标应该是明显优于完全监督学习。
呈现数据中混有其他类数据时模型的性能变化,因为这是现实场景中很常见的现象。
报告性能时,测试不同标记数据/未标记数据量下的情况。理想情况下,即便标记数据非常少,SSL算法也能从未标记数据中提取到有用信息。因此我们建议将SVHN与SVHN-Extra相结合,以测试算法在大型未标记数据中的性能。
不要在不切实际的大型验证集上过度调参。
-
神经网络
+关注
关注
42文章
4769浏览量
100687 -
算法
+关注
关注
23文章
4606浏览量
92801 -
SSL
+关注
关注
0文章
125浏览量
25735
原文标题:NIPS 2018入选论文:对深度半监督学习算法的现实评价
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于半监督学习框架的识别算法
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习
如何用Python进行无监督学习
谷歌:半监督学习其实正在悄然的进化
机器学习算法中有监督和无监督学习的区别
最基础的半监督学习
半监督学习最基础的3个概念
半监督学习:比监督学习做的更好
密度峰值聚类算法实现LGG的半监督学习






 工商网监
工商网监
评论