 基于Pandas进行初步数据探索和准备的Scikit-Learn用户方案
基于Pandas进行初步数据探索和准备的Scikit-Learn用户方案
Scikit-Learn发布0.20预览版,Scikit-Learn与Pandas的新融合会使以往的工作流程更为简单,其功能也更为丰富、更具鲁棒性。
Scikit-Learn的0.20版本,将会是进行近年来最重磅的升级。
对于许多数据科学家来说,一个典型的工作流程是在Scikit-Learn进行机器学习之前,用Pandas进行探索性的数据分析。新版本的Scikit-Learn将会让这个过程变得更加简单、功能更加丰富、更鲁棒以及更加标准化。
注:本文中的0.20版本的是指预览版,最终版本目前还没有发布。
升级到0.20版本
几日前,官方刚刚发布这个0.20的预览版。用户可以通过conda命令进行安装:
condainstallscikit-learn=0.20rc1-cconda-forge/label/rc-cconda-forge
也可以通过pip命令进行安装:
pipinstall—prescikit-learn
ColumnTransformer、升级版OneHotEncoder介绍
随着0.20版本的升级,从Pandas到Scikit-Learn的许多工作流会变得比较相似。ColumnTransformer估计器会将一个转换应用到Pandas DataFrame(或数组)列的特定子集。
OneHotEncoder估计器不是“新生物”,但已经升级为编码字符串列。以前,它只对包含数字分类数据的列进行编码。
接下来,让我们看看这些新添加的功能是如何处理Pandas DataFrame中的字符串列的。
Kaggle住房数据集
Kaggle最早的机器学习竞赛题目之一是《住房价格:先进的回归技术》。其目标是在给定80个特征情况下,预测房价。
数据一览
在DataFrame中读取数据并输出前几行。
>>>importpandasaspd>>>importnumpyasnp>>>train=pd.read_csv(‘data/housing/train.csv’)>>>train.head()

>>>train.shape(1460,81)
从训练集中删除目标变量
目标变量是SalePrice,我们将它作为数组移除并分配给它自己的变量。我们将在后面的机器学习中用到它。
>>>y=train.pop('SalePrice').values
编码单个字符串列
首先,我们编码一个字符串列HoustStyle,它具有房子外观的值。让我们输出每个字符串值的唯一计数。
>>>vc=train['HouseStyle'].value_counts()>>>vc1Story7262Story4451.5Fin154SLvl65SFoyer371.5Unf142.5Unf112.5Fin8Name:HouseStyle,dtype:int64
这一列中有8个唯一值(unique value)。
scikitlearn Gotcha必须有2D数据
大多数Scikit-Learn估计器严格要求数据是的2D的。从技术角度讲,如果我们选择上面的列作为train[“HouseStyle”],Pandas Series是数据的单一维度。我们可以强制Pandas创建一个单列DataFrame,方法是将一个单项列表传递到方括号中,如下所示:
>>>hs_train=train[['HouseStyle']].copy()>>>hs_train.ndim2
评估器的三个步骤过程——导入、实例化、匹配
Scikit-Learn API对于所有的估计器都是一致的,它根据下面三个步骤来匹配(训练)数据。
从它所在的模块中导入我们想要的估计器
实例化估计器,可能改变它的默认值
根据数据拟合估计量。在必要情况下,可以将数据转换到新的空间。
下面,我们导入一个hotencoder,将它实例化,并确保返回一个密集(而不是稀疏)的数组,然后用fit_transform方法对单个列进行编码。
>>>fromsklearn.preprocessingimportOneHotEncoder>>>ohe=OneHotEncoder(sparse=False)>>>hs_train_transformed=ohe.fit_transform(hs_train)>>>hs_train_transformedarray([[0.,0.,0.,...,1.,0.,0.],[0.,0.,1.,...,0.,0.,0.],[0.,0.,0.,...,1.,0.,0.],...,[0.,0.,0.,...,1.,0.,0.],[0.,0.,1.,...,0.,0.,0.],[0.,0.,1.,...,0.,0.,0.]])
正如预期的那样,它将每个唯一的值编码为自己的二进制列。
>>>hs_train_transformed.shape(1460,8)
得到了NumPy数组,那么列名在哪里?
注意,我们的输出是一个NumPy数组,而不是Pandas DataFrame。Scikit-Learn最初不是为了直接与Pandas整合而建的。所有的Pandas对象都在内部转换成NumPy数组,并且在转换后总是返回NumPy数组。
我们仍然可以通过其get_feature_names方法从OneHotEncoder对象获得列名。
>>>feature_names=ohe.get_feature_names()>>>feature_namesarray(['x0_1.5Fin','x0_1.5Unf','x0_1Story','x0_2.5Fin','x0_2.5Unf','x0_2Story','x0_SFoyer','x0_SLvl'],dtype=object)
验证第一行数据的正确性
接下来让我们验证估计值是否正确。首先是第一行编码的数据。
>>>row0=hs_train_transformed[0]>>>row0array([0.,0.,0.,0.,0.,1.,0.,0.])
这将数组中的第6个值编码为1。让我们使用布尔索引(boolean index)来显示特征名称。
>>>feature_names[row0==1]array(['x0_2Story'],dtype=object)
现在,让我们验证原始DataFrame列中的第一个值是否相同。
>>>hs_train.values[0]array(['2Story'],dtype=object)
使用inverse_transform来实现自动化
与大多数transformer对象一样,有一个inverse_transform方法可以返回原始数据。在这里,我们必须将row0包装在一个列表中,使其成为一个2D数组。
>>>ohe.inverse_transform([row0])array([['2Story']],dtype=object)
我们可以通过转置整个转换后的数组来验证所有的值。
>>>hs_inv=ohe.inverse_transform(hs_train_transformed)>>>hs_invarray([['2Story'],['1Story'],['2Story'],...,['2Story'],['1Story'],['1Story']],dtype=object)>>>np.array_equal(hs_inv,hs_train.values)True
将转换应用到测试集中
无论我们对训练集做什么转换,我们都必须应用到测试集。
>>>test=pd.read_csv('data/housing/test.csv')>>>hs_test=test[['HouseStyle']].copy()>>>hs_test_transformed=ohe.transform(hs_test)>>>hs_test_transformedarray([[0.,0.,1.,...,0.,0.,0.],[0.,0.,1.,...,0.,0.,0.],[0.,0.,0.,...,1.,0.,0.],...,[0.,0.,1.,...,0.,0.,0.],[0.,0.,0.,...,0.,1.,0.],[0.,0.,0.,...,1.,0.,0.]])
我们又得到了8列。
>>>hs_test_transformed.shape(1459,8)
必须impute缺失数据
现在,我们必须impute缺失数据。预处理模块中旧的Imputer已经被弃用。一个新的模块——impute,由一个新的估计值SimpleImputer和一个新的策略“常量”组成。默认情况下,此策略将用字符串“missing_value”来填充缺失值。我们可以选择使用fill_value参数设置它。
>>>hs_train=train[['HouseStyle']].copy()>>>hs_train.iloc[0,0]=np.nan>>>fromsklearn.imputeimportSimpleImputer>>>si=SimpleImputer(strategy='constant',fill_value='MISSING')>>>hs_train_imputed=si.fit_transform(hs_train)>>>hs_train_imputedarray([['MISSING'],['1Story'],['2Story'],...,['2Story'],['1Story'],['1Story']],dtype=object)
接下来,我们可以像以前那样编码啦!
>>>hs_train_transformed=ohe.fit_transform(hs_train_imputed)>>>hs_train_transformedarray([[0.,0.,0.,...,1.,0.,0.],[0.,0.,1.,...,0.,0.,0.],[0.,0.,0.,...,0.,0.,0.],...,[0.,0.,0.,...,0.,0.,0.],[0.,0.,1.,...,0.,0.,0.],[0.,0.,1.,...,0.,0.,0.]])
注意,我们现在有了一个额外的列和一个额外的特征名称。
>>>hs_train_transformed.shape(1460,9)>>>ohe.get_feature_names()array(['x0_1.5Fin','x0_1.5Unf','x0_1Story','x0_2.5Fin','x0_2.5Unf','x0_2Story','x0_MISSING','x0_SFoyer','x0_SLvl'],dtype=object)
更多关于fit_transform的细节
对于所有的估计器,fit_transform方法将首先调用fit方法,然后调用transform方法。fit方法找到转换过程中使用的关键属性。例如,对于SimpleImputer,如果策略是“均值”,那么它就会在fit方法中找到每一列的均值。它会存储每一列的均值。当调用transform时,它使用每个列的这个存储平均值来填充缺失值并返回转换后的数组。
OneHotEncoder原理是类似的。在fit方法中,它会找到每个列的所有唯一值,并再次存储这些值。在调用transform时,它使用这些存储的惟一值来生成二进制数组。
将两个转换应用到测试集
我们可以手动应用上面的两个步骤,如下所示:
>>>hs_test=test[['HouseStyle']].copy()>>>hs_test.iloc[0,0]='uniquevaluetotestset'>>>hs_test.iloc[1,0]=np.nan>>>hs_test_imputed=si.transform(hs_test)>>>hs_test_transformed=ohe.transform(hs_test_imputed)>>>hs_test_transformed.shape(1459,8)>>>ohe.get_feature_names()array(['x0_1.5Fin','x0_1.5Unf','x0_1Story','x0_2.5Fin','x0_2.5Unf','x0_2Story','x0_SFoyer','x0_SLvl'],dtype=object)
使用一个Pipeline来替代
Scikit-Learn提供了一个Pipeline估计器,它获取一个转换列表并依次应用它们。您还可以运行机器学习模型作为最终评估器。在这里,我们只是简单地impute和编码。
>>>fromsklearn.pipelineimportPipeline
每个步骤是一个two-item元组,由一个标记步骤和实例化估计器的字符串组成。前一个步骤的输出是后一个步骤的输入。
>>>si_step=('si',SimpleImputer(strategy='constant',fill_value='MISSING'))>>>ohe_step=('ohe',OneHotEncoder(sparse=False,handle_unknown='ignore'))>>>steps=[si_step,ohe_step]>>>pipe=Pipeline(steps)>>>hs_train=train[['HouseStyle']].copy()>>>hs_train.iloc[0,0]=np.nan>>>hs_transformed=pipe.fit_transform(hs_train)>>>hs_transformed.shape(1460,9)
通过简单地将测试集传递给transform方法,可以轻松地通过Pipeline的每个步骤转换测试集。
>>>hs_test=test[['HouseStyle']].copy()>>>hs_test_transformed=pipe.transform(hs_test)>>>hs_test_transformed.shape(1459,9)
为什么只对测试集转换方法?
在转换测试集时,重要的是只调用transform方法,而不是fit_transform。当我们在训练集中运行fit_transform时,Scikit-Learn找到了它需要的所有必要信息,以便转换包含相同列名的任何其他数据集。
多字符串列转换
对多列字符串进行编码不成问题。先选择你要编码的列,再通过同样的流程传递新的数据框架。
>>>string_cols=['RoofMatl','HouseStyle']>>>string_train=train[string_cols]>>>string_train.head(3)RoofMatlHouseStyle0CompShg2Story1CompShg1Story2CompShg2Story>>>string_train_transformed=pipe.fit_transform(string_train)>>>string_train_transformed.shape(1460,16)
把握pipeline的每个部分
我们可以通过named_steps字典属性中的名称检索pipeline中的每个转换器。在本例中,我们可以得到一个热门编码器,用来输出特征名称。
>>>ohe=pipe.named_steps['ohe']>>>ohe.get_feature_names()array(['x0_ClyTile','x0_CompShg','x0_Membran','x0_Metal','x0_Roll','x0_Tar&Grv','x0_WdShake','x0_WdShngl','x1_1.5Fin','x1_1.5Unf','x1_1Story','x1_2.5Fin','x1_2.5Unf','x1_2Story','x1_SFoyer','x1_SLvl'],dtype=object)
使用新的列转换器来选择列
全新的列转换器(属于新组合模块的一部分)可以让用户选择要让哪些列获得哪些转换。 与连续列相比,分类列几乎总是需要单独的转换。
列转换器目前是还是实验性的,其功能将来可能会发生变化。
ColumnTransformer获取三项元组(tuple)的列表。 元组中的第一个值其标记作用的名称,第二个是实例化的估算器,第三个是要进行转换的列的列表。 元组如下所示:
('name',SomeTransformer(parameters),columns)
这里的列实际上不必一定是列名。用户可以使用列的整数索引,布尔数组,甚至函数(它可以使用整个DataFrame作为参数,并且必须返回选择的列)。
用户也可以将NumPy数组与列转换器一起使用,但本教程主要关注Pandas的集成,因此我们这里继续使用DataFrames。
将pipeline传递给列转换器
我们甚至可以将多个转换的流程传递给列转换器,我们现在正是要这样做,因为在字符串列上有多个转换。
下面,我们使用列转换器重现上述流程和编码。 请注意,实际流程与上面的流程完全相同,只是附加了每个变量名称的cat。 我们将在下一章节中为数字列添加不同的流程。
>>>fromsklearn.composeimportColumnTransformer>>>cat_si_step=('si',SimpleImputer(strategy='constant',fill_value='MISSING'))>>>cat_ohe_step=('ohe',OneHotEncoder(sparse=False,handle_unknown='ignore'))>>>cat_steps=[cat_si_step,cat_ohe_step]>>>cat_pipe=Pipeline(cat_steps)>>>cat_cols=['RoofMatl','HouseStyle']>>>cat_transformers=[('cat',cat_pipe,cat_cols)]>>>ct=ColumnTransformer(transformers=cat_transformers)
将整个DataFrame传递给列转换器
列转换器实例可以选择我们想要使用的列,因此我们只需将整个DataFrame传递给fit_transform方法,就可以选择我们所需的列。
>>>X_cat_transformed=ct.fit_transform(train)>>>X_cat_transformed.shape(1460,16)
然后可以使用同样的方法转换测试集。
>>>X_cat_transformed_test=ct.transform(test)>>>X_cat_transformed_test.shape(1459,16)
检索特征名
我们必须进一步挖掘,来获取特征名。所有的转换器都存储在named_transformers_ dictionary属性中。 然后使用特征名、含有三项要素的元组中的第一项,来选择特定的转换器。 下面的代码就是选择转换器(此例中只有一个流程,名为cat)。
>>>pl=ct.named_transformers_['cat']
然后从这个流程中选择一个热编码器对象,最后得到特征名。
>>>ohe=pl.named_steps['ohe']>>>ohe.get_feature_names()array(['x0_ClyTile','x0_CompShg','x0_Membran','x0_Metal','x0_Roll','x0_Tar&Grv','x0_WdShake','x0_WdShngl','x1_1.5Fin','x1_1.5Unf','x1_1Story','x1_2.5Fin','x1_2.5Unf','x1_2Story','x1_SFoyer','x1_SLvl'],dtype=object)
转换数字列
数字列需要一组不同的转换。我们不使用常亮来填充缺失值,而是经常选择中值或均值。一般不对列中的值进行编码,而是通常将列中的值减去每列的平均值并除以标准差,对列中的值进行标准化。这有助于让许多模型产生更好的拟合结果(比如脊回归)。
使用所有数字列
我们可以选择所有数字列,而不是像处理字符串列一样,手动选择一列或两列。首先使用dtypes属性查找每列的数据类型,然后测试每个dtype的类型是否为“O”。 dtypes属性会返回一系列NumPy dtype对象,每个对象都有一个单一字符的kind属性。我们可以利用它来查找数字或字符串列。 Pandas将其所有字符串列存储为kind属性等于“O”的对象。有关kind属性的更多信息,请参阅NumPy文档。
>>>train.dtypes.head()Idint64MSSubClassint64MSZoningobjectLotFrontagefloat64LotAreaint64dtype:object
获取kind属性,该属性是表示dtype的单字字符串。
>>>kinds=np.array([dt.kindfordtintrain.dtypes])>>>kinds[:5]array(['i','i','O','f','i'],dtype='
假设所有的数字列都是非对象性的。我们可以使用同样的方法来获取类别列。
>>>all_columns=train.columns.values>>>is_num=kinds!='O'>>>num_cols=all_columns[is_num]>>>num_cols[:5]array(['Id','MSSubClass','LotFrontage','LotArea','OverallQual'],dtype=object)>>>cat_cols=all_columns[~is_num]>>>cat_cols[:5]array(['MSZoning','Street','Alley','LotShape','LandContour'],dtype=object)
获取数字列列名之后,可以再次使用列转换器。
>>>fromsklearn.preprocessingimportStandardScaler>>>num_si_step=('si',SimpleImputer(strategy='median'))>>>num_ss_step=('ss',StandardScaler())>>>num_steps=[num_si_step,num_ss_step]>>>num_pipe=Pipeline(num_steps)>>>num_transformers=[('num',num_pipe,num_cols)]>>>ct=ColumnTransformer(transformers=num_transformers)>>>X_num_transformed=ct.fit_transform(train)>>>X_num_transformed.shape(1460,37)
类别列和数字列转换的结合
我们可以使用类转换器对DataFrame的每个部分进行单独转换。在本文的示例中,我们将使用每一列。
然后,将类别列和数字列分别创建单独的流程,然后使用列转换器进行独立转换。这两个转换过程是并行的。最后,将每个转换结果连接在一起。
>>>transformers=[('cat',cat_pipe,cat_cols),('num',num_pipe,num_cols)]>>>ct=ColumnTransformer(transformers=transformers)>>>X=ct.fit_transform(train)>>>X.shape(1460,305)
机器学习
本文的重点就是设置数据,以便进行机器学习。我们可以创建一个最终流程,并添加机器学习模型作为最终的估算器。这个流程的第一步就是我们上文刚刚完成的整个转换过程。我们在本文开始处设定y表示售价。在这里,我们将使用thefit方法,而不是fit_transform方法,因为流程的最后一步是机器学习模型,而且不进行转换。
>>>fromsklearn.linear_modelimportRidge>>>ml_pipe=Pipeline([('transform',ct),('ridge',Ridge())])>>>ml_pipe.fit(train,y)
我们可以用score方法来评估模型,它将返回一个R-Squared值:
>>>ml_pipe.score(train,y)0.92205
交叉验证
当然,在训练集上进行自我评分是没有用的。我们需要做一些K重交叉验证,以了解如何处理不可见的数据。这里我们设置一个随机状态,以便在整个教程的其余各部分保持同样的状态。
>>>fromsklearn.model_selectionimportKFold,cross_val_score>>>kf=KFold(n_splits=5,shuffle=True,random_state=123)>>>cross_val_score(ml_pipe,train,y,cv=kf).mean()0.813
在网格搜索时选择参数
在Scikit-Learn中进行网格搜索,要求我们将映射传递至到可能值的参数名称字典中。 在流程中,我们必须将步骤的名称加上双下划线,然后使用参数名。 如果流程中有多个层级,必须继续使用双下划线,向上移动一级,直至到达我们想要优化其参数的估算器为止。
>>>fromsklearn.model_selectionimportGridSearchCV>>>param_grid={'transform__num__si__strategy':['mean','median'],'ridge__alpha':[.001,0.1,1.0,5,10,50,100,1000],}>>>gs=GridSearchCV(ml_pipe,param_grid,cv=kf)>>>gs.fit(train,y)>>>gs.best_params_{'ridge__alpha':10,'transform__num__si__strategy':'median'}>>>gs.best_score_0.819
在Pandas DataFrame中获取所有网格搜索结果
网格搜索的所有结果都存储在cv_results_属性中。 这是一个字典,可以转换为Pandas DataFrame以获得更好的显示效果,该属性使用一种更容易进行手动扫描的结构。
>>>pd.DataFrame(gs.cv_results_)
参数网格中每一种组合中都包含大量数据
构建一个具备全部基础功能的自定义转换器
在上述工作流程中存在一些限制。例如,如果热编码器允许在使用fit方法期间忽略缺失值,那就更好了,那就可以简单地将缺失值编码为全零行。而目前,它还要强制用户用一些字符串去填充缺失值,然后将此字符串编码为单独的列。
低频字符串
此外,在训练集中仅出现几次的字符串列,可能不是测试集中的可靠预测变量。我们可能希望将它们编码为缺失值。
编写自己的估算器类
Scikit-Learn可以帮助用户编写自己的估算器类。基本模块中的BaseEstimator类可以提供get_params和set_params方法。当进行网格搜索时,set_params方法是必需的。用户可以自己编写,也可以用BaseEstimator。还有一个TransformerMixin,但只是为用户编写fit_transform方法。
以下代码构建的类基本转换器可执行以下操作:
•使用数字列的均值或中位数填充缺失值
•对所有数字列进行标准化
•对字符串列使用一个热编码
•不用再填充类别列中的缺失值,而是直接将其编码为0
•忽略测试集中字符串列中的少数独特值
•允许您为字符串列中值必须具有的出现次数选择阈值。低于此阈值的字符串将被编码为全0
•仅适用于DataFrames,并且只是实验性的,未经过测试,因此可能会破坏某些数据集。
•之所以称其为“基本”转换器,是因为对许多数据集而言,这些操作属于最基本的转换。
fromsklearn.baseimportBaseEstimatorclassBasicTransformer(BaseEstimator):def__init__(self,cat_threshold=None,num_strategy='median',return_df=False):#storeparametersaspublicattributesself.cat_threshold=cat_thresholdifnum_strategynotin['mean','median']:raiseValueError('num_strategymustbeeither"mean"or"median"')self.num_strategy=num_strategyself.return_df=return_dfdeffit(self,X,y=None):#AssumesXisaDataFrameself._columns=X.columns.values#Splitdataintocategoricalandnumericself._dtypes=X.dtypes.valuesself._kinds=np.array([dt.kindfordtinX.dtypes])self._column_dtypes={}is_cat=self._kinds=='O'self._column_dtypes['cat']=self._columns[is_cat]self._column_dtypes['num']=self._columns[~is_cat]self._feature_names=self._column_dtypes['num']#Createadictionarymappingcategoricalcolumntounique#valuesabovethresholdself._cat_cols={}forcolinself._column_dtypes['cat']:vc=X[col].value_counts()ifself.cat_thresholdisnotNone:vc=vc[vc>self.cat_threshold]vals=vc.index.valuesself._cat_cols[col]=valsself._feature_names=np.append(self._feature_names,col+'_'+vals)#gettotalnumberofnewcategoricalcolumnsself._total_cat_cols=sum([len(v)forcol,vinself._cat_cols.items()])#getmeanormediannum_cols=self._column_dtypes['num']self._num_fill=X[num_cols].agg(self.num_strategy)returnselfdeftransform(self,X):#checkthatwehaveaDataFramewithsamecolumnnamesas#theonewefitifset(self._columns)!=set(X.columns):raiseValueError('PassedDataFramehasdifferentcolumnsthanfitDataFrame')eliflen(self._columns)!=len(X.columns):raiseValueError('PassedDataFramehasdifferentnumberofcolumnsthanfitDataFrame')#fillmissingvaluesnum_cols=self._column_dtypes['num']X_num=X[num_cols].fillna(self._num_fill)#Standardizenumericsstd=X_num.std()X_num=(X_num-X_num.mean())/stdzero_std=np.where(std==0)[0]#Ifthereis0standarddeviation,thenallvaluesarethe#same.Setthemto0.iflen(zero_std)>0:X_num.iloc[:,zero_std]=0X_num=X_num.values#createseparatearrayfornewencodedcategoricalsX_cat=np.empty((len(X),self._total_cat_cols),dtype='int')i=0forcolinself._column_dtypes['cat']:vals=self._cat_cols[col]forvalinvals:X_cat[:,i]=X[col]==vali+=1#concatenatetransformednumericandcategoricalarraysdata=np.column_stack((X_num,X_cat))#returneitheraDataFrameoranarrayifself.return_df:returnpd.DataFrame(data=data,columns=self._feature_names)else:returndatadeffit_transform(self,X,y=None):returnself.fit(X).transform(X)defget_feature_names():returnself._feature_names
使用基础转换器
上面构建的基础转换器估算器应该可以像任何其他scikit-learn估算器一样使用。我们可以将其实例化,然后转换数据。
>>>bt=BasicTransformer(cat_threshold=3,return_df=True)>>>train_transformed=bt.fit_transform(train)>>>train_transformed.head(3)
DataFrame中数字列和类别列相交处的列
在pipeline中使用转换器
上文构建的转换器可以作为流程的一部分。
>>>basic_pipe=Pipeline([('bt',bt),('ridge',Ridge())])>>>basic_pipe.fit(train,y)>>>basic_pipe.score(train,y)0.904
用户也可以使用它进行交叉验证,获得与上面的scikit-learn列转换器流程相似的分数。
>>>cross_val_score(basic_pipe,train,y,cv=kf).mean()0.816
我们也可以将其用作网格搜索的一部分。事实证明,将低频字符串排除在外,并没有明显改善模型的表现,尽管它可以在其他模型中使用。不过,在最佳评分方面确实有所提高,这可能是由于使用了略微不同的编码方案。
>>>param_grid={'bt__cat_threshold':[0,1,2,3,5],'ridge__alpha':[.1,1,10,100]}>>>gs=GridSearchCV(p,param_grid,cv=kf)>>>gs.fit(train,y)>>>gs.best_params_{'bt__cat_threshold':0,'ridge__alpha':10}>>>gs.best_score_0.830
使用新的KBinsDiscretizer对数字列进行分装(bin)和编码
对于包含年份的一些数字列,将其中的值视为类别列更有意义。 Scikit-Learn推出了新的估算器KBinsDiscretizer来实现这一点。它不仅可以存储值,还可以对这些值进行编码。在使用Pandas cut或qcut函数手动完成此这类操作之前,一起来看看它如何处理年份数字列的。
>>>fromsklearn.preprocessingimportKBinsDiscretizer>>>kbd=KBinsDiscretizer(encode='onehot-dense')>>>year_built_transformed=kbd.fit_transform(train[['YearBuilt']])>>>year_built_transformedarray([[0.,0.,0.,0.,1.],[0.,0.,1.,0.,0.],[0.,0.,0.,1.,0.],...,[1.,0.,0.,0.,0.],[0.,1.,0.,0.,0.],[0.,0.,1.,0.,0.]])
在默认设置下,每个bin中都包括相等数量的观察数据。下面对每列求和来验证这一点。
>>>year_built_transformed.sum(axis=0)array([292.,274.,307.,266.,321.])
这就是“分位数策略”,用户可以选择“统一”模式,为bin边界划定相等的空间,也可以选择“k平均”聚类,自定义bin边界。
>>>kbd.bin_edges_array([array([1872.,1947.8,1965.,1984.,2003.,2010.])],dtype=object)
使用列转换器分别处理所有年份列
现在有一个需要单独处理的列子集,我们可以使用列转换器来执行此操作。下面的代码为我们之前的转换添加了一个步骤。此外还删除了标识列,只标识出每一行。
>>>year_cols=['YearBuilt','YearRemodAdd','GarageYrBlt','YrSold']>>>not_year=~np.isin(num_cols,year_cols+['Id'])>>>num_cols2=num_cols[not_year]>>>year_si_step=('si',SimpleImputer(strategy='median'))>>>year_kbd_step=('kbd',KBinsDiscretizer(n_bins=5,encode='onehot-dense'))>>>year_steps=[year_si_step,year_kbd_step]>>>year_pipe=Pipeline(year_steps)>>>transformers=[('cat',cat_pipe,cat_cols),('num',num_pipe,num_cols2),('year',year_pipe,year_cols)]>>>ct=ColumnTransformer(transformers=transformers)>>>X=ct.fit_transform(train)>>>X.shape(1460,320)
通过交叉验证和评分,发现所有这些处理都没有带来任何改进。
>>>ml_pipe=Pipeline([('transform',ct),('ridge',Ridge())])>>>cross_val_score(ml_pipe,train,y,cv=kf).mean()0.813
为每列使用不同数量的bin可能会改善我们的结果。尽管如此,KBinsDiscretizer还可以轻松地对数字变量进行分装。
标题:Scikit-Learn 0.20的更多亮点
本次即将发布的版本附带了更多新功能。更多详细信息,请查看文档的“新增内容”部分。有很多变化哦。
结论
本文介绍了一个新的工作流程,提供了一个基于Pandas进行初步数据探索和准备的Scikit-Learn用户方案。现在,改进型的新估算器ColumnTransformer,SimpleImputer,OneHotEncoder和KBinsDiscretizer,让整个数据处理流程变得更加平滑,功能也更加丰富。用户可以获取Pandas DataFrame,并对其进行转换,为机器学习做好准备。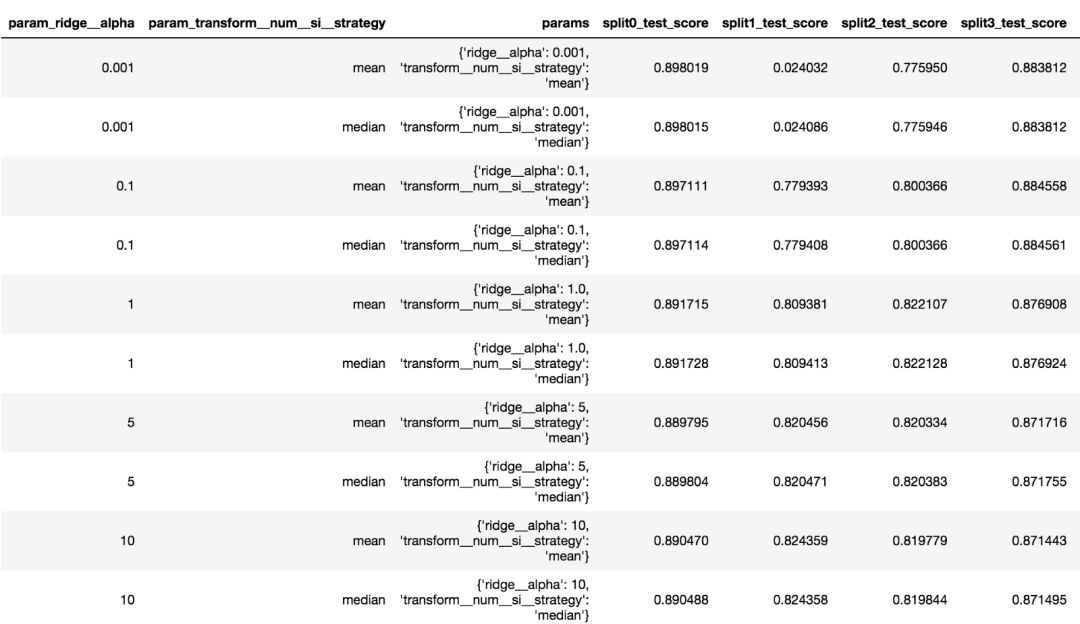

-
机器学习
+关注
关注
66文章
8455浏览量
133186 -
数据分析
+关注
关注
2文章
1462浏览量
34207
原文标题:AI开发最大升级:Pandas与Scikit-Learn合并,新工作流程更简单强大!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Python机器学习库谈Scikit-learn技术
在PyODPS DataFrame自定义函数中使用pandas、scipy和scikit-learn
迅为RK3399开发板人工智能深度学习框架
如何在移动和嵌入式设备上部署机器学习模型
Python机器学习回归部分的应用与教程
基于Python的scikit-learn编程实例
详细解析scikit-learn进行文本分类

机器学习和数据科学必读的10本免费在线电子书和书的详细介绍
用英特尔DAAL性能库加速SCIKIT学习
高性能Python代码工具的介绍
scikit-learn K近邻法类库使用的经验总结





 工商网监
工商网监
评论