 AUC是否可以直接用作损失函数去优化呢?
AUC是否可以直接用作损失函数去优化呢?
引言
CTR问题我们有两种角度去理解,一种是分类的角度,即将点击和未点击作为两种类别。另一种是回归的角度,将点击和未点击作为回归的值。不管是分类问题还是回归问题,一般在预估的时候都是得到一个[0,1]之间的概率值,代表点击的可能性的大小。
如果将CTR预估问题当作回归问题,我们经常使用的损失函数是MSE;如果当作二分类问题,我们经常使用的损失函数是LogLoss。而对于一个训练好的模型,我们往往需要评估一下模型的效果,或者说泛化能力,MSE和LogLoss当然也可以作为我们的评价指标,但除此之外,我们最常用的还是AUC。
想到这里,我想到一个问题,AUC是否可以直接用作损失函数去优化呢?
说了这么多,我们还不知道AUC是什么呢?不着急,我们从二分类的评估指标慢慢说起,提醒一下,本文二分类的类别均为0和1,1代表正例,0代表负例。
1、从二分类评估指标说起
1.1 混淆矩阵
我们首先来看一下混淆矩阵,对于二分类问题,真实的样本标签有两类,我们学习器预测的类别有两类,那么根据二者的类别组合可以划分为四组,如下表所示:

上表即为混淆矩阵,其中,行表示预测的label值,列表示真实label值。TP,FP,FN,TN分别表示如下意思:
TP(true positive):表示样本的真实类别为正,最后预测得到的结果也为正;FP(false positive):表示样本的真实类别为负,最后预测得到的结果却为正;FN(false negative):表示样本的真实类别为正,最后预测得到的结果却为负;TN(true negative):表示样本的真实类别为负,最后预测得到的结果也为负.
可以看到,TP和TN是我们预测准确的样本,而FP和FN为我们预测错误的样本。
1.2 准确率Accruacy
准确率表示的是分类正确的样本数占样本总数的比例,假设我们预测了10条样本,有8条的预测正确,那么准确率即为80%。
用混淆矩阵计算的话,准确率可以表示为:
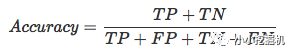
虽然准确率可以在一定程度上评价我们的分类器的性能,不过对于二分类问题或者说CTR预估问题,样本是极其不平衡的。对于大数据集来说,标签为1的正样本数据往往不足10%,那么如果分类器将所有样本判别为负样本,那么仍然可以达到90%以上的分类准确率,但这个分类器的性能显然是非常差的。
1.3 精确率Precision和召回率Recall
为了衡量分类器对正样本的预测能力,我们引入了精确率Precision和召回率Recall。
精确率表示预测结果中,预测为正样本的样本中,正确预测为正样本的概率;召回率表示在原始样本的正样本中,最后被正确预测为正样本的概率;
二者用混淆矩阵计算如下:
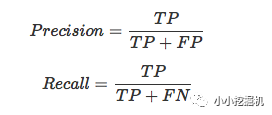
精确率和召回率往往是一对矛盾的指标。在CTR预估问题中,预测结果往往表示会被点击的概率。如果我们对所有的预测结果进行降序排序,排在前面的是学习器认为最可能被点击的样本,排在后面的是学习期认为最不可能被点击的样本。
如果我们设定一个阈值,在这个阈值之上的学习器认为是正样本,阈值之下的学习器认为是负样本。可以想象到的是,当阈值很高时,预测为正样本的是分类器最有把握的一批样本,此时精确率往往很高,但是召回率一般较低。相反,当阈值很低时,分类器把很多拿不准的样本都预测为了正样本,此时召回率很高,但是精确率却往往偏低。
1.4 F-1 Score
为了折中精确率和召回率的结果,我们又引入了F-1 Score,计算公式如下:

对于F1 Score有很多的变化形式,感兴趣的话大家可以参考一下周志华老师的西瓜书,我们这里就不再介绍了。
1.5 ROC与AUC
在许多分类学习器中,产生的是一个概率预测值,然后将这个概率预测值与一个提前设定好的分类阈值进行比较,大于该阈值则认为是正例,小于该阈值则认为是负例。如果对所有的排序结果按照概率值进行降序排序,那么阈值可以将结果截断为两部分,前面的认为是正例,后面的认为是负例。
我们可以根据实际任务的需要选取不同的阈值。如果重视精确率,我们可以设定一个很高的阈值,如果更重视召回率,可以设定一个很低的阈值。
到这里,我们会抛出两个问题:1)设定阈值然后再来计算精确率,召回率和F1-Score太麻烦了,这个阈值到底该设定为多少呢?有没有可以不设定阈值来直接评价我们的模型性能的方法呢?
2)排序结果很重要呀,不管预测值是多少,只要正例的预测概率都大于负例的就好了呀。
没错,ROC和AUC便可以解决我们上面抛出的两个问题。
ROC全称是“受试者工作特征”,(receiver operating characteristic)。我们根据学习器的预测结果进行排序,然后按此顺序逐个把样本作为正例进行预测,每次计算出两个重要的值,分别以这两个值作为横纵坐标作图,就得到了ROC曲线。
这两个指标是什么呢?是精确率和召回率么?并不是的,哈哈。
ROC曲线的横轴为“假正例率”(True Positive Rate,TPR),又称为“假阳率”;纵轴为“真正例率”(False Positive Rate,FPR),又称为“真阳率”,
假阳率,简单通俗来理解就是预测为正样本但是预测错了的可能性,显然,我们不希望该指标太高。
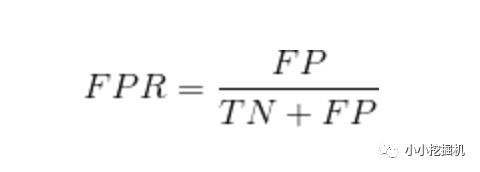
真阳率,则是代表预测为正样本但是预测对了的可能性,当然,我们希望真阳率越高越好。

ROC计算过程如下:1)首先每个样本都需要有一个label值,并且还需要一个预测的score值(取值0到1);2)然后按这个score对样本由大到小进行排序,假设这些数据位于表格中的一列,从上到下依次降序;3)现在从上到下按照样本点的取值进行划分,位于分界点上面的我们把它归为预测为正样本,位于分界点下面的归为负样本;4)分别计算出此时的TPR和FPR,然后在图中绘制(FPR, TPR)点。
说这么多,不如直接看图来的简单:
AUC(area under the curve)就是ROC曲线下方的面积,如下图所示,阴影部分面积即为AUC的值:
AUC量化了ROC曲线表达的分类能力。这种分类能力是与概率、阈值紧密相关的,分类能力越好(AUC越大),那么输出概率越合理,排序的结果越合理。
在CTR预估中,我们不仅希望分类器给出是否点击的分类信息,更需要分类器给出准确的概率值,作为排序的依据。所以,这里的AUC就直观地反映了CTR的准确性(也就是CTR的排序能力)。
终于介绍完了,那么这个值该怎么计算呢?
2、AUC的计算
关于AUC的计算方法,如果仅仅根据上面的描述,我们可能只能想到一种方法,那就是积分法,我们先来介绍这种方法,然后再来介绍其他的方法。
2.1 积分思维
这里的积分法其实就是我们之前介绍的绘制ROC曲线的过程,用代码简单描述下:
auc = 0.0 height = 0.0 for each training example x_i, y_i: if y_i = 1.0: height = height + 1/(tp+fn) else auc += height * 1/(tn+fp) return auc
在上面的计算过程中,我们计算面积过程中隐含着一个假定,即所有样本的预测概率值不想等,因此我们的面积可以由一个个小小的矩形拼起来。但如果有两个或多个的预测值相同,我们调整一下阈值,得到的不是往上或者往右的延展,而是斜着向上形成一个梯形,此时计算梯形的面积就比较麻烦,因此这种方法其实并不是很常用。
2.2 Wilcoxon-Mann-Witney Test
关于AUC还有一个很有趣的性质,它和Wilcoxon-Mann-Witney是等价的,而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。
根据这个定义我们可以来探讨一下二者为什么是等价的?首先我们偷换一下概念,其实意思还是一样的,任意给定一个负样本,所有正样本的score中有多大比例是大于该负类样本的score?由于每个负类样本的选中概率相同,那么Wilcoxon-Mann-Witney Test其实就是上面n2(负样本的个数)个比例的平均值。
那么对每个负样本来说,有多少的正样本的score比它的score大呢?是不是就是当结果按照score排序,阈值恰好为该负样本score时的真正例率TPR?没错,相信你的眼睛,是这样的!理解到这一层,二者等价的关系也就豁然开朗了。ROC曲线下的面积或者说AUC的值 与 测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score
哈哈,那么我们只要计算出这个概率值就好了呀。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是:统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。公式表示如下:
实现这个方法的复杂度为O(n^2 )。n为样本数(即n=M+N)
2.3 Wilcoxon-Mann-Witney Test的化简
该方法和上述第二种方法原理一样,但复杂度降低了。首先对score从大到小排序,然后令最大score对应的sample的rank值为n,第二大score对应sample的rank值为n-1,以此类推从n到1。然后把所有的正类样本的rank相加,再减去正类样本的score为最小的那M个值的情况。得到的结果就是有多少对正类样本的score值大于负类样本的score值,最后再除以M×N即可。值得注意的是,当存在score相等的时候,对于score相等的样本,需要赋予相同的rank值(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。此公式描述如下:
有了这个公式,我们计算AUC就非常简单了,下一节我们会给出一个简单的Demo
3、AUC计算代码示例
这一节,我们给出一个AUC计算的小Demo,供大家参考:
import numpy as np label_all = np.random.randint(0,2,[10,1]).tolist() pred_all = np.random.random((10,1)).tolist() print(label_all) print(pred_all) posNum = len(list(filter(lambda s: s[0] == 1, label_all))) if (posNum > 0): negNum = len(label_all) - posNum sortedq = sorted(enumerate(pred_all), key=lambda x: x[1]) posRankSum = 0 for j in range(len(pred_all)): if (label_all[j][0] == 1): posRankSum += list(map(lambda x: x[0], sortedq)).index(j) + 1 auc = (posRankSum - posNum * (posNum + 1) / 2) / (posNum * negNum) print("auc:", auc)
输出为:
[[1], [1], [1], [1], [0], [0], [1], [0], [1], [0]] [[0.3338126725065774], [0.916003907444231], [0.21214487870979226], [0.7598235037160891], [0.07060830328081447], [0.7650759555141832], [0.16157972737309945], [0.6526480840746645], [0.9327233203035652], [0.6581121768195201]] auc: 0.5833333333333334
-
函数
+关注
关注
3文章
4331浏览量
62604 -
分类器
+关注
关注
0文章
152浏览量
13180 -
数据集
+关注
关注
4文章
1208浏览量
24699
原文标题:推荐系统遇上深度学习(九)--评价指标AUC原理及实践
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
是否可以将彩信图像用作壁纸?
怎样用printf 函数和getchar 函数去简化STM32串口数据的传输呢
如何利用LCD_Color_Fill() 库函数去显示图片呢
三种常见的损失函数和两种常用的激活函数介绍和可视化
基于下界函数的最优化这样一种优化思路

计算机视觉的损失函数是什么?





 工商网监
工商网监
评论