 通过YouTube视频中的图像和声音来训练深度神经网络
通过YouTube视频中的图像和声音来训练深度神经网络

如何从混杂的背景噪音中过滤出特定的声音,这一“经典鸡尾酒会问题”有望在AI的帮助下得以解决。
因为我们的大脑可以专注于想听到的内容,所以人耳可以准确地从嘈杂声中分辨出特定的声音。然而,基于机器的“声源分离”技术多年来却一直让工程师们束手无策。麻省理工学院的研究人员正在利用MV(音乐短片)训练神经网络,以便更好地定位声音来源。
该团队的深度学习系统可以“直接通过一些未经标记的YouTube视频进行学习,分辨出每种物体对应的声音,”麻省理工学院研究人员Hang Zhao说道。他也曾是NVIDIA研究部门的实习生。
Zhao认为,该技术极具突破性,在语音、听力学、音乐和机器人学领域均有广泛的应用。
通过“刷视频”来学习
麻省理工学院开发出了一种新方法,即通过YouTube视频中的图像和声音来训练深度神经网络。他们的目标是让神经网络能够精确定位视频中图像的位置(精确到像素级)。
该团队将其系统称为PixelPlayer,并通过YouTube上的MV对PixelPlayer进行了60个小时的训练。到目前为止,该系统已经可以识别20多种乐器。
该团队在麻省理工学院的计算机科学和人工智能实验室 (Computer Science and Artificial Intelligence Lab) 开展了这项研究,共开发出了三个卷积神经网络,它们可协同工作以生成相应结果。其中一个卷积神经网络负责对视觉输入进行编码,一个负责对音频输入进行编码,第三个则负责基于视觉和音频输入合成输出。
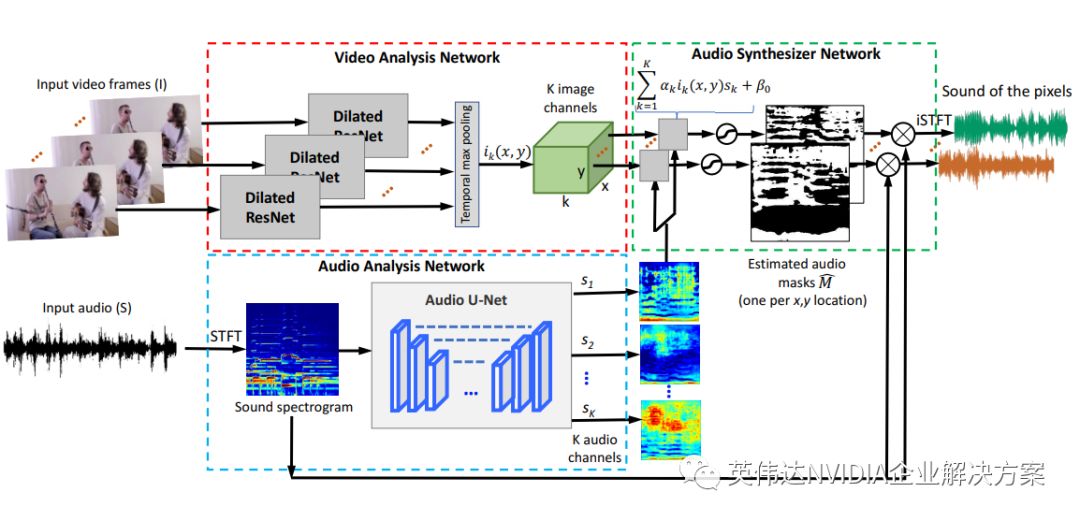
PixelPlayer训练数据集由714个YouTube视频组成。“由于我们使用了四块NVIDIA GPU,卷积神经网络才能够以非常快的速度处理数据,”Zhao表示,“它大约用了一天的时间便学会了。”
PixelPlayer是一个自我监督型(self-supervised)的系统。这意味着该系统不需要人类对乐器或乐器声音进行任何标注,也可以识别出大号和小号等乐器的外观、乐器声音以及发声方式。
吹响胜利的号角
对视频中的声源进行定位后,PixelPlayer即可分离出其波形。目前,PixelPlayer在识别两种或三种不同乐器时表现最佳,但该团队的目标是尽快扩大其识别范围。在谈到分离乐器声音的过程时,Zhao说道:“我们正在努力将一个MP3文件分离为多个MP3文件。”
PixelPlayer在音乐领域有诸多用途。据Zhao介绍,音频工程师可以应用此款AI工具增强某些音量较低的乐器声音,或去除某种背景噪音。此外,它还可以帮助音频工程师改善现场录音或重新灌录音乐的效果。
改善助听器功能也是研究人员为“鸡尾酒会问题”开发深度学习解决方案的目的。
不仅是音乐和听力学领域,其应用范围还可用于识别我们周围的声音。例如,聆听森林中珍稀鸟类的鸣叫声。“机器人也可以借助该系统理解周围环境中的声音。”Zhao补充道。
-
神经网络
+关注
关注
42文章
4842浏览量
108177 -
人工智能
+关注
关注
1820文章
50324浏览量
266937 -
深度学习
+关注
关注
73文章
5607浏览量
124629
原文标题:让音乐更悦耳:AI助力解决“鸡尾酒会问题”
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何训练这些神经网络来解决问题?
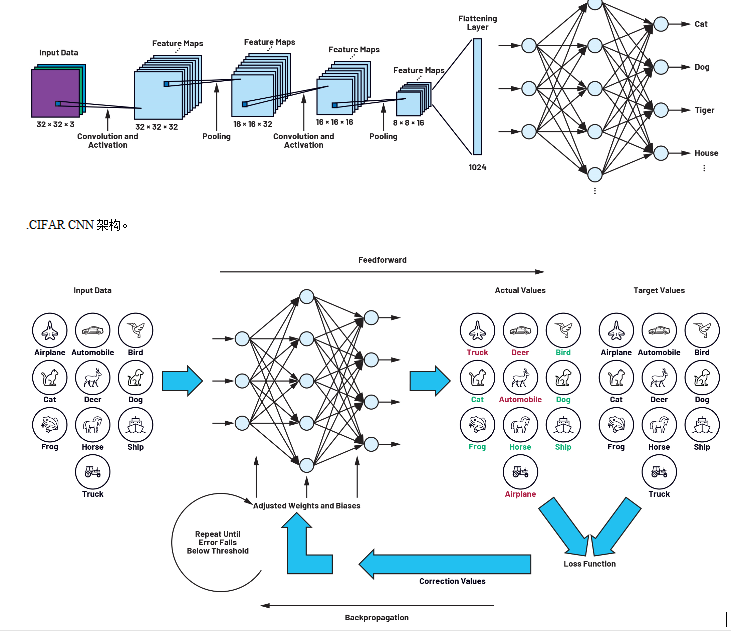
详解深度学习、神经网络与卷积神经网络的应用




评论