 基于DensePose的姿势转换系统,仅根据一张输入图像和目标姿势
基于DensePose的姿势转换系统,仅根据一张输入图像和目标姿势

DensePose团队在ECCV 2018发表又一杰作:密集人体姿态转换!这是一个基于DensePose的姿势转换系统,仅根据一张输入图像和目标姿势,生成数字人物的动画效果。
DensePose是Facebook研究员Natalia Neverova、Iasonas Kokkinos和法国INRIA的Rıza Alp Guler开发的一个令人惊叹的人体实时姿势识别系统,它在2D图像和人体3D模型之间建立映射,最终实现密集人群的实时姿态识别。
具体来说,DensePose利用深度学习将2D RPG图像坐标映射到3D人体表面,把一个人分割成许多UV贴图(UV坐标),然后处理密集坐标,实现动态人物的精确定位和姿态估计。
DensePose模型以及数据集已经开源,传送门:
http://densepose.org/
最近,该团队更进一步,发布了基于DensePose的一个姿势转换系统:Dense Pose Transfer,仅根据一张输入图像和目标姿势,创造出“数字化身”的动画效果。
在这项工作中,研究者希望仅依赖基于表面(surface-based)的对象表示(object representations),类似于在图形引擎中使用的对象表示,来获得对图像合成过程的更强把握。
研究者关注的重点是人体。模型建立在最近的SMPL模型和DensePose系统的基础上,将这两个系统结合在一起,从而能够用完整的表面模型来说明一个人的图像。
具体而言,这项技术是通过surface-based的神经合成,渲染同一个人的不同姿势,从而执行图像生成。目标姿势(target pose)是通过一个“pose donor”的图像表示的,也就是指导图像合成的另一个人。DensePose系统用于将新的照片与公共表面坐标相关联,并复制预测的外观。
我们在DeepFashion和MVC数据集进行了实验,结果表明我们可以获得比最新技术更好的定量结果。
除了姿势转换的特定问题外,所提出的神经合成与surface-based的表示相结合的方法也有希望解决虚拟现实和增强现实的更广泛问题:由于surface-based的表示,合成的过程更加透明,也更容易与物理世界连接。未来,姿势转换任务可能对数据集增强、训练伪造检测器等应用很有用。
Dense Pose Transfer
研究人员以一种高效的、自下而上的方式,将每个人体像素与其在人体参数化的坐标关联起来,开发了围绕DensePose估计系统进行姿势转换的方法。
我们以两种互补的方式利用DensePose输出,对应于预测模块和变形模块(warping module),如图1所示。
图1:pose transfer pipeline的概览:给定输入图像和目标姿势,使用DensePose来执行生成过程。
变形模块使用DensePose表面对应和图像修复(inpainting)来生成人物的新视图,而预测模块是一个通用的黑盒生成模型,以输入和目标的DensePose输出作为条件。
这两个模块具有互补的优点:预测模块成功地利用密集条件输出来为熟悉的姿势生成合理的图像;但它不能推广的新的姿势,或转换纹理细节。
相比之下,变形模块可以保留高质量的细节和纹理,允许在一个统一的、规范的坐标系中进行修复,并且可以自由地推广到各种各样的身体动作。但是,它是以身体为中心的,而不是以衣服为中心,因此没有考虑头发、衣服和配饰。
将这两个模块的输出输入到一个混合模块(blending module)可以得到最好的结果。这个混合模块通过在一个端到端可训练的框架中使用重构、对抗和感知损失的组合,来融合和完善它们的预测。
图2:warping stream上姿势转换的监控信号:通过DensePose驱动的空间变换网络,将左侧的输入图像扭曲到固有的表面坐标。
图3:Warping模块的结果
如图3所示,在修复过程(inpainting process),可以观察到一个均匀的表面,捕捉了皮肤和贴身衣服的外观,但没有考虑头发、裙子或外衣,因为这些不适合DensePose的表面模型。
实验和结果
我们在DeepFashion数据集上进行实验,该数据集包含52712个时装模特图像,13029件不同姿势的服装。我们选择了12029件衣服进行训练,其余1000件用于测试。
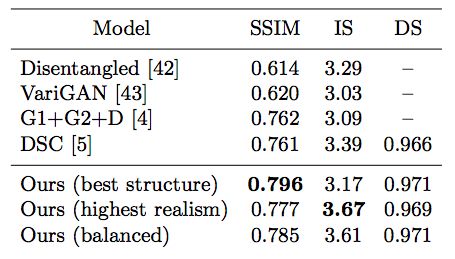
表1:根据结构相似度(SSIM)、Inception Score(IS)[41]和detection score(DS)指标,对DeepFashion数据集的几种state-of-the-art方法进行定量比较。
我们首先将我们的框架与最近一些基于关键点的图像生成或多视图合成方法进行比较。
表1显示,我们的pipeline在结构逼真度(structural fidelity)方面有显著优势。在以IS作为指标的感知质量方面,我们模型的输出生成具有更高的质量,或可与现有工作相媲美。
定性结果如图4所示。
图4:与最先进的Deformable GAN (DSC)方法的定性比较。
密集人体姿态转换应用
在这项工作中,我们介绍了一个利用密集人体姿态估计的two-stream姿态转换架构。我们已经证明,密集姿势估计对于数据驱动的人体姿势估计而言是一种明显优越的调节信号,并且通过inpainting的方法在自然的体表参数化过程中建立姿势转换。在未来的工作中,我们打算进一步探索这种方法在照片级真实图像合成,以及处理更多类别方面的潜力。
作者:
Rıza Alp Güler,INRIA, CentraleSupélec
Natalia Neverova,Facebook AI Research
Iasonas Kokkinos,Facebook AI Research
-
图像
+关注
关注
2文章
1096浏览量
42438 -
深度学习
+关注
关注
73文章
5607浏览量
124624
原文标题:【ECCV 2018】Facebook开发姿态转换模型,只需一张照片就能让它跳舞(视频)
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
电脑鼠姿势矫正
解锁了这些姿势!你就可以嘿!嘿!嘿!
从图像数据中提取非常精准的姿势数据
图像迁移最新成果:人体姿势和舞蹈动作迁移
JD和OPPO的研究人员们提出了一种姿势引导的时尚图像生成模型
华为用机姿势提醒功能详解,可及时提醒用户矫正不当姿势
基于 M5StickV 的错误姿势检测器开源分享

华为新专利可根据凝视姿势解锁设备



评论