 了解Linux默认文件系统的发展历史
了解Linux默认文件系统的发展历史
目前的大部分 Linux 文件系统都默认采用 ext4 文件系统,正如以前的 Linux 发行版默认使用 ext3、ext2 以及更久前的 ext。
对于不熟悉 Linux 或文件系统的朋友而言,你可能不清楚 ext4 相对于上一版本 ext3 带来了什么变化。你可能还想知道在一连串关于替代的文件系统例如 Btrfs、XFS 和 ZFS 不断被发布的情况下,ext4 是否仍然能得到进一步的发展。
在一篇文章中,我们不可能讲述文件系统的所有方面,但我们尝试让你尽快了解 Linux 默认文件系统的发展历史,包括它的诞生以及未来发展。
我仔细研究了维基百科里的各种关于 ext 文件系统文章、kernel.org 的 wiki 中关于 ext4 的条目以及结合自己的经验写下这篇文章。
ext 简史
MINIX 文件系统
在有 ext 之前,使用的是 MINIX 文件系统。如果你不熟悉 Linux 历史,那么可以理解为 MINIX 是用于 IBM PC/AT 微型计算机的一个非常小的类 Unix 系统。Andrew Tannenbaum 为了教学的目的而开发了它,并于 1987 年发布了源代码(以印刷版的格式!)。
IBM 1980 中期的 PC/AT,MBlairMartin,CC BY-SA 4.0
虽然你可以细读 MINIX 的源代码,但实际上它并不是自由开源软件(FOSS)。出版 Tannebaum 著作的出版商要求你花 69 美元的许可费来运行 MINIX,而这笔费用包含在书籍的费用中。尽管如此,在那时来说非常便宜,并且 MINIX 的使用得到迅速发展,很快超过了 Tannebaum 当初使用它来教授操作系统编码的意图。在整个 20 世纪 90 年代,你可以发现 MINIX 的安装在世界各个大学里面非常流行。而此时,年轻的 Linus Torvalds 使用 MINIX 来开发原始 Linux 内核,并于 1991 年首次公布,而后在 1992 年 12 月在 GPL 开源协议下发布。
但是等等,这是一篇以文件系统为主题的文章不是吗?是的,MINIX 有自己的文件系统,早期的 Linux 版本依赖于它。跟 MINIX 一样,Linux 的文件系统也如同玩具那般小 —— MINIX 文件系统最多能处理 14 个字符的文件名,并且只能处理 64MB 的存储空间。到了 1991 年,一般的硬盘尺寸已经达到了 40-140 MB。很显然,Linux 需要一个更好的文件系统。
ext
当 Linus 开发出刚起步的 Linux 内核时,Rémy Card 从事第一代的 ext 文件系统的开发工作。ext 文件系统在 1992 年首次实现并发布 —— 仅在 Linux 首次发布后的一年!—— ext 解决了 MINIX 文件系统中最糟糕的问题。
1992 年的 ext 使用在 Linux 内核中的新虚拟文件系统(VFS)抽象层。与之前的 MINIX 文件系统不同的是,ext 可以处理高达 2 GB 存储空间并处理 255 个字符的文件名。
但 ext 并没有长时间占统治地位,主要是由于它原始的时间戳(每个文件仅有一个时间戳,而不是今天我们所熟悉的有 inode、最近文件访问时间和最新文件修改时间的时间戳。)仅仅一年后,ext2 就替代了它。
ext2
Rémy 很快就意识到 ext 的局限性,所以一年后他设计出 ext2 替代它。当 ext 仍然根植于 “玩具” 操作系统时,ext2 从一开始就被设计为一个商业级文件系统,沿用 BSD 的 Berkeley 文件系统的设计原理。
ext2 提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小,使其在 20 世纪 90 年代的地位牢牢巩固在文件系统大联盟中。很快它被广泛地使用,无论是在 Linux 内核中还是最终在 MINIX 中,且利用第三方模块可以使其应用于 MacOS 和 Windows。
但这里仍然有一些问题需要解决:ext2 文件系统与 20 世纪 90 年代的大多数文件系统一样,如果在将数据写入到磁盘的时候,系统发生崩溃或断电,则容易发生灾难性的数据损坏。随着时间的推移,由于碎片(单个文件存储在多个位置,物理上其分散在旋转的磁盘上),它们也遭受了严重的性能损失。
尽管存在这些问题,但今天 ext2 还是用在某些特殊的情况下 —— 最常见的是,作为便携式 USB 驱动器的文件系统格式。
ext3
1998 年,在 ext2 被采用后的 6 年后,Stephen Tweedie 宣布他正在致力于改进 ext2。这成了 ext3,并于 2001 年 11 月在 2.4.15 内核版本中被采用到 Linux 内核主线中。
20 世纪 90 年代中期的 Packard Bell 计算机,Spacekid,CC0
在大部分情况下,ext2 在 Linux 发行版中工作得很好,但像 FAT、FAT32、HFS 和当时的其它文件系统一样 —— 在断电时容易发生灾难性的破坏。如果在将数据写入文件系统时候发生断电,则可能会将其留在所谓不一致的状态 —— 事情只完成一半而另一半未完成。这可能导致大量文件丢失或损坏,这些文件与正在保存的文件无关甚至导致整个文件系统无法卸载。
ext3 和 20 世纪 90 年代后期的其它文件系统,如微软的 NTFS,使用日志来解决这个问题。日志是磁盘上的一种特殊的分配区域,其写入被存储在事务中;如果该事务完成磁盘写入,则日志中的数据将提交给文件系统自身。如果系统在该操作提交前崩溃,则重新启动的系统识别其为未完成的事务而将其进行回滚,就像从未发生过一样。这意味着正在处理的文件可能依然会丢失,但文件系统本身保持一致,且其它所有数据都是安全的。
在使用 ext3 文件系统的 Linux 内核中实现了三个级别的日志记录方式:日记journal、顺序ordered和回写writeback。
日记是最低风险模式,在将数据和元数据提交给文件系统之前将其写入日志。这可以保证正在写入的文件与整个文件系统的一致性,但其显著降低了性能。
顺序是大多数 Linux 发行版默认模式;顺序模式将元数据写入日志而直接将数据提交到文件系统。顾名思义,这里的操作顺序是固定的:首先,元数据提交到日志;其次,数据写入文件系统,然后才将日志中关联的元数据更新到文件系统。这确保了在发生崩溃时,那些与未完整写入相关联的元数据仍在日志中,且文件系统可以在回滚日志时清理那些不完整的写入事务。在顺序模式下,系统崩溃可能导致在崩溃期间文件的错误被主动写入,但文件系统它本身 —— 以及未被主动写入的文件 —— 确保是安全的。
回写是第三种模式 —— 也是最不安全的日志模式。在回写模式下,像顺序模式一样,元数据会被记录到日志,但数据不会。与顺序模式不同,元数据和数据都可以以任何有利于获得最佳性能的顺序写入。这可以显著提高性能,但安全性低很多。尽管回写模式仍然保证文件系统本身的安全性,但在崩溃或崩溃之前写入的文件很容易丢失或损坏。
跟之前的 ext2 类似,ext3 使用 16 位内部寻址。这意味着对于有着 4K 块大小的 ext3 在最大规格为 16 TiB 的文件系统中可以处理的最大文件大小为 2 TiB。
ext4
Theodore Ts’o(是当时 ext3 主要开发人员)在 2006 年发表的 ext4,于两年后在 2.6.28 内核版本中被加入到了 Linux 主线。
Ts’o 将 ext4 描述为一个显著扩展 ext3 但仍然依赖于旧技术的临时技术。他预计 ext4 终将会被真正的下一代文件系统所取代。
Dell Precision 380 工作站,Lance Fisher,CC BY-SA 2.0
ext4 在功能上与 ext3 在功能上非常相似,但支持大文件系统,提高了对碎片的抵抗力,有更高的性能以及更好的时间戳。
ext4 vs ext3
ext3 和 ext4 有一些非常明确的差别,在这里集中讨论下。
向后兼容性
ext4 特地设计为尽可能地向后兼容 ext3。这不仅允许 ext3 文件系统原地升级到 ext4;也允许 ext4 驱动程序以 ext3 模式自动挂载 ext3 文件系统,因此使它无需单独维护两个代码库。
大文件系统
ext3 文件系统使用 32 位寻址,这限制它仅支持 2 TiB 文件大小和 16 TiB 文件系统系统大小(这是假设在块大小为 4 KiB 的情况下,一些 ext3 文件系统使用更小的块大小,因此对其进一步被限制)。
ext4 使用 48 位的内部寻址,理论上可以在文件系统上分配高达 16 TiB 大小的文件,其中文件系统大小最高可达 1000000 TiB(1 EiB)。在早期 ext4 的实现中有些用户空间的程序仍然将其限制为最大大小为 16 TiB 的文件系统,但截至 2011 年,e2fsprogs 已经直接支持大于 16 TiB 大小的 ext4 文件系统。例如,红帽企业 Linux 在其合同上仅支持最高 50 TiB 的 ext4 文件系统,并建议 ext4 卷不超过 100 TiB。
分配方式改进
ext4 在将存储块写入磁盘之前对存储块的分配方式进行了大量改进,这可以显著提高读写性能。
区段
区段extent是一系列连续的物理块 (最多达 128 MiB,假设块大小为 4 KiB),可以一次性保留和寻址。使用区段可以减少给定文件所需的 inode 数量,并显著减少碎片并提高写入大文件时的性能。
多块分配
ext3 为每一个新分配的块调用一次块分配器。当多个写入同时打开分配器时,很容易导致严重的碎片。然而,ext4 使用延迟分配,这允许它合并写入并更好地决定如何为尚未提交的写入分配块。
持久的预分配
在为文件预分配磁盘空间时,大部分文件系统必须在创建时将零写入该文件的块中。ext4 允许替代使用fallocate(),它保证了空间的可用性(并试图为它找到连续的空间),而不需要先写入它。这显著提高了写入和将来读取流和数据库应用程序的写入数据的性能。
延迟分配
这是一个耐人寻味而有争议性的功能。延迟分配允许 ext4 等待分配将写入数据的实际块,直到它准备好将数据提交到磁盘。(相比之下,即使数据仍然在往写入缓存中写入,ext3 也会立即分配块。)
当缓存中的数据累积时,延迟分配块允许文件系统对如何分配块做出更好的选择,降低碎片(写入,以及稍后的读)并显著提升性能。然而不幸的是,它增加了还没有专门调用fsync()方法(当程序员想确保数据完全刷新到磁盘时)的程序的数据丢失的可能性。
假设一个程序完全重写了一个文件:
fd=open("file", O_TRUNC); write(fd, data); close(fd);
使用旧的文件系统,close(fd); 足以保证 file 中的内容刷新到磁盘。即使严格来说,写不是事务性的,但如果文件关闭后发生崩溃,则丢失数据的风险很小。
如果写入不成功(由于程序上的错误、磁盘上的错误、断电等),文件的原始版本和较新版本都可能丢失数据或损坏。如果其它进程在写入文件时访问文件,则会看到损坏的版本。如果其它进程打开文件并且不希望其内容发生更改 —— 例如,映射到多个正在运行的程序的共享库。这些进程可能会崩溃。
为了避免这些问题,一些程序员完全避免使用 O_TRUNC。相反,他们可能会写入一个新文件,关闭它,然后将其重命名为旧文件名:
fd=open("newfile"); write(fd, data); close(fd); rename("newfile", "file");
在 没有 延迟分配的文件系统下,这足以避免上面列出的潜在的损坏和崩溃问题:因为 rename() 是原子操作,所以它不会被崩溃中断;并且运行的程序将继续引用旧的文件。现在 file 的未链接版本只要有一个打开的文件文件句柄即可。但是因为 ext4 的延迟分配会导致写入被延迟和重新排序,rename("newfile", "file") 可以在 newfile 的内容实际写入磁盘内容之前执行,这出现了并行进行再次获得 file 坏版本的问题。
为了缓解这种情况,Linux 内核(自版本 2.6.30)尝试检测这些常见代码情况并强制立即分配。这会减少但不能防止数据丢失的可能性 —— 并且它对新文件没有任何帮助。如果你是一位开发人员,请注意:保证数据立即写入磁盘的唯一方法是正确调用 fsync()。
无限制的子目录
ext3 仅限于 32000 个子目录;ext4 允许无限数量的子目录。从 2.6.23 内核版本开始,ext4 使用 HTree 索引来减少大量子目录的性能损失。
日志校验
ext3 没有对日志进行校验,这给处于内核直接控制之外的磁盘或自带缓存的控制器设备带来了问题。如果控制器或具自带缓存的磁盘脱离了写入顺序,则可能会破坏 ext3 的日记事务顺序,从而可能破坏在崩溃期间(或之前一段时间)写入的文件。
理论上,这个问题可以使用写入障碍barrier —— 在安装文件系统时,你在挂载选项设置 barrier=1,然后设备就会忠实地执行 fsync 一直向下到底层硬件。通过实践,可以发现存储设备和控制器经常不遵守写入障碍 —— 提高性能(和跟竞争对手比较的性能基准),但增加了本应该防止数据损坏的可能性。
对日志进行校验和允许文件系统崩溃后第一次挂载时意识到其某些条目是无效或无序的。因此,这避免了回滚部分条目或无序日志条目的错误,并进一步损坏的文件系统 —— 即使部分存储设备假做或不遵守写入障碍。
快速文件系统检查
在 ext3 下,在 fsck 被调用时会检查整个文件系统 —— 包括已删除或空文件。相比之下,ext4 标记了 inode 表未分配的块和扇区,从而允许 fsck 完全跳过它们。这大大减少了在大多数文件系统上运行 fsck 的时间,它实现于内核 2.6.24。
改进的时间戳
ext3 提供粒度为一秒的时间戳。虽然足以满足大多数用途,但任务关键型应用程序经常需要更严格的时间控制。ext4 通过提供纳秒级的时间戳,使其可用于那些企业、科学以及任务关键型的应用程序。
ext3 文件系统也没有提供足够的位来存储 2038 年 1 月 18 日以后的日期。ext4 在这里增加了两个位,将 Unix 纪元扩展了 408 年。如果你在公元 2446 年读到这篇文章,你很有可能已经转移到一个更好的文件系统 —— 如果你还在测量自 1970 年 1 月 1 日 00:00(UTC)以来的时间,这会让我死后得以安眠。
在线碎片整理
ext2 和 ext3 都不直接支持在线碎片整理 —— 即在挂载时会对文件系统进行碎片整理。ext2 有一个包含的实用程序 e2defrag,它的名字暗示 —— 它需要在文件系统未挂载时脱机运行。(显然,这对于根文件系统来说非常有问题。)在 ext3 中的情况甚至更糟糕 —— 虽然 ext3 比 ext2 更不容易受到严重碎片的影响,但 ext3 文件系统运行 e2defrag 可能会导致灾难性损坏和数据丢失。
尽管 ext3 最初被认为“不受碎片影响”,但对同一文件(例如 BitTorrent)采用大规模并行写入过程的过程清楚地表明情况并非完全如此。一些用户空间的手段和解决方法,例如 Shake,以这样或那样方式解决了这个问题 —— 但它们比真正的、文件系统感知的、内核级碎片整理过程更慢并且在各方面都不太令人满意。
ext4 通过 e4defrag 解决了这个问题,且是一个在线、内核模式、文件系统感知、块和区段级别的碎片整理实用程序。
正在进行的 ext4 开发
ext4,正如 Monty Python 中瘟疫感染者曾经说过的那样,“我还没死呢!”虽然它的主要开发人员认为它只是一个真正的下一代文件系统的权宜之计,但是在一段时间内,没有任何可能的候选人准备好(由于技术或许可问题)部署为根文件系统。
在未来的 ext4 版本中仍然有一些关键功能要开发,包括元数据校验和、一流的配额支持和大分配块。
元数据校验和
由于 ext4 具有冗余超级块,因此为文件系统校验其中的元数据提供了一种方法,可以自行确定主超级块是否已损坏并需要使用备用块。可以在没有校验和的情况下,从损坏的超级块恢复 —— 但是用户首先需要意识到它已损坏,然后尝试使用备用方法手动挂载文件系统。由于在某些情况下,使用损坏的主超级块安装文件系统读写可能会造成进一步的损坏,即使是经验丰富的用户也无法避免,这也不是一个完美的解决方案!
与 Btrfs 或 ZFS 等下一代文件系统提供的极其强大的每块校验和相比,ext4 的元数据校验和的功能非常弱。但它总比没有好。虽然校验 所有的事情 都听起来很简单!—— 事实上,将校验和与文件系统连接到一起有一些重大的挑战;请参阅设计文档了解详细信息。
一流的配额支持
等等,配额?!从 ext2 出现的那天开始我们就有了这些!是的,但它们一直都是事后的添加的东西,而且它们总是犯傻。这里可能不值得详细介绍,但设计文档列出了配额将从用户空间移动到内核中的方式,并且能够更加正确和高效地执行。
大分配块
随着时间的推移,那些讨厌的存储系统不断变得越来越大。由于一些固态硬盘已经使用 8K 硬件块大小,因此 ext4 对 4K 模块的当前限制越来越受到限制。较大的存储块可以显著减少碎片并提高性能,代价是增加“松弛”空间(当你只需要块的一部分来存储文件或文件的最后一块时留下的空间)。
你可以在设计文档中查看详细说明。
ext4 的实际限制
ext4 是一个健壮、稳定的文件系统。如今大多数人都应该在用它作为根文件系统,但它无法处理所有需求。让我们简单地谈谈你不应该期待的一些事情 —— 现在或可能在未来:
虽然 ext4 可以处理高达 1 EiB 大小(相当于 1,000,000 TiB)大小的数据,但你 真的 不应该尝试这样做。除了能够记住更多块的地址之外,还存在规模上的问题。并且现在 ext4 不会处理(并且可能永远不会)超过 50-100 TiB 的数据。
ext4 也不足以保证数据的完整性。随着日志记录的重大进展又回到了 ext3 的那个时候,它并未涵盖数据损坏的许多常见原因。如果数据已经在磁盘上被破坏 —— 由于故障硬件,宇宙射线的影响(是的,真的),或者只是数据随时间衰减 —— ext4 无法检测或修复这种损坏。
基于上面两点,ext4 只是一个纯 文件系统,而不是存储卷管理器。这意味着,即使你有多个磁盘 —— 也就是奇偶校验或冗余,理论上你可以从 ext4 中恢复损坏的数据,但无法知道使用它是否对你有利。虽然理论上可以在不同的层中分离文件系统和存储卷管理系统而不会丢失自动损坏检测和修复功能,但这不是当前存储系统的设计方式,并且它将给新设计带来重大挑战。
备用文件系统
在我们开始之前,提醒一句:要非常小心,没有任何备用的文件系统作为主线内核的一部分而内置和直接支持!
即使一个文件系统是 安全的,如果在内核升级期间出现问题,使用它作为根文件系统也是非常可怕的。如果你没有充分的理由通过一个 chroot 去使用替代介质引导,耐心地操作内核模块、grub 配置和 DKMS……不要在一个很重要的系统中去掉预留的根文件。
可能有充分的理由使用你的发行版不直接支持的文件系统 —— 但如果你这样做,我强烈建议你在系统启动并可用后再安装它。(例如,你可能有一个 ext4 根文件系统,但是将大部分数据存储在 ZFS 或 Btrfs 池中。)
XFS
XFS 与非 ext 文件系统在 Linux 中的主线中的地位一样。它是一个 64 位的日志文件系统,自 2001 年以来内置于 Linux 内核中,为大型文件系统和高度并发性提供了高性能(即大量的进程都会立即写入文件系统)。
从 RHEL 7 开始,XFS 成为 Red Hat Enterprise Linux 的默认文件系统。对于家庭或小型企业用户来说,它仍然有一些缺点 —— 最值得注意的是,重新调整现有 XFS 文件系统是一件非常痛苦的事情,不如创建另一个并复制数据更有意义。
虽然 XFS 是稳定的且是高性能的,但它和 ext4 之间没有足够具体的最终用途差异,以值得推荐在非默认(如 RHEL7)的任何地方使用它,除非它解决了对 ext4 的特定问题,例如大于 50 TiB 容量的文件系统。
XFS 在任何方面都不是 ZFS、Btrfs 甚至 WAFL(一个专有的 SAN 文件系统)的“下一代”文件系统。就像 ext4 一样,它应该被视为一种更好的方式的权宜之计。
ZFS
ZFS 由 Sun Microsystems 开发,以 zettabyte 命名 —— 相当于 1 万亿 GB —— 因为它理论上可以解决大型存储系统。
作为真正的下一代文件系统,ZFS 提供卷管理(能够在单个文件系统中处理多个单独的存储设备),块级加密校验和(允许以极高的准确率检测数据损坏),自动损坏修复(其中冗余或奇偶校验存储可用),快速异步增量复制,内联压缩等,以及更多。
从 Linux 用户的角度来看,ZFS 的最大问题是许可证问题。ZFS 许可证是 CDDL 许可证,这是一种与 GPL 冲突的半许可的许可证。关于在 Linux 内核中使用 ZFS 的意义存在很多争议,其争议范围从“它是 GPL 违规”到“它是 CDDL 违规”到“它完全没问题,它还没有在法庭上进行过测试。”最值得注意的是,自 2016 年以来 Canonical 已将 ZFS 代码内联在其默认内核中,而且目前尚无法律挑战。
此时,即使我作为一个非常狂热于 ZFS 的用户,我也不建议将 ZFS 作为 Linux 的根文件系统。如果你想在 Linux 上利用 ZFS 的优势,用 ext4 设置一个小的根文件系统,然后将 ZFS 用在你剩余的存储上,把数据、应用程序以及你喜欢的东西放在它上面 —— 但把 root 分区保留在 ext4 上,直到你的发行版明确支持 ZFS 根目录。
Btrfs
Btrfs 是 B-Tree Filesystem 的简称,通常发音为 “butter” —— 由 Chris Mason 于 2007 年在 Oracle 任职期间发布。Btrfs 旨在跟 ZFS 有大部分相同的目标,提供多种设备管理、每块校验、异步复制、直列压缩等,还有更多。
截至 2018 年,Btrfs 相当稳定,可用作标准的单磁盘文件系统,但可能不应该依赖于卷管理器。与许多常见用例中的 ext4、XFS 或 ZFS 相比,它存在严重的性能问题,其下一代功能 —— 复制、多磁盘拓扑和快照管理 —— 可能非常多,其结果可能是从灾难性地性能降低到实际数据的丢失。
Btrfs 的维持状态是有争议的;SUSE Enterprise Linux 在 2015 年采用它作为默认文件系统,而 Red Hat 于 2017 年宣布它从 RHEL 7.4 开始不再支持 Btrfs。可能值得注意的是,该产品支持 Btrfs 部署用作单磁盘文件系统,而不是像 ZFS 中的多磁盘卷管理器,甚至 Synology 在它的存储设备使用 Btrfs,但是它在传统 Linux 内核 RAID(mdraid)之上分层来管理磁盘。
-
Linux
+关注
关注
87文章
11385浏览量
211690 -
文件系统
+关注
关注
0文章
293浏览量
20119
原文标题:深入理解 ext4 等 Linux 文件系统
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于Buildroot的Linux系统构建之根文件系统

文件系统是什么?浅谈EXT文件系统历史

Linux 内核/sys 文件系统介绍
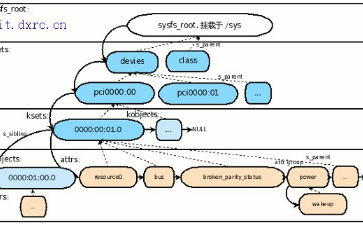
可以了解的Linux 文件系统结构
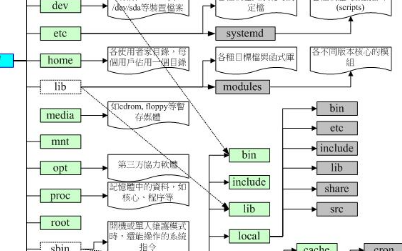
需要了解Linux文件系统发展的前景
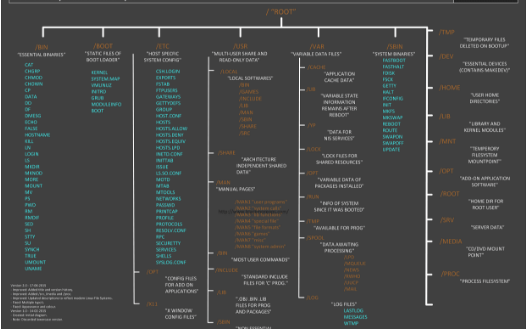
Linux文件系统解析
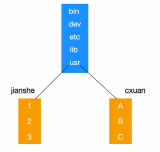
Linux 文件系统层的主要结构
适用于Linux的最佳通用文件系统 Linux文件系统的安装

Linux的文件系统特点
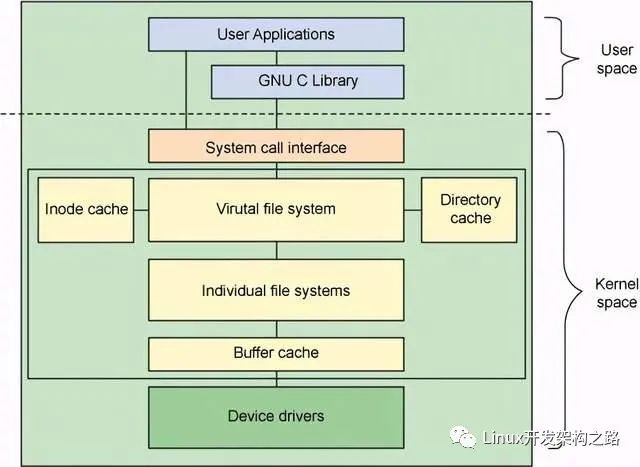
Linux文件系统层的主要结构





 工商网监
工商网监
评论