 详细分析SLAM的实现和应用
详细分析SLAM的实现和应用
本期主讲人为速感科技CTO张一茗,毕业于北航,师从中国惯性技术领域的著名专家冯培德院士,多年组合导航定位系统研究经验,为资深SLAM研究员,学术研究上发表多篇相关领域论文。
今天和大家探讨的是视觉SLAM技术的一些现状和应用的趋势。
大概从几个方面来讲一下SLAM的实现和应用:第一个是从传感器的角度,第二个是从算法实现的角度,第三个是从搭载硬件传感器平台上来说这些问题。
首先介绍下速感科技,我们2014年成立,在国内算是最早做SLAM相关AI技术应用的一个团队,专注于机器视觉人工智能在实际消费类和工业类产品中的应用,整合了一套定位、导航、路径规划、场景感知的算法。
传感器的角度
首先,现在深度传感器或者摄像头种类非常繁多,这里简单列了一下我所了解的深度摄像头的一些路线对比。
从大类上可以分成三种:两种带主动光源——带结构光的摄像头和飞行时间法的摄像头;还有一种是基于多目的被动光深度摄像头。
结构光实际上历史悠久的一种方案,像精度比较高的有投影光栅相位法、动态编码结构光的方法,还有单目结构光、双目结构光、扫描式结构光等等,它们各有各的优缺点。
在高精度测量上,很多人偏向用投影光栅相位法或者动态编码结构光的方式,比如说动态编码结构光,它会将6个或12个有不同编码相位的Pattern投射到被测物体上面,然后用两个摄像头捕捉被投物体表面的纹理变化,再通过相位的计算,来计算出相当高精度的深度信息。
这种深度信息精度大概能够达到微米级,但是成本相对来说也会比较高,有两个原因:一是对投影仪光机要求高一些;另一个是对摄像头分辨率和镜头要求比较高,在消费类里大家一般不会使用这么高精度的方式。
另外一种方法是投影光栅相位法,与动态编码结构光相比更加简单,比如说非常有名的傅里叶变换轮廓术的方式。
除此之外还有单目结构光,最近特别火的iPhoneX中采用的就是单目结构光的方案。
还有成本相对比较低,精度比较适宜的双目结构光,目前广泛应用在各种各样的机器人上。
还有扫描结构光,它的精度比较高,成本也相对可控,比较适合在工业产品上使用的,有的是线扫描,有的是点扫描,而且可以达到相对比较高的精度。
像Google和联想合作的Phab2 Pro的Tango手机,背后用的PMD家的Time of Flight摄像头,在很多工业领域,像雷达,是用飞行时间法获得深度信息,叫飞行时间法。
最后一种就是被动的双目。
算法实现的角度
三角法
先说一下三角法的法则。
三角法的本质是一个解三角形的数学问题。
左侧是一个比较有名的专利,是国外一家做清洁机器人公司在激光雷达上申请的一个专利。
这个专利描述的几个基本点是:首先它有一个旋转轴,带着一个旋转平台,上面有一个光源,有一个传感器,然后有一个处理器,光源向外发射一个准直的激光点,通过透镜在传感器的CMOS上成像。
因为三角法的原理,导致障碍物越近在CMOS上的成像越偏左侧,利用这种原理能够测出跟被测点的距离信息,然后让这个旋转轴高速旋转,就可以获得一个360度连续的深度信息。
这个方法在当年来看是非常有创意的一个想法,也是被大家广泛接受的一个雷达设计方式。但是有一点,这个雷达设计方式依然处在专利保护期范围内,所以有一点比较危险:当量特别大时候会有一定的专利问题。
非三角测量
后面这种叫非三角测量,它是基于飞行时间法(Time of Flight)的激光雷达设计逻辑,飞行时间法的设计逻辑简单来说就是打出一束光,光在空间中前进时需要时间,大概是30,000km/s,通过计算光的飞行时间,解算出往返的距离,最终得到被测点到探测物体的距离信息,这是它的基本逻辑。
右侧有两个图,代表着ToF(Time of Flight)雷达的两种技术流派,它们的本质都是有一颗光源向外打出一个时间调制的光脉冲,然后反射回来,但是大家持有不同的光路和专利。
像右上角这个图,它采用的逻辑是用更小的发散孔径,打到被测物体上,反射的时候有个凹面镜,凹面镜将发散的光斑汇聚在下方的APT二极管上,采集高灵敏度的光飞行时间,最终就能够得到那一点的距离信息。
右下方的雷达,实际上是采用同心光路的一个逻辑,它旋转的是平面度非常高的一面镜子,这个镜子旋转的时候把下方的光源以及接收器做了光路的重叠和反射,让这个光路的设计在体积上更瘦一些。但是这样会浪费透镜的一部分有效空间,所以效率会相对较低。
目前基于飞行时间法的激光雷达主要是这两种基本逻辑。
深度图测量方法
这幅图是一种精度相对比较高的深度图测量方法,也就是傅里叶变换轮廓术的方式,它的逻辑是向被测物体投射出一系列条纹状的Pattern。
这个Pattern有一些特点,它在横向上光强是以正弦波的方式在空间中存在的,看起来就和双缝衍射的逻辑差不多,投射出这个Pattern后,会在空间中形成一个主频,这个主频也跟背景噪声有关。
用傅里叶变换的方式把被射物体的照片拍摄下来,分析出其中的主频,把噪声剔除掉,最终计算每个点理论和实际的一个相位差,就可以得到一个深度信息。
相对来说还是有很多好处。深度图的分辨率可以做得很高,因为每个相位点上都可以提供一些有效的信息,但是对比苹果iPhone X的这种方法,它其实投射的并不是干涉条纹的Pattern,而是点Pattern。
优点是更小的体积,更好的功耗控制,在亮光下效果更好,缺点是深度图的稠密度不是特别高,但是对于手机来说是无所谓的,因为它不需要做一个特别高精度特别稠密的深度图,所以也是够用的。
这里是Apple的TrueDepth专利里的一些内容,比如它采用84°FOV的摄像头来捕捉中间这幅图里的点Pattern,这是Apple 2013年收购Prime sense买的专利,并基于这个专利做了一个改进,实现了一个效果很不错的深度图采集。
当时为了使这个深度摄像头有更好的成像效果,他们还针对光源、光路、DOE做了很多特定的设计,比如采用垂直面枪的激光发射器,它能够在温度发生变化的时候具有更好的温漂表现,一度大概只漂零点零几个纳米,因为光学的东西特别怕折射率发生了变化,如果频率发生了变化,之前标定好的一些Pattern都会失效,所以它用VCSEL(Vertical Cavity Suface Emitting Laser)光源的方式将Projector投射出来的结构光更加稳定,而且它还利用反射镜的方式,在不增加手机厚度的情况下增加了整个光程,就是隐形地将整个焦距拉大,这样投射出去的效果也会更好一些。
基于线的测量
刚刚说了两种深度摄像头,一个是基于相位法的,一个是基于点阵法的,其实还有一些基于线的。
比如SICK公司的一个叫RULER的产品,它的逻辑是有一颗摄像头,还有线激光,但是它的线激光会打到一个旋转的镜子上,通过镜子的旋转,使线激光反射到空间中不同的位置。
当镜子旋转一圈的时候,这个线激光也可以在空间中进行一次扫描,摄像头会连续拍下很多张照片,通过将这些图片得到的深度信息进行叠加可以得到一个精度很高的三维图形。这种方法在工业分拣、工业深度检测的一些领域得到了很多应用,也是一种特别有创意的用法。
还有其他与之类似的逻辑,比如RealSense当年出的R200的逻辑,也是利用了一面镜子,只不过这面镜子有点特殊,它是利用MEMS工艺制作出来的镜子,和TI的DLP一样,其实是使用微机电系统搭建了一个非常非常小的镜子放在硅基的芯片上,然后两边的谐振梁进行弯曲,控制镜子的反射角度,然后它旁边有一个激光器,时刻往镜子上打一个点激光,这个镜子被控制成一个非常高频的调制模式,就像老式电视CRT的那个被投,迅速进行行列扫描,再在空间中投射出一个点状的Pattern,被摄像头采集到之后就可以解算出一个有用的深度信息。
这个最大的好处是能节省很大的体积,因为它不需要透镜,在很多光源下的效率上也会高一些。
基于双目结构光的深度摄像头
然后是现在机器人上用的比较多的方式:基于双目结构光的深度摄像头。
据说苹果接下来采用的也是这种技术,它的基本逻辑和单目结构光差不多,只不过多了一个摄像头,但是有很多好处:首先是没有专利问题,其次是对产品的良率要求比较低,因为单目结构光是相当于利用点阵投射器,在摄像头之间进行了一个三角测量。
但是双目摄像头实际上是利用两颗摄像头和被射物体点进行深度测量,这里最大的差别就在于将投射器和光源的标定要求降低了很多,不需要在生产的时候进行繁琐的标定以及不需要对光源提出这么高的要求,可以用更低的生产成本生产出这个深度摄像头,而且它有一个非常可观的深度图效果。
左侧两幅比较黑的图像分别是左侧摄像头和右侧摄像头看到的红外波段的图像,右侧这副是两颗摄像头合并出来的深度图,可以看到它的效果是相当理想的。
基于面阵摄像头
再一种就像大疆Spark飞机上用的TIme of Flight基于面阵摄像头,有基于相位法的,有脉冲法的,核心逻辑跟雷达是一样的,投射出一个面状的光源,测量不同点的反射光程差,然后测量距离。
这也是一种聪明的方法,它可以用更低的标定成本来实现整个摄像头的生产。
以ZED为例,它做了一个被动的双目摄像头,这种摄像头相对来说很简单很容易做,但是有个缺陷,就是特别怕没有纹理或者有重复纹理的情况,对于白墙、棋盘格这种类似的东西特别敏感,而且需要一个算力相对比较强的上位机来进行深度图的解算,也算是一个比较耗算力的计算方式,但是它应该是所有设计方案中成本最低的一种。
其他传感器
为了实现整套SLAM,除了摄像头以外,其他传感器也是特别关键的,比如说IMU(Inertial Measurement Unit),主要由陀螺仪和加速器构成。
对于陀螺仪来说,它是非常有用的一种器件,精度变化范围特别大,像手机里面用的这种陀螺仪,一般是180°/小时的零偏稳定性,但是精度比较高的一些地方,比如在工业领域用小直径的光学陀螺,它可以达到大约1°/小时的精度,导弹上用的通常是零点几度/小时,洲际战略导弹大概会用百分之一以下甚至千分之几的零偏稳定性。
现在有很多人在研究原子陀螺这种方式,利用原子干涉效应可以达到十的负八次方的精度,这是相当可观的。
如果按照这个精度来算,一个纯靠惯性器件计算微距离的设备,连续使用它两年,它定位的误差也才达到几米。
但是陀螺仪有很多弊端,比如零偏、噪声的问题,它的误差是会累积的,这个也是需要在算法里做一些互补融合。
加速度计也是里面一种关键的器件,它的特点和人的感受其实略有不同,它只能测量表面力,所以它默认输出量里会包含重力加速度,这是一个比较麻烦的事情,所以大家通常会认为加速度计的直接输出量叫比力,而不叫加速度,因为它并不代表绝对的加速度,它的公式为
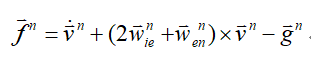
这里的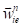 是地球自然角速度,
是地球自然角速度, 是当前物体相对于地球的经纬度,这是因为当一个物体在地球上运动的时候,它其实是一个有向心加速度的现象,所以一个物体在地球表面运动的时候会产生一定的加速度,干扰到它的存在。
是当前物体相对于地球的经纬度,这是因为当一个物体在地球上运动的时候,它其实是一个有向心加速度的现象,所以一个物体在地球表面运动的时候会产生一定的加速度,干扰到它的存在。
这里的原理其实还挺多的,比如摆式积分式、振弦式、振梁式的等等,目前来说精度比较高的还是这种压电式的加速度计,因为加速度计它会带来二阶导的误差,所以大家并不在意它的误差,但这是相比陀螺仪来说,因为陀螺仪的误差相比它来说要多一阶积分,所以陀螺仪的精度更被大家所看重。
大家在实际用的时候,通常会特别在意IMU的一些特性,比如它的标度因数误差,就是它的刻度系数误差,比如MEMS工艺的IMU,其实很难保证每个轴都是完全正交的,这个就需要标定出非正交性的一些误差,零偏是一个最基本的误差,还有温度漂移的误差。
温漂误差相对来说更加可怕一些,首先对于MEMS器件,它的温漂一致性特别差,同一个批次的,比如说飞机上的MPU-6050,它本身的精度还不错,可能非正交性误差等等其他一致性还不错,但是同一批次不同芯片,它的温漂一致性会差别特别大,甚至升温形成或者降温形成整个过程,它的温漂也是不一样的,比如这块IMU放在手机里面,用户在使用的时候芯片会发热,温度升高的时候,它的零偏是逐渐变化的,这个时候它的差别就特别大,这个时候就需要大家能够动态估计这些器件的一个误差,才能够做到一个更好的补偿。
SLAM技术的崛起和发展
单目SLAM和多目SLAM
目前主流的SLAM还是希望用视觉和惯性器件来做这个组合,大家用得比较多的也是单目SLAM和多目SLAM两条主线。
单目SLAM相对来说,它的优势是体积可以做得特别小,成本很低,基本上一个主芯片、一个摄像头、一个IMU就可以把一个东西给做出来,但是有个致命的缺点,就是没有尺度的这个问题。虽然这个问题现在来说可以解决了,但是通常它还是没有双目SLAM那么准。
还有一个问题就是,在一个陌生区域做原地旋转的时候,它会造成尺度无法确立的问题。它也有一些解法,但是这个问题相对来说比较难解决,对算法的挑战要更高。
对于双目或者多目SLAM来说,因为它是两个摄像头经过事先的标定,它知道自己的两个眼睛的差距有多大,所以从鲁棒性和稳定性来说其实要更好一些,但是缺点就是对计算的要求更高,对于性能要求比较高的场合,用双目或多目摄像头更合适一些,比如HoloLens就很明智地选择四颗小视场角的摄像头的这种方式来进行SLAM定位,这能保证它在更多场景下定位不出问题。
雷达SLAM
雷达SLAM就不多讲了,推荐一个比较有名的论文,是基于雷达、惯性器件、卫星导航设备(GNSS)来做的一个组合融合,现在目前来说用RTK这种卫星导航的方式可以做到一个厘米级的定位精度,前提是在没有太多的多径干扰、遮挡比较少的情况下。
这是一个相对来说比较有效的模型,它的前提是需要尽可能事先建立一个场景的三维地图。要能够提高它的匹配精度,应该在室外无人驾驶中用得比较多。
目前的SLAM也在朝着传统的纯建模和深度学习组合的方式在前进,这也是大家的一个共识,怎么把这个事情融合到一块还是有很多的学问。
比如说这幅图里面,首先它会分支出几条不同的线,一条线是在定位丢失的情况下做一个重定位,另外一条线是用来更新神经网络模型,然后进行标注,最终形成一个场景语义地图。同时也会用传统的方式,将图像送到SLAM中进行位置姿态的估计,其中会有很多的耦合和数据的内循环,整个架构会相对复杂一些,这也是SLAM目前发展的一个挑战。
SLAM具体落地应用的框架
这里讲一些SLAM具体落地应用的框架,因为只有SLAM是不够的,它只能做定位和一定程度上的建图,而且很多时候都是用稀疏点云的方式来进行建图,这对于导航来说还是不够的。
对于实际的应用场景,对于鲁棒性的要求非常高,所以通常情况下我们更倾向采用这种多级的保护机制,比如在机器人上最差也要有里程计这样的东西,让它能够知道自己在哪,虽然不是特别准,但是它能够提供一个基础的信息,即使它在那一瞬间视觉信息完全失效,它也能够坚持一会儿。
同时利用一些惯性和外界的信息,比如说超声、碰撞信息等等,进行地图的更新和融合,再把定位信息、各种不同传感器和地图的信息根据类似历史滤波的逻辑做一个定位功能的增强,有了这些之后,会把这些地图、机器人位置送给导航模块来进行路径规划和任务的处理。
总之,只有SLAM还是不够的,需要穷尽各种各样的方法对传感器进行鲁棒性的提升。
现在,无论是Sparse SLAM还是Dense SLAM甚至Semantic SLAM已经逐渐发展得很庞大了,对算力的要求越来越高,整体的趋势都得到一致的认同。
具体的难点相对来说也比较明确,其中一个比较大的难点就是算力问题,算力问题一直以来都是SLAM比较头疼的一个问题,但是也有很多解决的方法,比如Cortex A系列ARM有一个方案,它就是用ARM SISC指令集和GPU,然后基于OpenGL进行加速,比如在一些矩阵运算和滤波算子的一些加速上其实还是有不少提升的。
但是它的缺点在于从数据搬运角度来说做的优化还不够多,所以看起来CPU算得快了,但是数据送得不够快,所以相对来说整个算力的提升也就是几倍的提升。
异构处理器
还有一些比较有名的异构处理器,现在有各种各样的SPU,一些老牌的厂商也会做自己的一些加速器,比如CEVA XM系列,就是用VPU加SPU组合的逻辑,配合他们的Vector DRAM提高数据搬运速率,同时也通过更高位宽的寄存器实现更高的处理效率,同时用Scalar Prcessing Unit进行逻辑上的调度,提高它的片内数据搬运的成本,以提高整个芯片效率。
目前基于这个处理器能做到一个类似于将YOLO网络实现大约10Hz的帧率,还是一个挺好用的方案,像之前被Intel收购的Movidius,也出了一个叫计算神经棒的东西,能将各种网络布置到它的芯片上。
比较有意思的是,它的芯片上有两个小的类似Scalar Processing Unit,或者类似ARM小调度处理器,专门负责片内的数据调度,旁边有十二个Vector Processors,它同时在芯片上还做了好多外置的图像处理算法加速器,比如有图像特征等等。
它们都放在这个片子上,大家在用的时候可以实现一个更灵活的加速,因为核比较多。大疆早期也是用这个去做的,但是它的缺点就是RISC那套逻辑用的也不是ARM的,是欧洲航天局的,所以生态链不是特别完善,好多工具也不是特别完整,用起来比较吃力一些,但是这个片子的设计架构和逻辑在当时是非常新颖和有创新性的,直到现在也还是非常有代表性的一个片子。
在有了算法、处理器、传感器之后,整个SLAM还是需要生态,首先前端有Camera的一些预处理逻辑,有各种各样的传感器接到它的Sensor Interface上,同时需要接到各种执行器件上,比如电机、工业上的机械臂等等,它脑子里要有用Real-Time Loop,负责各种实时性的调度,比如高精度的传感器时间戳的采集和对准,以及高实时性器件的执行和反馈。
它后端还需要有一个相对来说比较强的后端集群优化或者深度学习执行,整体来说还是一个比较庞大的框架,但是任何一个机器人都需要这个框架,否则也不能够达到一个稳定的应用,
举个例子,我们目前有一个单目的模块,这个模块其实是3cm x 8cm,核心硬件比较简单,有处理器、DDR、Flash、摄像头、IMU和WIFi,在主芯片上面做了一个On Chip的实时的SLAM。
它其实描述的是一个用单目摄像头在一个家庭环境中进行的一系列定位以及全覆盖的路径规划,能够实现整个家庭环境全覆盖的清扫功能,就是基于这样一个3刀左右芯片来实现的。
SLAM发展的挑战
SLAM以后发展还有很多挑战
视觉SLAM中依然没有很好解决的一个问题就是暗光问题,比如怎么去实现低照度下的CMOS环境感知。
我们目前用的是一个3um x 3um大的像元尺寸,但是在个位数勒克斯光照强度暗室下,就是暗环境下,vSLAM还是会退化,所以这也是目前的一个挑战。
未来SLAM发展方向第一点就是和AI、语义的结合,无论是Semantic还是和安防功能的结合、还是和服务功能的结合,比如说SLAM运作的过程中可以通过深度学习识别各种不同的动态障碍物,然后进行SLAM的一个精度的增强或者说进行一个场景的识别;比如说可以识别出厨房、卧室、客厅,进行场景的自动划分,然后提供未来指令型任务的输入和输出,同时还可以在家里做一些安防功能,比如看门窗有没有关好。
SLAM下一步更需要的是一个更适合的处理器,首先最好是在On-chip方式上实现Deep Learning,目前有些case能做出来,但是相对来说成本比较高,生态链也不够完善,需要有更多公司进来把产业链做得更加开放、方便一些。
其实从处理器的角度来说,希望有各种各样的异构处理器,一方面能够保证算力性能,比如用更高配置的ARM核、DSP核进行算力上的增强,同时也希望有类似MCU的这种Cortex M系列的处理器核,提高它的实时性性能,这样它才能够容易地应用在各种各样的场景中。
在硬件上也需要有更高精度的IMU,提高整个惯性测量的性能。还需要更快的数据传输和数据存储,SLAM随着地图的增大,它的数据量是迅速增加的,如果不能够将这些数据通信和存储的效率提高的话,瓶颈还是比较大,需要各种各样的行业协力才能把SLAM做得更好。
-
传感器
+关注
关注
2554文章
51681浏览量
758419 -
SLAM
+关注
关注
23文章
428浏览量
31989
原文标题:视觉SLAM的技术现状和应用趋势
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论