 DeepMind开发了PopArt,解决了不同游戏奖励机制规范化的问题
DeepMind开发了PopArt,解决了不同游戏奖励机制规范化的问题

多任务学习一直是AI研究的长期目标。DeepMind开发了PopArt,解决了不同游戏奖励机制规范化的问题,它可以玩57款雅达利电子游戏,并且在所有57款游戏中达到高于人类中间水平的表现。
多任务学习——让单个agent学习如何解决许多不同的任务——这是AI研究的一个长期目标。
近年来,多任务学习领域已经取得许多卓越的进步,例如DQN这样的智能体能够使用相同的算法来学习玩多个游戏,包括雅达利经典的 “突出重围”(Breakout)和 “乒乓球”(Pong)游戏。
这些算法为每项任务训练一个专家智能体(expert agents)。随着AI研究向更复杂的现实世界领域发展,构建一个单一的强智能体(general agent)来学习执行多重任务将变得至关重要,而不是构建多个专家智能体。然而,到目前为止,这已经被证明是一项重大挑战。
原因之一是,强化学习智能体用来判断成功的奖励方案经常存在差异,导致他们把注意力集中在奖励更高的任务上。例如,在雅达利游戏“Pong”中,agent每一步会获得-1、0或+1的奖励:
Pong游戏中,两道竖杠代表球拍,一个小光点代表球在屏幕上蹦蹦跳跳,由人操纵按纽控制反弹,打不中就失去一分
相比之下,在“吃豆人”游戏中,agent每走一步就可获得几百、几千的分数。即使个体奖励的规模相似,但随着agent变得更好,奖励的频率会随着时间推移而变化。
这意味着agent倾向于关注那些有很高分数的任务,导致在某些任务上表现更好,而在其他任务上表现更差。
为了解决这些问题,DeepMind开发了PopArt,它可以调整每一款游戏的分数等级,这样不管游戏原本的奖励等级如何规定,AI智能体都会判断游戏具有同等的学习价值。
PopArt:在保持输出完好的同时,自适应地重新调整目标(PreservingOutputsPrecisely whileAdaptivelyRescalingTargets)。
DeepMind将PopArt规范化应用到最先进的强化学习智能体上,从而得到一个单一的智能体,它可以玩57款雅达利电子游戏,并且在所有57款游戏中达到高于人类中间水平的表现。
PopArt:规范化奖励,不影响目标
一般来说,深度学习依赖于不断更新的神经网络的权重,使神经网络的输出更接近期望的目标输出。当神经网络被用于深度强化学习时也是如此。PopArt通过估计这些目标的平均值和传播范围(比如游戏中的得分)来工作。然后,它使用这些数据对目标进行规范化,再利用它们来更新网络的权重。
使用规范化的目标可以使学习更加稳定和强大,以适应规模和转换的变化。为了获得准确的估计——例如对未来的预期分数的估计——网络的输出可以通过反转规范化过程来重新调整到真实的目标范围。如果直接这样做,每次更新统计数据都会改变所有未规范化的输出,包括那些已经非常好的输出。我们通过向相反的方向更新网络来防止这种情况的发生。这意味着我们可以在保持以前学习过的输出完好的同时,获得大规模更新的好处。
传统上,研究人员通过在强化学习算法中使用奖励修剪(rewardclipping)来克服不同奖励尺度的问题。这种方法将很大或很小的分数修剪为1或-1分的得分,大致使预期奖励规范化。虽然这使学习变得更容易,但是它也改变了agent的目标。
例如,在“吃豆人小姐”(Ms. Pac-Man)游戏中,吃豆人的目标是收集豆子,吃到每个豆子获得10分,吃到鬼魂获得200到1600分。通过修剪奖励,agent吃一个豆子和吃一个鬼魂得到的奖励没有明显的区别,导致agent只吃豆子,从不去追逐鬼魂。如下面的视频所示:
当我们用PopArt的自适应规范化来代替reward clipping,结果导致了智能体完全不同的行为。它会追逐鬼魂,并且获得了更高的分数。
使用PopArt进行多任务深度强化学习
我们将PopArt应用于Importance-weighted Actor-Learner Architecture(IMPALA),这是DeepMind最流行的深度强化学习智能体之一。在实验中,与没有使用PopArt的baseline agent相比,PopArt大大提高了agent的表现。无论是修剪了奖励还是没有修剪奖励,PopArt智能体在游戏中的中位数得分都高于人类中位数得分。
这远远高于使用reward clipping的baseline,而没有使用reward clipping的baseline根本无法达到有意义的表现,因为它无法有效地处理不同游戏之间的奖励尺度的巨大变化。
57款Atari游戏的标准化表现中位数。每一行对应于单个智能体的中位数表现,该智能体被训练来使用相同的神经网络来玩所有这些游戏。实线表示使用 reward clipping的表现,虚线表示没有使用 reward clipping的表现。
这是我们第一次在使用单一智能体的这种多任务环境中看到超过人类的表现,这表明PopArt可以为如何在无需手动修剪或调整的情况下平衡各种目标的开放式研究问题提供一些解决方案。当我们将AI应用于更复杂的多模态领域时,AI在学习过程中自动适应规范化的能力变得非常重要,因为在这些领域中,AI智能体必须学会权衡各种不同的奖励和不同的目标。
-
神经网络
+关注
关注
42文章
4840浏览量
108142 -
智能体
+关注
关注
1文章
551浏览量
11642 -
DeepMind
+关注
关注
0文章
131浏览量
12429
原文标题:强化学习重大突破:DeepMind用一个AI在57个游戏中全面超越人类
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
贴片知识课堂十一,PCB设计规范化第第三节
关于发帖标题规范化管理公告
未来的AI 深挖谷歌 DeepMind 和它背后的技术
一种创新的无监督文本规范化系统
数据库-关系规范化的详细资料介绍,为什么要对进行关系的规范化?
浅析FPGA规范化的重要性
原理图绘制规范电子版资料下载

基于规范化函数的深度金字塔模型算法
怎么样才能让Java代码编写更规范化
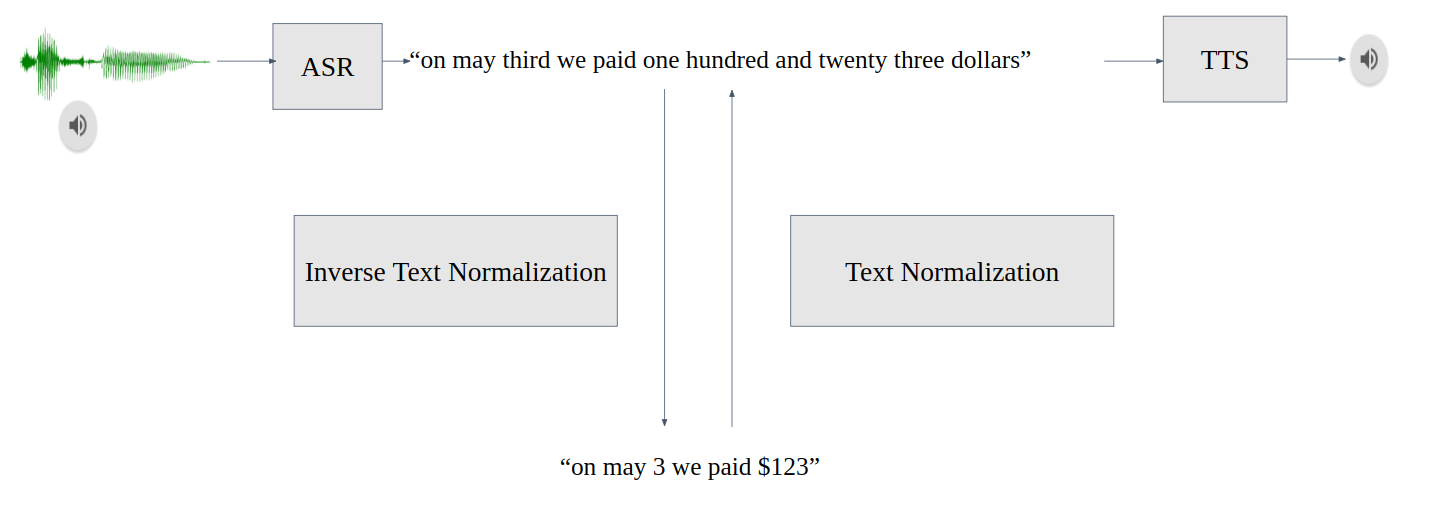
使用NVIDIA NeMo进行文本规范化和反向文本规范化
论硬件开发过程中开发文档规范化的重要性




评论