 疯狂的不只是论文总数,还有学术垄断
疯狂的不只是论文总数,还有学术垄断
作为人工智能领域的顶会,已经有 30 年历史的 NIPS 今年以来一直风波不断。先是被爆出 NIPS 2017 出现了性骚扰行为,然后又被 diss 会议名称太色情,需要改名。之后,又有人在网上爆出,一名刚刚毕业的本科生成为大会论文同行评审,立马遭到新一轮的 diss。
不过,大家似乎都是口是心非。NIPS 并没有因此而门前冷落,反而火爆异常。仅仅 11 分 38 秒,NIPS 正会门票就卖光了。不仅如此,今年的 NIPS 收到了 4856 篇论文投稿,比去年的 3240 篇增长了近 50%。本次大会接收的论文总共 1011 篇,去年只有 679 篇,不过接收率倒是维持在 20% 左右。
疯狂的不只是论文总数,还有学术垄断。
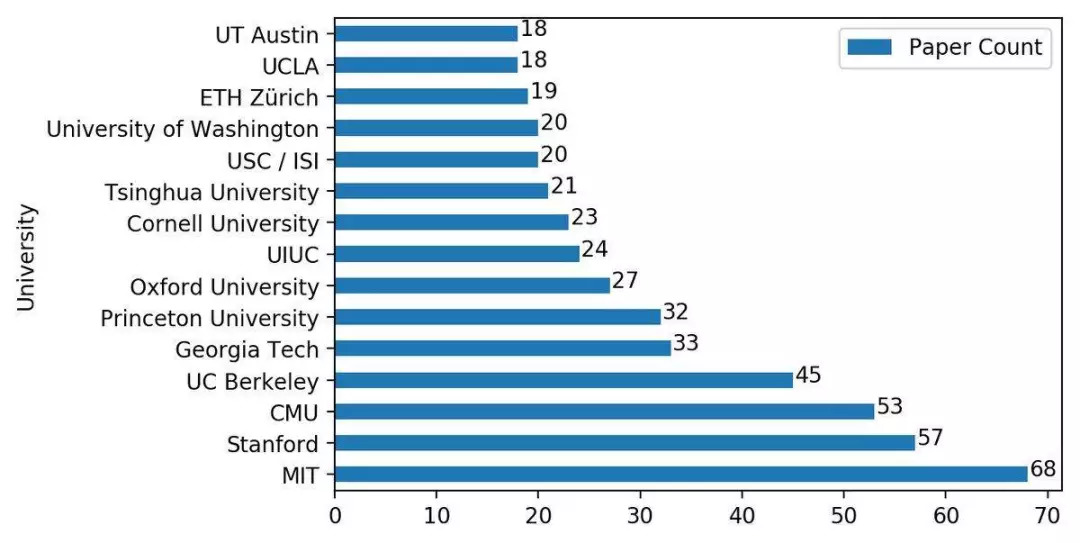
IBM 工程师 Inkit Padhi 统计的数据显示,本届 NIPS 大会 Google Research 以 107 篇论文位列第一,几乎占据了接收论文总数的 10%,而去年这个数字还是 60。除此之外,MIT、斯坦福、CMU 等美国名校分别以 68、57、53 的位列前四。
通过下面的两张图可以发现,美国的几大科技公司和几大名校一如既往地占据了本届 NIPS 的半壁江山,相比去年,并没有任何改善的迹象。当然,这也与这些美国机构强大的经济和科研实力有关。
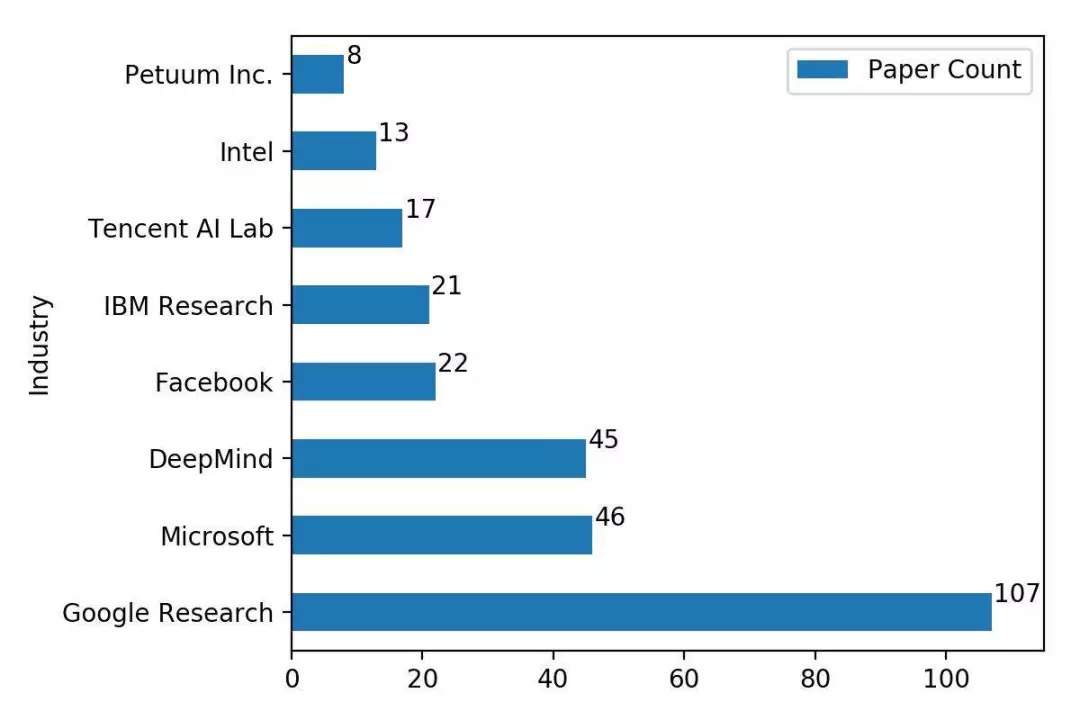
当然,国内的清华大学和腾讯也有不错的表现,其中清华大学共有 21 篇论文被接收,腾讯的 AI Lab 共有 17 篇论文被接收。但是跟美国同行比,还是有很大的差距。
要知道,在 7 月份的 IJCAI 大会上,中国学者获多篇 Distinguished Paper 奖,中国人论文46%,华人一作论文占总接收论文的 65.5%。而且南京大学教授周志华还当选 IJCAI 2021年 程序主席,成为 IJCAI 史上第二位华人大会程序主席。
不过,这并不代表中国没有进步。在 NIPS 2017 上,清华大学还只有 12 篇论文被接收,而腾讯的 AI Lab 也只有 9 篇,今年虽然论文的绝对数量和美国同行还有差距,但增长迅速,未来可期。
与此同时,作为国内机器学习领域的领军人物,南京大学的周志华教授本次也有 5 篇论文被接收。通过这些论文,读者可以一窥目前 AI 领域比较前沿的研究方向。受文章篇幅所限,本文只对这 5 篇论文的摘要进行了介绍,想要详细了解的可以查看完整论文。
1、Unorganized Malicious Attacks Detection
论文作者:Ming Pang · Wei Gao · Min Tao · Zhi-Hua Zhou

论文摘要:在过去十年里,推荐系统领域备受关注。许多攻击检测算法被开发,以便获得更好的推荐系统,其中大部分研究主要是着眼于 shilling attacks。shilling attacks 主要是一类通过相同策略生成大量用户配置文件以提升或降低推荐项目位置的攻击。在本文中,我们考虑了不同攻击方式:无组织的恶意攻击,即攻击者在无组织的情况下单独使用少量的用户配置文件来攻击不同的项目。这种攻击类型在许多实际应用中都非常常见,但对其的相关研究却较少。我们首先将无组织恶意攻击检测构建为矩阵补全问题,并提出无组织恶意攻击的检测方法 (UMA) ,即近似交替分裂增广拉格朗日法。在大量的实验中,我们从理论和实证的角度分别验证了所提方法的有效性。
2、Preference Based Adaptation for Learning Objectives
论文作者:Yao-Xiang Ding · Zhi-Hua Zhou

论文摘要:在许多实际的学习任务中,我们很难直接优化真实的工作指标,也很难选择正确的替代目标。在这种情况下,我们可以基于对真实测量值和目标之间进行弱关系建模,再将目标优化过程融入到循环学习中。在本文,我们研究一种目标自适应的任务,其中学习者通过迭代的方式来适应来自于 oracle 的偏好反馈的真实对象。实验证明,当目标可以进行线性参数化时,该学习问题能够通过利用 bandit model 得到解决。此外,我们还提出了一种基于 DL^2M 算法的新颖采样方法,用于学习优化的参数,其具有较强的理论证明和有效的实践应用。为了避免在每个目标函数更新后都要从头开始学习理论假设,我们进一步提出了一种改进的自适应方法,来有效地将每个预学习的元素假设迁移到当前目标中。我们将以上的方法应用于多层标签学习中,并证明了该方法在各种多标签的工作指标下能够展现出高效的性能。
3、Multi-Layered Gradient Boosting Decision Trees
论文作者:Ji Feng · Yang Yu · Zhi-Hua Zhou

论文摘要:多层表征方法被认为是深度神经网络的关键要素,尤其是类似于计算机视觉的感知任务。虽然,诸如梯度增强决策树 (GBDT) 之类的非可微模型是针对离散或列表数据进行建模时所采用的主要方法,但是它们很难与这种表示学习能力相结合。本文,我们提出了一种多层的增强决策树模型,该模型主要通过将多层回归的 GBDT 模型叠加一起作为其构建模块来研究学习层次表示的能力。在没有进行反向传播和可微分特性的情况下,该模型可以结合跨层目标传播的变体进行训练。实验结果表明我们所提出的模型在性能和表示学习能力方面具有高效的性能。
4、Adaptive Online Learning in Dynamic Environments
论文作者:Lijun Zhang · Shiyin Lu · Zhi-Hua Zhou

论文摘要:在本文中,我们研究了动态环境下的在线凸优化问题,旨在对任何比较器序列的 dynamic regret 进行界限。先前的工作表明,在线梯度下降算法具有的 dynamic regret 值为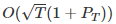 ,其中 T 是迭代次数,P 代表的是比较器序列的路径长度。然而,这个结果并不让人满意,因为这与我们论文中建立的 dynamic regret 的下界值存在很大差距。为了解决这一缺陷,我们提出了一种名为动态环境自适应学习算法 (Ader), 旨在将下界与双对数因子相匹配,以实现 dynamic regret 值为
,其中 T 是迭代次数,P 代表的是比较器序列的路径长度。然而,这个结果并不让人满意,因为这与我们论文中建立的 dynamic regret 的下界值存在很大差距。为了解决这一缺陷,我们提出了一种名为动态环境自适应学习算法 (Ader), 旨在将下界与双对数因子相匹配,以实现 dynamic regret 值为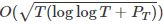 。此外,我们还基于替代损失提出了一种改进的 Ader 算法,以这种方式,每轮训练的梯度评估量会从 O(logT) 减少到1。最后,我们将 Ader 算法进一步扩展到一系列可用于表征比较器设置的动态模型中。
。此外,我们还基于替代损失提出了一种改进的 Ader 算法,以这种方式,每轮训练的梯度评估量会从 O(logT) 减少到1。最后,我们将 Ader 算法进一步扩展到一系列可用于表征比较器设置的动态模型中。
5、ℓ1-regression with Heavy-tailed Distributions
论文作者:Lijun Zhang · Zhi-Hua Zhou

论文摘要:在本文中,我们探索了 heavy-tailed 分布下的线性回归问题。与先前使用平方损失来评估性能的研究不同,我们采用了绝对值损失来评估性能,这能够在预测误差较大时展现更强的鲁棒性。为了解决输入和输出都可能带来的 heavy-tailed 问题,我们将其转化为一个截断最小化问题,并证明它具有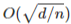 的超额风险,其中 d 代表维度,n 代表样本量。与传统的在 l1 回归上所做的工作相比,我们所提出的的方法能够在输入和输出之间没有指数矩的条件下,还能够实现高概率的风险约束。此外,当输入有界时,我们也能证明:我们的方法即使 heavy-tailed 输出的情况下,经验风险最小化也能匹敌 l2 回归。
的超额风险,其中 d 代表维度,n 代表样本量。与传统的在 l1 回归上所做的工作相比,我们所提出的的方法能够在输入和输出之间没有指数矩的条件下,还能够实现高概率的风险约束。此外,当输入有界时,我们也能证明:我们的方法即使 heavy-tailed 输出的情况下,经验风险最小化也能匹敌 l2 回归。
-
人工智能
+关注
关注
1800文章
48079浏览量
242136 -
机器学习
+关注
关注
66文章
8460浏览量
133409
原文标题:NIPS论文排行榜出炉,南大周志华5篇论文入选
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

LDR6500,不只是转换,是视觉盛宴的开启者!

OpenHarmony程序分析框架论文入选ICSE 2025
PON不只是破网那么简单
gawk程序基础教程
Nullmax视觉感知能力再获国际顶级学术会议认可


不只是前端,后端、产品和测试也需要了解的浏览器知识(二)
生成式AI在学术领域的应用亟需高度重视
定档10月17日!本届学术年会还有重磅惊喜
如何解决射频功放阻抗不匹配问题
不只是前端,后端、产品和测试也需要了解的浏览器知识
I2C主机产生不了起始位的原因?
Achronix新推出一款用于AI/ML计算或者大模型的B200芯片






 工商网监
工商网监
评论