 从2D到3D,沉浸式的实时视频通信是如何实现的?
从2D到3D,沉浸式的实时视频通信是如何实现的?
过去几年,我们探索工作的初衷是什么?就是如何在未来提供更好的沉浸式的通讯体验。
我们所从事的是通信技术。最早,我们提供电信网络,语音通话是我们唯一的业务。语音通话的体验很重要,但始终无法提供面对面、身临其境的体验。如何提升呢?第一步,就是加入视频,有了视频就拉近了彼此距离,双方获得了更好的交流体验。但这还不够。
在我们的设想中,沉浸式的通讯体验应该像图中所示,人们在通话时就像在同一个屋子中相视而坐。这是我们希望最终达到的体验效果。
在7、8年前,我们做了一个项目,它叫 Augmented Personal Telepresence Overlay System(如下图)。那时,统一通信的概念已经比较普遍,每个人在自己的桌面上都可以发起实时通信,但体验并不特别好。那时深度相机开始出现了,它通过对深度的获取可以把人物分割出来,分割出来之后在桌面上进行视频通话时可以把两个人放到一个空间里。在这个项目里,每个人坐在自己的桌子前,通过深度相机将人从环境中分割出来之后,可以在电脑上看到两个人坐在一张桌子上,但其实他们是在不同的屋子里。同时,支持屏幕共享,这让沉浸感得到了提升。
图:Augmented Personal Telepresence Overlay System
但是这个项目看起来还是在一个小屏幕上,它的沉浸感比较弱。那么我们能不能进一步提升沉浸式的体验呢?
2012年,我们采用了更大的屏幕。这个屏幕就像一面墙,需要把人物的全身从背景中分割出来。那时深度学习没有广泛被大家了解,不像现在用深度学习进行图像的分割已经非常普遍。那时的图像分割比较困难,需要借助于一些手段对人的动态进行分割,才可以把它叠加在同一个背景下,这样你站在这个大屏幕前,跟对方才有面对面、沉浸式的感受。
刚刚的项目虽然提供了一定的沉浸感,但是它无法提供六自由度。2013年、2014年,各类 AR、VR 设备陆续面市。而头盔、眼镜,弥补了这一特性,能提供更沉浸式的体验。
我们怎样把沉浸感的视频通信实现出来呢?
2016年,微软做了一个名为 Holoportation 的项目。通过这个眼镜,我们配合采集3D的软件进行实时建模,然后传递给对方,对方戴上眼镜可以实现六自由的实时交互。在眼镜中,另一个人是通过实时的3D 建模,在本地渲染出来的。
图:微软的Holoportation
这与以前 2D 时代非常不同,需要进行 3D 建模。在以前传统的 2D 时代,我们会从一个角度,用一个摄像机,拍一个视频,然后实时获取到信息后,传递给对方,1分钟内就可以重现它,并进行渲染。到了 3D 环境下,我们没有办法再利用一个摄像机,来获取 人物的 3D 信息。如何获取这个信息,变成了非常具有挑战性的工作。
以前 2D 时,我们获取的信息是像素,一个 XY 座标,座标上有 RGB 的信息,有了这个信息就可以得到完整的 2D 画面。
但是到了 3D 时,信息变成了三维的,我们需要在三维坐标上要有色彩信息和其他属性 信息,现在没有一个手段能够直接获取它。当然,现在有很多种尝试。我们现在的系统是试着实现多视角,要能同时从四面八方获取信息,所以我们采用了八视角,有八组相机分布在人的周围,进行实时的采集。
3D 的采集在很早以前就有。如果不是实时的,用几百个摄像机,可以非常好的进行重建,但都是离线状态下进行重建,需要很长时间。但是,我们要做到实时的采集、重建,非常困难。
我们简单来讲一下当时我们是如何来实现实时的 3D 的采集(如图)。首先我们用了八组深度摄像机来进行采集,然后实时地生成点云信息。
在动态重建时,frame 之间的差别很大。如果 frame 与 frame 之间没有一定约束的话,人们看到的图像会抖动、晃动,效果会很差。如果要提升效果,就要有动态的约束。对于人物这种非刚性的物体进行实时重建,挑战是非常大的。在这个重建过程中,我们是用八个摄像机获取到的深度彩色图,合成为当前 frame 的模型。而它与前一个 frame 需要进行空间的匹配,从前一个模型匹配到当前的模型。我们知道,在 2D 中,我们只需要计算运动矢量,但在 3D 中则需要进行矩阵的运算,空间搜索非常复杂。在完成匹配之后还需要进行融合,融合后形成当前 frame 的 3D 模型。然后,我们再从点云模型计算 Mesh。
纹理也很有挑战性。我们有八个摄像机,它们从不同视角观察同一个点的时候,由于光照不同、角度不同,它颜色、纹理都有差异。所以在这个过程中,还需要我们进行融合、优化,才能有比较平滑的视觉观感。然后再进行传输。在传输时,我们也做了一些简单的压缩。比如我们将 3D 纹理转为 2D ,再进行压缩。在这个过程中,我们也做了很多工作,比如 frame 与 frame 之间如何匹配,才能使他们相关性更高,从而提升压缩率。
以上就是我们所做过的一些尝试。
其实,国际上有很多组织也在研究相关的技术标准。例如,MPEG 组织也在考虑未来的沉浸式信息,如何编码、表示和传输。我们也正积极参与其中,与更多人共同探索。
目前 MPEG 正在做的就是 MPEG-I。它是针对未来沉浸式多媒体的格式、编码、压缩、传输等一系列的标准。大家可能了解的更多的就是与视频相关的 MPEG-I Part3。实际上大家可以将它理解为 H.266,也就是 H.255 的下一代。它会更多地针对沉浸式媒体的压缩。另一方面就是 MPEG-I Part5,即点云的压缩。这与我们刚刚分享的项目非常相关。当你获得了 3D 模型,怎么进行高效的压缩、存储、传输,国际上也有相应的标准化组织在共同探索如何来做。现在来讲还属于比较超前的研究,仍处于早期阶段。这也是第一次在 MPEG 里尝试做点云的标准化工作,预计在明年会有第一版的标准。
在点云压缩标准中有两个类别,第一种是对静态的高质量 3D 模型进行压缩;第二种是针对动态的 3D 模型进行压缩;第三种则是针对边采集边生成点云时,如何来进行压缩。其中第二种与我们正在做的项目更加相关。
在去年的一次 MPEG 的会议上,我们经过对比选择了由苹果提出一套基于视频压缩的方案,它是目前性能表现最好的。随后我们各个公司也会基于这套方案来进行不同程度的改进,最终会形成一套标准。
这套压缩方案是怎么做的呢?首先对一个动态的 3D 模型压缩时,将它映射到 6 个 2D 平面上,然后再 patch 放在同一个 2D 的图中,最后将 Patch 信息、纹理、色彩、空间数据等到一起,再进行编码传输。
VPCC(Video Point Cloud Compression)编码器端的基本工作流程是这样的:首先进行映射,然后选取每个部分映射到哪一个面上,然后生成 patch 信息,用视频的方法进行压缩。因为在压缩之后会有一定的误差,所以要根据原来的 patch info 进行调整,也就是图中的“smoothing”模块。调整之后,再通过视频的方法对它进行压缩。
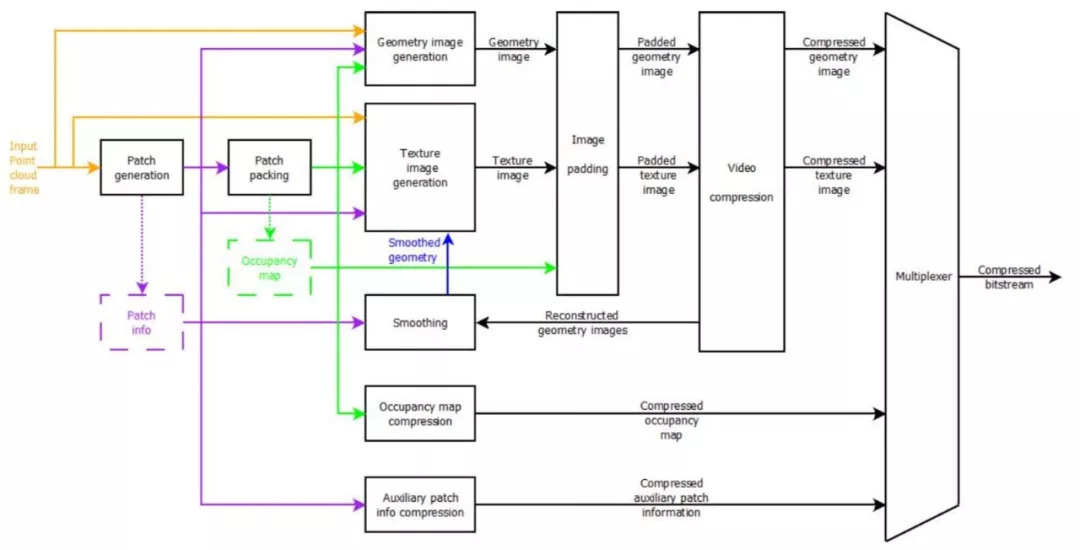
图:编码器架构

图:解码器架构
由于在 3D 上进行配准、深度计算等工作的复杂度非常高,所以现在我们在计算能力上海很难实现非常高精度的 3D 实时建模重建。但是随着我们计算能力的不断提升,以及深度学习的应用,可以进一步提升我们算法的性能。所以在未来会有更长足的发展。虽然动态的、高还原度的 3D 重建距离商业应用还有很长的距离。但回想我们在7、8年前做的图像分割的技术,当时来看有很大的难度,但现在已经在手机中得到了广泛应用。所以我们相信其中很多技术会逐步得到应用。
-
3D
+关注
关注
9文章
2894浏览量
107648 -
2D
+关注
关注
0文章
66浏览量
15205 -
视频通信
+关注
关注
1文章
20浏览量
9178
原文标题:RTC 技术分享 | 从 2D 到 3D,沉浸式的实时视频通信
文章出处:【微信号:shengwang-agora,微信公众号:声网Agora】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Dialog半导体推出首款2D到3D视频转换芯片,为智能手机
全球首款2D/3D视频转换实时处理芯片:DA8223
Lattice将在CES 2013上展示基于LatticeECP3的实时3D视频转换器
适用于显示屏的2D多点触摸与3D手势模块
如何把OpenGL中3D坐标转换成2D坐标
阿里研发全新3D AI算法,2D图片搜出3D模型
基于神经网络的2D到3D的机器学习
探讨一下2D和3D拓扑绝缘体
将2D/3D图表和图形添加到WindowsForms应用程序中
2D与3D视觉技术的比较
一文了解3D视觉和2D视觉的区别
有了2D NAND,为什么要升级到3D呢?

技术前沿:半导体先进封装从2D到3D的关键





 工商网监
工商网监
评论