 一文解读深度学习的发展
一文解读深度学习的发展

在2018清洁发展国际融资论坛上,北京交通大学人工智能研究院常务副院长、教授于剑先生从专业角度回顾了人工智能的发展历程,并介绍了深度学习的适用范围和所面临的问题。他指出,深度学习是机器学习领域最引人注目的研究方向,但没有任何一种算法可以解决机器学习所有的应用。
深度学习算法的分类
深度学习在早期被称为神经网络。神经网络是一种特殊的学习方式,在神经网络领域,人们将学习定义为“基于经验数据的函数估计问题”。需要指出,这样的学习定义虽然非常片面,但对于神经网络而言已经够用了。如此一来,如何构造函数,并应用经验数据将其估计出来,就成了神经网络面临的首要问题。
学习算法的分类有很多种。一种分类方式是将学习算法分为傻瓜型学习算法与专家型学习算法。所谓傻瓜型学习算法,就是任何人使用得到的结果都差别不大的学习算法。所谓专家型学习算法,就是专家与普通人使用得到的结果差别巨大的学习算法,每个人得出的结果很难一致。当然,中间还有一些处于两者之间的学习算法,既不是纯傻瓜型的也是不纯专家型的。
另一种学习算法分类,是黑箱算法和白箱算法。所谓黑箱算法,是指使用者难以明白学习算法学到的知识,特别是其学习到的知识难以解释。所谓白箱算法,是指使用者容易明白学习算法学到的知识,特别是其学习到的知识可以解释清楚。
有了以上四个概念之后,我们就可以回顾早期的神经网络是如何发展成今天的深度学习的了。
早期神经网络无法解决非线性问题
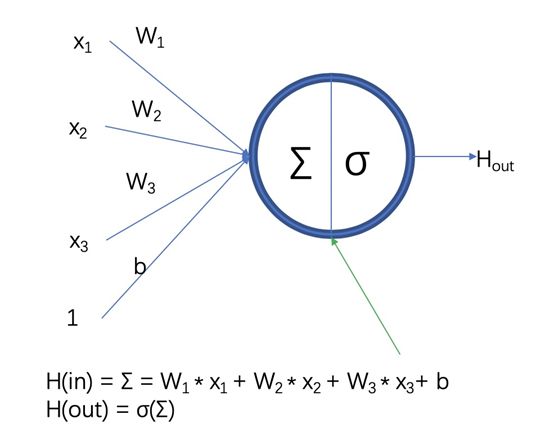
神经网络第一个成熟算法是线性感知器算法,该算法是白箱、傻瓜型算法,特点是节点为恒同映射,不同层次节点间的关系是线性组合关系,优点是解释性好,如线性可分的时候,可以证明迭代有限步就收敛。这个算法在当时得到了很大的支持,拿到了大批基金。
但很遗憾,在1969年,Minsky与Papert提出的一个著名的反例——异或问题,给了线性感知器算法致命一击。世界的问题大多是非线性问题,而线性感知器算法连非线性问题中最简单的“异或问题”都解决不了,由此可以推断其实际用处不大。从此以后的10多年时间里,在国际上,无论是东方还是西方,无论是前苏联还是日本、美国,看到神经网络都视之为骗子,不再给予支持,这也直接导致了神经网络第一个冬天的到来。
多层前馈神经网络的崛起与失败
早期的神经网络不成功是因为是线性的,如果改成非线性是不是好一点呢?到1982年以后,Hopfield发了好几篇文章,证明了非线性网络的有用性。这时候的神经网络已经是典型的黑箱、专家型算法了。
多层前馈神经网络非常成功的应用在了邮政编码的识别中。20世纪80年代是美国邮政最发达的年代,当时通讯几乎全都是纸质的,有大量的信件需要发送,工作量特别大。人们希望用机器代替,就用了邮政编码的自动分捡系统,可以做到三分之二正确识别,剩下三分之一拒识的由人分捡,这样大大减轻了工作量。
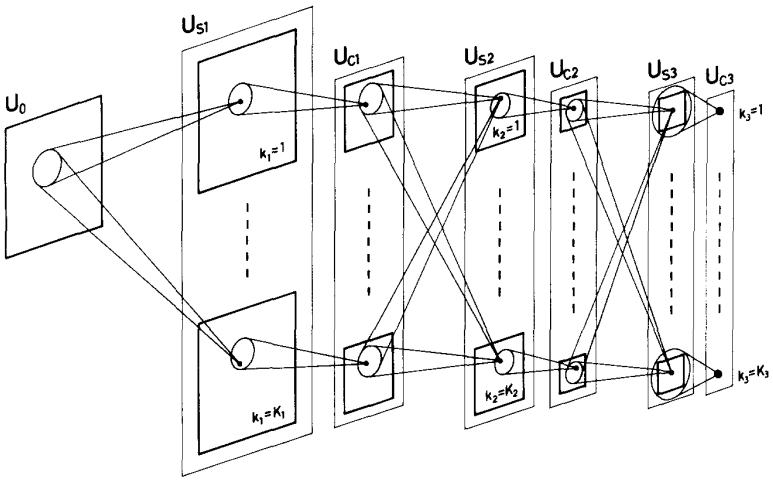
这时候神经网络有很大的改变,取得了很大的进展,节点使用非线性函数,训练时间长,一般为三层:输入层、隐层、输出层。主要是证明了神经网络的万有逼近定理:“如果一个隐层包含足够的多神经元,多层前馈神经网络能以任意精度逼近任意预定的连续函数”。在神经网络采用的学习定义下,该定理证明了神经网络的万能性。由此,当时人们甚至认为神经网络可以无所不能。据说,1988年IJCNN(国际神经网络联合会议)曾经贴出一个疯狂的标语,称:“人工智能已死,神经网络万岁”。
但是,当人疯狂的时候就要挨揍了。如果有其他算法比神经网络性能好一点,解释性强一些,就一定能将神经网络打入冷宫。这样的事情真的发生了,1995年支持向量机(SVM)横空出世,该算法比神经网络算法解释性好,其几何解释干净漂亮,性能比当时的三层神经好一些。这时候神经网络进入了第二个冬天,好在这个冬天并没有第一个那么冷,基金支持并没有彻底断绝,能不能拿到基金,主要看人品和运气。
突破三层的神经网络,深度学习迎来春天
但是SVM也有缺陷,它主要是处理小数据的,是小样本学习的典范算法。而到了2008年以后,我们迎来了大数据时代,各行各业都有大量的数据,而且电脑的计算能力也大幅度地提高了,因此SVM在很多领域将难以适用。以往的神经网络基本上都是三层的,原因是四层以上的神经网络会遇到数据量、计算力不足和梯度消失等问题。如果以上三个问题能够解决,就能为深度学习奠定很好的基础。
到2010年左右,人们通过采用新的激励函数,逐渐克服了梯度消失或者发散问题,加之数据量和计算力的不断提高,深度学习迎来了蓬勃发展。这使得化名为深度学习的神经网络研究进入了另一个春天。
我们现在所说的深度学习,可以理解为层数高于三层的神经网络。神经网络和深度学习最重要的区别是:神经网络的主流算法考虑时空数据的局部相关性较少,大多时候假设特征之间的独立性;而深度学习的主流算法基本考虑了时空数据的局部相关性,如CNN,RNN,LSTM等。深度学习可以使学习能力提高,而训练样本并不需要增加太多。
到2016年,神经网络深度就已经达到1207层。随着深度的提高,算法的错误率可以快速减少。深度学习避开了单纯的特征提取过程,给出了一种将学习和表示合二为一的范式。这种方式导致深度学习在有人监督学习中非常成功,同时在自监督学习中也取得了很大的成功,但在一般意义上的无监督学习中还没有取得成功。
深度学习并非万能,仍有局限
深度学习不仅是目前热度最高的人工智能研究方向,也是工业应用最广泛的学习范式,但深度学习也有其局限性。没有免费午餐的定理指出,没有任何一种算法可以解决机器学习所有的应用。深度学习也有很多“不能”的地方。比如,深度学习和人类学习相比,人用不了多么大的样本就可以学习,但是深度学习用的样本比较多。
此外,由于深度学习属于黑箱型算法,人类将无法知晓算法做出决策的原因与依据。它适用于各种低风险甚至无风险性任务,包括搜素引擎和AlphaGo等棋牌游戏,这类任务即使发生错误,后果也不严重,并不要求算法去解释这些错误为什么会发生。
但对于高风险任务,包括无人驾驶、医疗手术等,一旦发生错误,由于成本巨大,必须能够分析出发生错误的原因,以避免类似错误再次发生,此时,深度学习在解释性方面将存在弊端。
总而言之,深度学习的表示能力超强,因此,在不要求解释的学习任务中,深度学习的性能在可见的将来将一直占优。但是,在要求解释的学习任务里,深度学习将不是一个值得期待的工具。
-
深度学习
+关注
关注
73文章
5610浏览量
124655
原文标题:深度学习的能与不能
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录


解读深度学习是否过分夸大
一文读懂何为深度学习1
一文读懂何为深度学习2
一文读懂何为深度学习3

什么是深度学习算法?深度学习算法的应用
深度学习框架是什么?深度学习框架有哪些?
人工智能-Python深度学习进阶与应用技术:工程师高培解读




评论