 浅析英特尔QSV技术在FFmpeg中的具体实现与使用
浅析英特尔QSV技术在FFmpeg中的具体实现与使用

本文来自英特尔资深软件工程师张华在LiveVideoStackCon 2018讲师热身分享,并由LiveVideoStack整理而成。在分享中张华介绍了英特尔GPU硬件架构,并详细解析了英特尔QSV技术在FFmpeg中的具体实现与使用。
1、处理器整体架构
大家知道,英特尔的图形处理GPU被称为“核芯显卡”,与CPU集成封装在同一个芯片上,上图展示的是芯片的内部结构。
1.1 发展
英特尔从lvy Bridge架构开始就尝试将GPU与CPU集成在中央处理芯片中并逐代发展到Skylake架构。初期的Ivy Bridge架构中GPU所占的面积非常小,而到现在的第五代处理器架构Skylake已经实现十分成熟的GPU集成技术,GPU在芯片中所占的面积已经超过了一半。在未来我们将推出基于PCI-E的独立显卡,为PC带来更大的图像性能提升。
1.2 基础功能模块
上图展示的是一款GPU所具备的一些基础功能模块。英特尔的核芯显卡分为普通的Intel HD Graphics与性能强大的Intel Iris (Pro)Graphics,其中硬件结构的变化决定性能的高低。我们知道,GPU中的Slice个数越多,处理单元的组织方式越多,性能便越强大。Intel HD Graphics也就是GT2中只有一个Slice,而对于Iris系列中的GT3则有两个Slice;GT3e相对于GT3增加了eDRAM使其具有更快的内存访问速度,而GT4e则增加到三个Slice。GPU的基础功能模块主要由EU以及相关的Media Processing(MFX)等组成。一个Slice中有三个Sub-Slice,Sub-Slice中包含具体的EU和Media Sampler模块作为最基本的可编程处理单元,GPU相关的任务都是在EU上进行。而Media Processing中还集成了一个被称为MFX的独立模块,主要由Media Format Codec(MFX)与VQE组成。MFX可将一些处理任务通过Fix Function打包,固定于一个执行单元中进行统一的编解码处理,不调用EU从而实现提高EU处理3D图形等任务的速度。Video Quality Engine(VQE)提供De-interlace与De-Noise等视频处理任务,在编解码中使用EU是为了得到更高的视频编码质量。
1.3 结构演进
上图展示的是英特尔几代核芯显卡产品在结构上的变化。最早的Haswell架构也就是v3系列中的EU个数相对较少,最多为40个;而到Broadwell架构的GT3中集成了2个Slice,EU个数随之增加到48个,图像处理性能也随之增强。从Broadwell架构发展到Skylake架构,除了EU与Slice格式增加的变化,MFX的组织也有相应改进。Broadwell架构是将MFX集成于一个Slice中,一个Slice集成一个MFX;而到Skylake架构之后Slice的个数增加了但MFX的个数并没有,此时的MFC便集成在Slice之外。随着组织方式的改变,核芯显卡的功能也随之改变:Skylake增加了HEVC的Decoder、PAK增加了基于HEVC的处理功能等改进为核芯显卡整体处理性能带来了显著提升,第六代以后的核芯显卡也都主要沿用GT3的架构组织。
上文介绍了核芯显卡硬件上的模块结构,接下来我将具体介绍Quick Sync Video Acceleration。从Driver分发下来的Command Stream回通过多条路径在GPU上得到执行:如果命令属于编解码的Fix Function则会由MFX执行,部分与视频处理相关的命令会由VQE执行,其他的命令则会由EU执行。而编码过程主要分为两部分:ENC与PAK。ENC主要通过硬件实现Rate Control、Motion Estimation、Intra Prediction、Mode Decision等功能;PAK进行Motion Comp、Intra Prediction、Forward Quant、Pixel Reconstruction、Entropy Coding等功能。在目前的英特尔架构中,Media SDK通过API对硬件进行统一的调度与使用,同时我们提供更底层的接口Flexible Encoder Interface(FEI)以实现更优秀的底层调度与更好的处理效果。
2、软件策略
接下来我将介绍英特尔的软件策略。最底层的FFmpeg可允许开发者将QSV集成进FFmpeg中以便于开发,而Media SDK则主要被用于编解码处理,FFmpeg可把整个多媒体处理有效结合。如果开发者认为传统的Media SDK的处理质量无法达到要求或码率控制不符合某些特定场景,那么可以通过调用FEI等更底层的接口对控制算法进行优化;最顶层的OpenCL接口则利用GPU功能实现边缘计算等处理任务,常见的Hybrid编码方式便使用了OpenCL。除此之外OpenCL也可实现一些其他的并行处理功能,例如与AI相关的一些计算。
2.1 Media SDK
Media SDK分为以下几个版本:Community Edition是一个包含了基本功能的部分免费版本,Essential Edition与Professional Edition则是具有更多功能的收费版本,可实现例如hybrid HEVC 编码,Audio的编解码、Video Quality Caliper Tool等诸多高级功能和分析工具的集合。
1)软件架构
上图主要介绍的是Media Server Studio Software Stack软件架构,我们基于此架构实现FFmpeg的加速。
这里需要强调的是:
a)OpenGL (mesa)与linux内核一直是开源的项目,但之前版本的MSS中存在一些私有的内核补丁,并对操作系统的或对Linux的内核版本有特殊要求。
b)HD Graphics Driver for Linux之前是一个闭源的方案,而现在的MSDK 和用户态驱动(iHD驱动)都已经实现开源。现在我们正在制作一个基于开源版本的Release,未来大家可以通过此开源平台获得更好的技术支持。
2)编解码支持
关于编解码支持,其中我想强调的是HEVC 8 bit 与10 bit的编解码。在Gen 9也就是Skylake上并不支持硬件级别的HEVC 10 bit解码,面对这种情况我们可以通过混合模式实现对HEVC 10 bit的编解码功能。最新E3v6(Kabylake)虽然只有较低性能的GPU配置,但可以支持HEVC 10 bit解码,HEVC 10 bit编码功能则会在以后发布的芯片中提供。
2.2 QSV到FFmpeg的集成思路
FFmpeg集成的思路主要如下:
1)FFmpeg QSV Plugins:将SDK作为FFmpeg的一部分进行封装,其中包括Decoder、Encoder与VPP Filter处理。
2)VAPPI Plugin:Media对整个英特尔GPU的软件架构而言,从最底层的linux内核,中间有用户态驱动,对外的统一的接口就是VAAPI。Media SDK的硬件加速就是基于VAAPI开发,同时增加了很多相关的功能,其代码更为复杂;而现在增加的VAAPI Plugin则会直接调用LibAV使软硬件结合更为紧密。
接下来我将介绍如何将SDK集成到FFmpeg中,一共分为AVDecoder、AVEncoder、AVFilter三个部分。
1)AVFilter
AVFilter主要是利用硬件的GPU实现Video Processor功能,其中包括vpp_qsv、overlay_qsv、hwupload_qsv,其中我们重点开发了overlay_qsv,vpp_qsv与hwupload_qsv。 如果在一个视频处理的pipeline中有多个VPP的实例运行,会对性能造成很大的影响。我们的方案是实现一个大的VPP Filter中集成所有功能并通过设置参数实现调用,避免了多个VPP的实例存在。但是为什么将vpp_qsv与overlay_qsv分开?这是因为无法在一个VPP实例中同时完成compositor和一些视频处理功能(像de-interlace等)。英特尔核芯显卡内显存中的存储格式为NV12, 和非硬件加速的模块联合工作时,需要对Frame Buffer进行从系统内存到显卡显存的复制过程,hwupload_qsv提供了在系统内存和显卡内存之间进行快速帧转换的功能。
2)AVEncoder
AVEncoder目前支持H264、HEVC、MPEG-2等解码的硬件加速。
3)AVDecoder
AVDecoder目前支持H264、HEVC、MPEG-2等协议的硬件加速。
最理想的方案是在整条视频处理的Pipeline中都使用显卡内存从而不存在内存之间的帧拷贝,从而达到最快的处理速度,但在实际应用中我们很多时候是做不到这一点。将MSDK集成进FFmpeg中时需要解决内存转换的问题,例如VPP Filter不支持一些功能或原始码流并不在Decoder支持的列表中。上图中粉色与绿色的转换表示的就是数据从显存到系统内存再到显存之间的转换。我们在实践中经常会遇到处理性能的急剧变化,可能的原因就是一些非硬件处理的模块和硬件加速的模块存在与同一个pipeline中,从而对整体性能造成影响。这是因为进行了额外的内存拷贝过程,一旦优化不足则会极大影响性能。具体进行内存分配时我们使用了hwcontext,这是FFmpeg在3.0之后增加的一个功能。我们基于FFmpeg中hwcontext的机制实现了hwcontext_qsv,从而对硬件的初始化与内存分配进行很好的管理。
3、对比MSS与FFmpeg+QSV
下面我将分享MSS与FFmpeg+QSV的异同。二者支持相同的编解码器与视频处理。
二者的差异有:
1)MSS 仅提供了一套库和工具,用户必须基于 MSS进行二次开发;而FFmpeg 是一个流行的多媒体开放框架, QSV的GPU加速只是其中的一部分。
2)MSS的库中提供 了VPP 接口,用户要实现某些功能必须进行二次开发。而目前,FFmpeg+QSV已存在2个开发好的Filter,并且在Filter中集成了MSS 支持的所有功能,并提供更加简单的选项进行配置,这些功能对用户而言都是方便使用的。
3)在内存管理上,MSS的开发人员必须管理自己的内存;而FFmpeg 提供基本的内存管理单元并实现系统内存的统一调用,集成了硬件级别的内存处理机制。
4) FFmpeg 提供了一定的容错机制与 a/v 同步机制;FFmpeg+QSV 模块充分利用这些机制来提高兼容性,像使用ffmpeg的parse工具进行视频流预处理。
5)处理流程上,MSS的用户在使用MSS模块之前必须自己开发Mux/Demux或其他必要的模块;而FFmpeg+QSV 由于是基于 MSS 实现并添加了特殊的逻辑, 每个模块都可与 FFmpeg 的其他模块一起工作。
可以说FFmpeg有很强大的媒体支持,相对于传统的MSS在保证性能与质量的前提下为用户节省很多工作量并显著提升开发效率。
4、实践与测试
上图展示的是我们在Skylake也就是Gen 9上测试硬件转码能力的结果。GT2、GT31、GT41三个型号性能递增;TU1、TU2、TU4、TU7表示编解码性能与图像质量的均衡程度,其中TU7表示最快的处理速度和较差的图像质量,TU1表示基于大量计算得到的较高图像质量。
上图展示的是Skylake对HEVC支持的性能数据,其中的分辨率为1080P,其实HEVC 4K60p也能得到很好的性能。随着输出图像质量的提升,转码速度也会相应降低,但在正常使用中我们主要根据需求平衡性能与质量,在较短时间内实现较高质量的转码输出。
如果重点分析图像质量,在实践中我们建议使用Medium模式得到相对较优的性能与质量。随着参数的变化,PSNR与图像的整体细节会出现较明显变化。
Source Code主要有以下两种途径:可以从FFmpeg上直接clone,也可以访问Intel的Github获得相应源代码。Intel的github上的分支中的FFmpeg qsv模块是经过Intel的测试,相对而言问题更少运行更加稳定,大家也可以在Intel的Github上提出相关问题,我们会对部分问题进行解答。
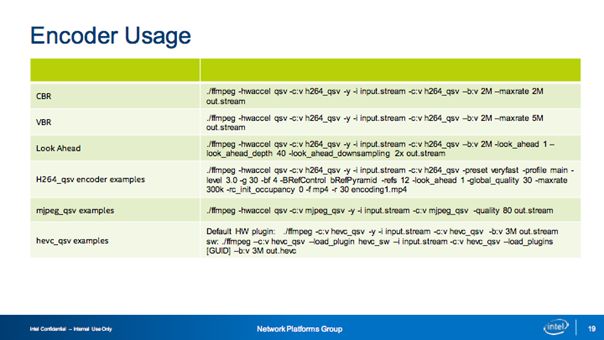
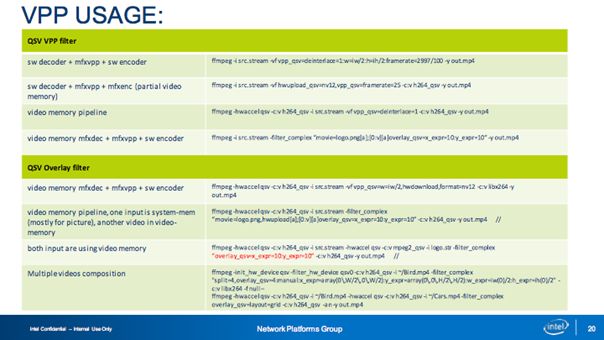

上图展示的是实践中可能需要的一些使用命令参考,其中我想强调的是Overlay Filter,在这里我们支持多种模式,包括插入台标的、电视墙等,也可在视频会议等场景中实现人工指定确定画面中每一个图片的位置等效果。
-
英特尔
+关注
关注
61文章
10320浏览量
181067 -
gpu
+关注
关注
28文章
5271浏览量
136060
原文标题:英特尔QSV技术在FFmpeg中的实现与使用
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
五家大厂盯上,英特尔EMIB成了?
吉方工控亮相2025英特尔技术创新与产业生态大会
创芯赋能智能生态!汇顶科技亮相2025英特尔技术创新与产业生态大会

英特尔举办行业解决方案大会,共同打造机器人“芯”动脉

向新而生,同“芯”向上!2025英特尔技术创新与产业生态大会在重庆举行

科通技术获评英特尔首批尊享级合作伙伴

英特尔锐炫Pro B系列,边缘AI的“智能引擎”

分析师:英特尔转型之路,机遇与挑战并存
新思科技与英特尔在EDA和IP领域展开深度合作
英特尔发布全新GPU,AI和工作站迎来新选择
英特尔以系统级代工模式促进生态协同,助力客户创新
英特尔持续推进核心制程和先进封装技术创新,分享最新进展
英特尔代工:明确重点广合作,服务客户铸信任



评论