 假设不懂数据科学,如何解决问题?
假设不懂数据科学,如何解决问题?
编者按:MIT博士、Salesforce前SVP、数据科学家Rama Ramakrishnan提醒,在从事数据科学项目时,养成首先创建基线的良好习惯,迅速交付价值,避免自我欺骗。
准备解决一个数据科学问题时,你可能很想单刀直入,直接开始创建模型。
别这么做。首先创建一个常识基线。
常识基线是指,假设你不懂数据科学,你会如何解决这个问题。假设你对监督学习、无监督学习、聚类、深度学习之类一无所知。现在问问你自己,如何解决手头的问题?
对于经验丰富的从业者而言,首先创建常识基线是常规操作。
他们会首先思考数据和问题,发展某种关于什么能使解决方案更好的直觉,以及考虑一些需要避免的地方。他们会和商业终端用户讨论,这些用户之前可能通过手工方式解决这个问题。
有经验的从业者会告诉你,常识基线不仅实现起来很简单,而且常常难以打败。即使数据科学模型确实战胜了这些基线,优势也可能很小。
直销邮件
让我们来看三个例子,从一个直销的例子开始。
你为一家服装零售商工作,手头有一个顾客数据库,其中包括了去年从你处买过东西的每个顾客的信息。
你希望给一些顾客发邮件,宣传最新的春装,预算可以支持给数据库中的100000名顾客发送邮件。
你应该选择哪100000个呢?
你大概已经在打算创建一个训练集和一个测试集,并训练一些监督学习模型了。也许是随机森林或梯度提升。甚至是深度学习。
这些都是很强大的模型,你的工具箱也应该常备这些。但是,先问自己一个问题:“如果这些方法都不存在,我必须靠自己的小聪明解决这个问题,那么我该如何挑选出这100000个顾客?”
常识告诉你,应该选择那些最忠诚的顾客,毕竟,他们是最可能对邮件感兴趣的人。(不过,其实这个问题也可以从增量建模(Uplift Modeling)的角度考虑,可能不管你发不发邮件,最忠诚的顾客总是倾向于到你这儿买东西,反而是给不那么忠诚的顾客发邮件,增量更高。)
那么,你将如何衡量忠诚度呢?直观地说,忠诚顾客倾向于多购买,多花钱。所以你可以计算每位顾客去年在你那里花了多少钱,到你那里买过多少次东西?
如此计算之后,查看下结果,你会发现它很好地描述了忠诚度。但是你也注意到,这样会选中那些在上半年很忠诚、下半年“失踪”的客户。
通过查看顾客在你处的最近购买情况,可以修正这一问题。如果花费和购买频率相似,那么昨天在你处买东西的顾客,价值比11个月前购买过的顾客要高。
总结一下,你为每位顾客计算:
过去12个月在你处的花销
过去12个月在你处发生的交易数量
上一次交易到现在有几周
你可以基于上面的三个测度排序顾客列表:
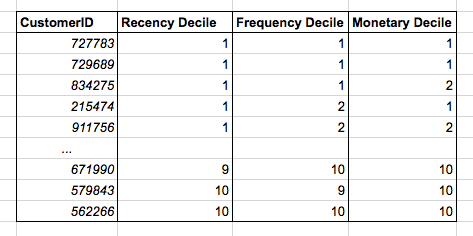
测度转换为10分制(十分位)
选中其中的前100000名顾客。
恭喜!你刚刚发现的是价值很高的RFM(Recency-Frequency-Monetary)启发式算法,直销领域久经考验的主力算法。
万一你好奇R、F、M中哪个最重要,据研究R最重要。
RFM方法易于创建,易于解释,易于使用。最妙的是,它出人意料地有效。有经验的直销从业者会告诉你,即使当更复杂的模型战胜RFM的时候,两者之间的差距也比你想象的要小得多,让你怀疑是否有必要构建复杂模型。
推荐系统
接下来,我们来看一个推荐系统的例子。
你工作的服装零售商有一家电商网站,需要你创建产品推荐区域,该区域将显示在首页上。
服装推荐需要个性化——如果访问者之前访问过你的站点,你需要基于历史数据推荐符合他们口味的商品。
有些书整本都在讨论这一主题,而GitHub上也有许多专门为此开发的库。你是不是应该直接开始应用矩阵分解(点击阅读)?
到了一定时候你大概应该尝试下矩阵分解,但刚开始你不应该直接应用矩阵分解。你首先应该创建一个常识基线。
向访问者展示相关商品的最简单的方案是什么?
畅销商品!
是的,它们并不是个性化的。但是畅销商品之所以是畅销商品,正是因为有足够的访问者购买了它们。所以从这个意义上说,很大可能至少相当一部分访问者会对这些商品感兴趣,即使这些商品并不是根据访问者的兴趣定制的。
此外,不管怎么说,你都需要准备好显示畅销商品,毕竟你需要向没有数据的初次访问者展示一些东西。
选中畅销商品很简单。确定一个时间窗口(最近24小时、最近7天、……),确定一项测度(利润、访问量、……),确定计算周期(每小时、每日、……),编写查询请求并加以自动化。
并且你可以调整这一基线,稍稍加上一点个性化。比如说,如果记住了访问者上次访问站点浏览的商品类别,那么你可以直接从这一具体类别中选出畅销商品(而不是选出所有类别的畅销商品),在推荐区域展示。例如,上次访问时浏览过女装类别的访问者,可以向她展示畅销女装。
需要澄清的是,上面描述的“调整”涉及开发工作,因为你需要“记住”不同访问会话的信息。但是,如果你计划创建、交付基于模型的个性化推荐,那么这些收集信息的开发工作是免不了的。
定价优化
最后一个例子是零售定价优化。
作为一个服装零售商,你贩卖季节性商品——例如,毛衣——在季节末,需要清库存,以便为下一季的商品留出空间。服装业对此的标准做法是减价促销。
如果折扣太小,最后时刻你将不得不以废品回收的价格出清积压的季节性商品。如果折扣太大,季节性商品会很快售罄,但是你损失了赚取更多金钱的机会。
在服装行业,平衡这两者的艺术称为清仓优化或减价优化。
有大量关于如何使用数据科学技术建模和求解这一问题的文献(例如,牛津价格管理手册的第25章,利益申明:这书是我写的)。但是让我们首先考虑下如何创建一个常识基线。
想象一下,手头有100单位的毛衣,这一季还有4周。每周可以调一次价,也就是说你有4次出手调整的机会。
你应该从本周就开始减价吗?
好吧,首先考虑下,你觉得如果维持价格不变,下面4周可以卖掉多少单位毛衣?
我们如何估计这一数值?最简单的做法是看看上一周卖了多少。
假定上一周卖了15单位。如果接下来4周和上一周情况差不多,那么我们将卖出60单位,到了季节末会积压40单位。
不妙。明显需要减价。
零售商有时使用折扣阶梯,八折、七折、六折……最简单的做法是首先迈上折扣阶梯的第一阶,也就是下周开始八折促销。
快进一周。比方说卖掉了20单位,剩下80单位和3周。假设剩下3周维持相同的卖出率(例如,20单位每周),总共将卖出60单位,季节末仍将积压20单位。所以你需要在折扣阶梯上往下走一阶,下周开始增加促销力度,改为七折出售。
以此类推,在每周重复以上策略,直到季节末。
取决于卖出率对折扣的响应程度,不同的商品可能遵循不同的折扣路径。比如,相比下图中的商品A,商品B需要更大力度的折扣刺激。
这一常识基线可以通过非常简单的if-then逻辑实现。和上面的个性化推荐例子一样,我们也可加以调整(例如,之前我们直接使用上一周的销售单位数“预测”未来几周的销售量,但是我们也可以转而使用前几周的平均销售量)。
搞定了基线之后,你可以勇往直前,释放数据科学的全部火力。但是不管你做了什么,都需要将所得结果与基线进行比较,从而精确地评估工作的回报。
结语
在很多问题上,古老的二八法则仍然适用。常识基线经常能够让你以很快的速度取得80%的价值。
随着越来越多数据科学技术的应用,你将看到更高的价值,但价值增长的速度越来越慢。取决于具体情况,你当然可以决定使用一个复杂方案榨取最后一点价值。不过你应该在很清楚增加的成本和收益的前提下才这么做。
常识基线能从根本上保护你避免理查德·费曼提到的著名危险:
首要原则是,你千万不能愚弄自己,最容易被愚弄的人是你自己。
创建数据科学模型可能是一个非常享受的过程,你很容易哄骗自己,你所创建的复杂、倾注了很多心血、精心调整的模型(从成本/收益角度上而言)更好,而实际上并没有那么好。
常识基线能够迅速交付价值,也能避免自我欺骗。请养成首先创建基线的好习惯。
-
深度学习
+关注
关注
73文章
5527浏览量
121832 -
数据科学
+关注
关注
0文章
168浏览量
10176
原文标题:数据科学项目的第一步:创建常识基线
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐









 工商网监
工商网监
评论