 基于NumPy创建一个可以工作的神经网络
基于NumPy创建一个可以工作的神经网络
编者按:和Piotr Skalski一起,基于NumPy手写神经网络,通过亲自动手实践,加深对神经网络内部机制的理解。
Keras、TensorFlow、PyTorch等高层框架让我们可以快速搭建复杂模型。然而,花一点时间了解下底层概念是值得的。前不久我发过一篇文章,以简单的方式解释了神经网络是如何工作的。但这是一篇高度理论性的文章,主要以数学为主(数学是神经网络超能力的来源)。我打算以实践的方式继续这一主题,在这篇文章中,我们将尝试仅仅基于NumPy创建一个可以工作的神经网络。最后,我们将测试一下创建的模型——用它来解决简单的分类问题,并和基于Keras搭建的神经网络比较一下。
显然,今天的文章会包含很多Python代码,我希望你不会因此觉得枯燥。我同时也把文中所有的代码发在GitHub上:SkalskiP/ILearnDeepLearning.py
概览
在开始编程之前,先让我们准备一份基本的路线图。我们的目标是创建一个特定架构(层数、层大小、激活函数)的密集连接神经网络。然后训练这一神经网络并做出预测。
上面的示意图展示了训练网络时进行的操作,以及单次迭代不同阶段需要更新和读取的参数。
初始化神经网络层
让我们从初始化每一层的权重矩阵W和偏置向量b开始。下图展示了网络层l的权重矩阵和偏置向量,其中,上标[l]表示当前层的索引,n表示给定层中的神经元数量。
我们的程序也将以类似的列表形式描述神经网络架构。列表的每一项是一个字典,描述单个网络层的基本参数:input_dim是网络层输入的信号向量的大小,output_dim是网络层输出的激活向量的大小,activation是网络层所用的激活函数。
nn_architecture = [
{"input_dim": 2, "output_dim": 4, "activation": "relu"},
{"input_dim": 4, "output_dim": 6, "activation": "relu"},
{"input_dim": 6, "output_dim": 6, "activation": "relu"},
{"input_dim": 6, "output_dim": 4, "activation": "relu"},
{"input_dim": 4, "output_dim": 1, "activation": "sigmoid"},
]
如果你熟悉这一主题,你的脑海中大概已经回荡起焦急的声音:“喂喂!搞错了!这里有些是不必要的……”这一次,你内心的声音是对的,一个网络层的输出向量同时也是下一层的输入,所以其实只用列出两者之一就够了。不过,我故意使用这样的表示法,使每一层的格式保持一致,也让初次接触这一主题的人更容易理解代码。
def init_layers(nn_architecture, seed = 99):
np.random.seed(seed)
number_of_layers = len(nn_architecture)
params_values = {}
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
layer_input_size = layer["input_dim"]
layer_output_size = layer["output_dim"]
params_values['W' + str(layer_idx)] = np.random.randn(
layer_output_size, layer_input_size) * 0.1
params_values['b' + str(layer_idx)] = np.random.randn(
layer_output_size, 1) * 0.1
return params_values
上面的代码初始化了网络层的参数。注意我们用随机的小数字填充矩阵W和向量b。这并不是偶然的。权重值无法使用相同的数字初始化,否则会造成破坏性的对称问题。基本上,如果权重都一样,不管输入X是什么,隐藏层的所有单元也都一样。这样,我们就会陷入初始状态,不管训练多久,网络多深,都无望摆脱。线性代数不会原谅我们。
小数值增加了算法的效率。我们可以看看下面的sigmoid函数图像,大数值处的函数图像几乎是扁平的,这会对神经网络的学习速度造成显著影响。所有参数使用小随机数是一个简单的方法,但它保证了算法有一个足够好的开始。
激活函数
激活函数只需一行代码就可以定义,但它们给神经网络带来了非线性和所需的表达力。“没有它们,神经网络将变成线性函数的组合,也就是单个线性函数。”激活函数有很多种,但在这个项目中,我决定使用其中两种——sigmoid和ReLU。为了同时支持前向传播和反向传播,我们还需要准备好它们的导数。
def sigmoid(Z):
return1/(1+np.exp(-Z))
def relu(Z):
return np.maximum(0,Z)
def sigmoid_backward(dA, Z):
sig = sigmoid(Z)
return dA * sig * (1 - sig)
def relu_backward(dA, Z):
dZ = np.array(dA, copy = True)
dZ[Z <= 0] = 0;
return dZ;
前向传播
我们设计的神经网络有一个简单的架构。输入矩阵X传入网络,沿着隐藏单元传播,最终得到预测向量Y_hat。为了让代码更易读,我将前向传播拆分成两个函数——单层前向传播,和整个神经网络前向传播。
def single_layer_forward_propagation(A_prev, W_curr, b_curr, activation="relu"):
Z_curr = np.dot(W_curr, A_prev) + b_curr
if activation is"relu":
activation_func = relu
elif activation is"sigmoid":
activation_func = sigmoid
else:
raiseException('Non-supported activation function')
return activation_func(Z_curr), Z_curr
这部分代码大概是最直接,最容易理解的。给定来自上一层的输入信号,我们计算仿射变换Z,接着应用选中的激活函数。基于NumPy,我们可以对整个网络层和整批样本一下子进行矩阵操作,无需迭代,这大大加速了计算。除了计算结果外,函数还返回了一个反向传播时需要用到的中间值Z。
基于单层前向传播函数,编写整个前向传播步骤很容易。这是一个略微复杂一点的函数,它的角色不仅是进行预测,还包括组织中间值。
def full_forward_propagation(X, params_values, nn_architecture):
memory = {}
A_curr = X
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
A_prev = A_curr
activ_function_curr = layer["activation"]
W_curr = params_values["W" + str(layer_idx)]
b_curr = params_values["b" + str(layer_idx)]
A_curr, Z_curr = single_layer_forward_propagation(A_prev, W_curr, b_curr, activ_function_curr)
memory["A" + str(idx)] = A_prev
memory["Z" + str(layer_idx)] = Z_curr
return A_curr, memory
损失函数
损失函数可以监测进展,确保我们向着正确的方向移动。“一般来说,损失函数是为了显示我们离‘理想’解答还有多远。”损失函数根据我们计划解决的问题而选用,Keras之类的框架提供了很多选项。因为我计划将神经网络用于二元分类问题,我决定使用交叉熵:
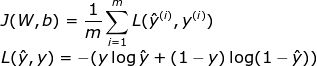
为了取得更多关于学习过程的信息,我决定另外实现一个计算精确度的函数。
def get_cost_value(Y_hat, Y):
m = Y_hat.shape[1]
cost = -1 / m * (np.dot(Y, np.log(Y_hat).T) + np.dot(1 - Y, np.log(1 - Y_hat).T))
return np.squeeze(cost)
def get_accuracy_value(Y_hat, Y):
Y_hat_ = convert_prob_into_class(Y_hat)
return (Y_hat_ == Y).all(axis=0).mean()
反向传播
不幸的是,很多缺乏经验的深度学习爱好者都觉得反向传播很吓人,难以理解。微积分和线性代数的组合经常会吓退那些没有经过扎实的数学训练的人。所以不要过于担心你现在还不能理解这一切。相信我,我们都经历过这个过程。
def single_layer_backward_propagation(dA_curr, W_curr, b_curr, Z_curr, A_prev, activation="relu"):
m = A_prev.shape[1]
if activation is"relu":
backward_activation_func = relu_backward
elif activation is"sigmoid":
backward_activation_func = sigmoid_backward
else:
raiseException('Non-supported activation function')
dZ_curr = backward_activation_func(dA_curr, Z_curr)
dW_curr = np.dot(dZ_curr, A_prev.T) / m
db_curr = np.sum(dZ_curr, axis=1, keepdims=True) / m
dA_prev = np.dot(W_curr.T, dZ_curr)
return dA_prev, dW_curr, db_curr
人们经常搞混反向传播和梯度下降,但事实上它们不一样。前者是为了高效地计算梯度,后者则是为了基于计算出的梯度进行优化。在神经网络中,我们计算损失函数在参数上的梯度,但反向传播可以用来计算任何函数的导数。反向传播算法的精髓在于递归地使用求导的链式法则,通过组合导数已知的函数,计算函数的导数。下面的公式描述了单个网络层上的反向传播过程。由于本文的重点在实际实现,所以我将省略求导过程。从公式上我们可以很明显地看到,为什么我们需要在前向传播时记住中间层的A、Z矩阵的值。
和前向传播一样,我决定将计算拆分成两个函数。之前给出的是单个网络层的反向传播函数,基本上就是以NumPy方式重写上面的数学公式。而定义完整反向传播过程的函数,主要是读取、更新三个字典中的值。
def full_backward_propagation(Y_hat, Y, memory, params_values, nn_architecture):
grads_values = {}
m = Y.shape[1]
Y = Y.reshape(Y_hat.shape)
dA_prev = - (np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat));
for layer_idx_prev, layer in reversed(list(enumerate(nn_architecture))):
layer_idx_curr = layer_idx_prev + 1
activ_function_curr = layer["activation"]
dA_curr = dA_prev
A_prev = memory["A" + str(layer_idx_prev)]
Z_curr = memory["Z" + str(layer_idx_curr)]
W_curr = params_values["W" + str(layer_idx_curr)]
b_curr = params_values["b" + str(layer_idx_curr)]
dA_prev, dW_curr, db_curr = single_layer_backward_propagation(
dA_curr, W_curr, b_curr, Z_curr, A_prev, activ_function_curr)
grads_values["dW" + str(layer_idx_curr)] = dW_curr
grads_values["db" + str(layer_idx_curr)] = db_curr
return grads_values
基于单个网络层的反向传播函数,我们从最后一层开始迭代计算所有参数上的导数,并最终返回包含所需梯度的python字典。
更新参数值
反向传播是为了计算梯度,以根据梯度进行优化,更新网络的参数值。为了完成这一任务,我们将使用两个字典作为函数参数:params_values,其中保存了当前参数值;grads_values,其中保存了用于更新参数值所需的梯度信息。现在我们只需在每个网络层上应用以下等式即可。这是一个非常简单的优化算法,但我决定使用它作为更高级的优化算法的起点(大概会是我下一篇文章的主题)。
def update(params_values, grads_values, nn_architecture, learning_rate):
for idx, layer in enumerate(nn_architecture):
layer_idx = idx + 1
params_values["W" + str(layer_idx)] -= learning_rate * grads_values["dW" + str(layer_idx)]
params_values["b" + str(layer_idx)] -= learning_rate * grads_values["db" + str(layer_idx)]
return params_values;
整合一切
万事俱备只欠东风。最困难的部分已经完成了——我们已经准备好了所需的函数,现在只需以正确的顺序把它们放到一起。
def train(X, Y, nn_architecture, epochs, learning_rate):
params_values = init_layers(nn_architecture, 2)
cost_history = []
accuracy_history = []
for i in range(epochs):
Y_hat, cashe = full_forward_propagation(X, params_values, nn_architecture)
cost = get_cost_value(Y_hat, Y)
cost_history.append(cost)
accuracy = get_accuracy_value(Y_hat, Y)
accuracy_history.append(accuracy)
grads_values = full_backward_propagation(Y_hat, Y, cashe, params_values, nn_architecture)
params_values = update(params_values, grads_values, nn_architecture, learning_rate)
return params_values, cost_history, accuracy_history
大卫对战歌利亚
该是看看我们的模型能不能解决一个简单的分类问题的时候了。我生成了一个包含两个分类的数据点的数据集,如下图所示。
作为对比,我用高层框架Keras搭建了一个模型。两个模型采用相同的架构和学习率。不过这仍然是一场不公平的较量,因为我们的模型用的都是最简单的方案。最终,基于NumPy和Keras的模型在测试集上都取得了类似的精确度(95%)。不过,我们的模型收敛的速度要慢很多倍。在我看来,这主要是因为我们的模型缺乏恰当的优化算法。
再见
希望我的文章拓展了你的视野,增加了你对神经网络内部运作机制的理解——这将是对我投入精力撰写本文的最好回报。我在编写代码和说明的时候也学到了很多东西,亲自动手实践能让你学到很多东西。
如你有任何疑问,或者找到了代码中的错误,请留言告知。如果你喜欢这篇文章,可以在Twitter(PiotrSkalski92)和Medium(piotr.skalski92)上关注我,也可以上GitHub(SkalskiP)和Kaggle(skalskip)查看我的其他项目。本文是“神经网络的奥秘”系列的第三篇,如果你还没有读过前两篇,可以看一下https://towardsdatascience.com/preventing-deep-neural-network-from-overfitting-953458db800a
保持好奇心!
-
神经网络
+关注
关注
42文章
4779浏览量
101148 -
python
+关注
关注
56文章
4807浏览量
85020 -
keras
+关注
关注
2文章
20浏览量
6095
原文标题:只用NumPy实现神经网络
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工神经网络原理及下载
【PYNQ-Z2试用体验】神经网络基础知识
【PYNQ-Z2试用体验】基于PYNQ-Z2的神经网络图形识别[结项]
卷积神经网络如何使用
【案例分享】ART神经网络与SOM神经网络
如何移植一个CNN神经网络到FPGA中?
神经网络移植到STM32的方法
基于Numpy实现同态加密神经网络
基于Numpy实现神经网络:反向传播

基于Numpy实现神经网络:如何加入和调整dropout?






 工商网监
工商网监
评论