 一种从视频中学习技能的框架(skills from videos,SFV)
一种从视频中学习技能的框架(skills from videos,SFV)

无论是日常简单的动作还是令人惊叹的杂技,人类可以通过观察别人的动作学会一系列惊人的技能。今天如果你想要学习新的技能,像YouTube一样的视频网站上拥有丰富的资源供你学习。
但遗憾的是,对于机器来说通过大量的视觉数据来进行技能学习依然面临着很大的挑战。目前绝大多数的模仿学习需要精确的动作记录,例如精密的动作捕捉系统。但获取动作捕捉数据很多时候十分复杂,极大的依赖于设备,将环境局限于于室内无遮挡的场景,这限制了可以被记录的技能类型。那么如果存在一个智能体可以从视频中学习技能就好了!
在这一工作中,伯克利BAIR的研究人员提出了一种从视频中学习技能的框架(skills from videos,SFV),结合了前沿的计算机视觉和强化学习技术构建的系统可以从视频中学习种类繁多的技能,包括后空翻和很滚翻等高难度动作。同时智能体还学会了在仿真物理环境中复现这些技能的策略,而无需任何的手工位姿标记。
SFV问题在计算机图形学领域一直受到广泛关注,先前的技术主要依靠手工的控制结构来限制可以产生的行为,这使得主体可以学习到的技能非常有限,同时表现出来的动作也很不自然。近年来,深度学习技术在视觉模仿邻域取得了很大的进展,包括Atari游戏和简单的机器人任务都取得的不错的成绩,但这些任务在所描述的与主体运行的环境只有些许的不同,并且所得到的结果也只是相对简单的动力学过程。
基于深度学习视觉模仿的Atrai和简单的机器人任务
框 架
研究人员提出的系统由三个部分构成:位姿估计、运动重建和运动模仿。
-首先利用输入的视频实现位姿估计,从每一帧中预测出主角的位姿;
-随后在运动重建阶段,将上一阶段预测的位姿进行衔接得到参考的运动过程,并修正一些在位姿估计阶段的缺陷;
-最终将参考运动过程传输给模仿阶段,模拟的主体将会利用强化学习来训练模仿这些动作。
这一框架主要包括位姿估计、运动重建和运动模仿三个过程
位姿估计
研究人员利用基于视觉的运动估计器来预测给定视频中主角的在每一帧的运动。位姿估计器利用人体网格恢复中的方法来构建,利用了弱监督对抗的方法训练从单目图像中预测出位姿。
从视频中恢复人体位姿
虽然在训练位姿估计器的时候需要进行位姿标记,但在训练完成后它就可以用于新的图像而无需额外的标记。
基于视觉的位姿估计器从每一帧中预测出主角的动作
运动重建
由于基于单帧图像预测的位姿是不连续的,在上图中可以看到明显不连贯的动作。同时由于估计器某些错误估计的存在会产生一系列奇异结果造成估计的位姿出现跳变。这会造成智能体在物理上无法模仿。所以运动重建的目的就在于减轻上述原因带来的影响,得到更为符合物理实际的参考运动,以便于智能体模拟。所以研究人员提出了下面的目标函数来优化新的参考运动:
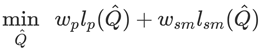
其中保证了参考运动与原始运动接近,而则保证了相邻帧之间运动相近以便得到更加平滑的运动结果,这两个损失对应了不同的权重w。
经过优化后的参考运动结果如下,可以看到明显地改善了位姿之间的连续性,让生成的运动估计更为平滑。
运动模仿
在获取了参考运动序列后,就可以训练智能体来模拟这些技能了。研究人员使用了强化学习来训练智能体学习这些技能,其中奖励函数也十分简单,主要用于鼓励智能体采取不断减小t时刻与每一帧参考运动位姿之间差距的策略。
虽然简单,但得到了很好的结果。智能体学会了一系列高难度动作,从不同的技能视频片段中学会了不同的技能。
来一个侧手翻
再来一个前空翻
鲤鱼打挺也不赖
嘿!看我的回旋踢!
结果
在训练完成后,这一智能体可以学会从youtube中收集的20中不同的技能。
能唱能跳、能翻滚跳跃、武术也不在话下。
甚至对于与视频中主角人类在形态上很不相似的Atlas机器,这一策略依然十分有效。
研究人员同时还发现,模拟智能体学习到的行为具有很强的泛化性。在新的环境中依旧可以学习如何适应崎岖的地面。
运动平滑而又稳定
这一研究取得良好效果的关键在于,将SFV这一复杂问题分解成多个可控的部分,并选取合适的方法来解决这些问题,并将他们有机高效的结合起来。然而这一领域依旧面临着很大挑战,下面就是一个学习失败的例子:
但这一工作依旧表明,充分合理地利用已有的技术我们可以在充满挑战的问题中得到不错的结果。希望这一研究可以启发小伙伴们对于相关领域的研究。
-
计算机视觉
+关注
关注
9文章
1715浏览量
47711 -
智能体
+关注
关注
1文章
552浏览量
11642 -
Youtube
+关注
关注
0文章
144浏览量
17407
原文标题:看看Youtube就能学会杂技,伯克利新算法让智能体学会高难度动作
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI智能体中的Skills是什么?

一种基于图像平移的目标检测框架
一种基于Deep U-Net的多任务学习框架
一种用深度学习框架对普通视频进行流畅稳定的慢动作回放的技术

实现机器学习的一种重要框架是深度学习
最新机器学习开源项目Top10
一种基于框架特征的共指消解方法

一种用于交通流预测的深度学习框架

一个通用的时空预测学习框架

模力方舟现已正式开源官方Skills仓库Moark Skills




评论