 深度解读Gating类型自动混音技术(2)
深度解读Gating类型自动混音技术(2)
在上一篇 “Gating自动混音器(一)“,我们已经了解了Gating自动混音器是干什么用的,它主要解决的问题是什么。在有多个麦克风的场景下,传统的做法是将多个麦克风混音输出到音箱。这样的做法不可取,它可能导致的问题是,一、及其容易产生啸叫,因为2路信号混音,总输出增加3dB,更何况多支呢。二、即使可以通过增益比例去控制每只麦克风在总输出中占的比例,以达到总输出不增加的目的,也非常容易导致说话人说话的声音太小,听不清楚。基于以上原因,才会有自动混音的出现,自动混音彻彻底底地解决了根本问题。自动混音分为Gain-Sharing(增益共享)和Gating(门限)两种类型,现在所讲的是Gating类型自动混音。
上一期已经讲了Gating自动混音所应具备的一些基本参数及含义,留下了一个关键点,自适应噪声阈值如何获取?在开始之前,先来看看为什么门限自动混音可以解决上边提到的问题。
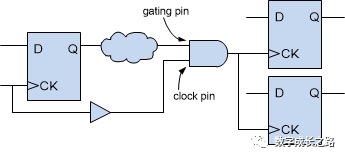
从图中可以看出,每只麦克风都有个Gate(门),当麦克风信号超过这个门限以后,才会导通信号。通过的信号和普通混音无异,混音之后通过一个由NOM(打开的麦克风数量)控制的衰减因子,达到总输出不变的目的。 在多只麦克风的情况下,不会存在每个人都会在同时说话,正在同时说话的麦克风只有那么1-3只而已。其他未说话的麦克风将被关闭,不会被导通。这样既可以保证总输出不产生反馈,每只麦克风说话的声音又可以听得清楚。
NOM:Number Of Open Mics. 算法实时计算打开的麦克风数量,如果大于NOM Limits 设定的数量,新打开的麦克风将从已经打开的麦克风中抢占优先级最低的一个, 如果没有找到,该麦克风不会被导通, NOM Limits起到一个限制作用。
在这里面,Gate是关键,如何保证麦克风有信号的时候被打开,没有人说话就不会被打开。简单一点,可以采用对每一只麦克风设置一个开关阈值,信号超过阈值的时候就导通,小于阈值就关闭。 在很久以前,就是这么做的,并且使用了很长的一段时间。此方法不是特别的方便,环境噪音提高了,必须得手动去调整阈值。
在尝试中,我考虑了2种方法:
1. 人声检测 , 只有说话的时候才被打开,不说话关闭 。
2. RMS电平检测。
在DSP系统中,除了能实现模块功能,另一个最重要的就是资源了。这个算法占用的CPU资源类不应超过5%, 人声检测不能采用太过复杂的基于统计模型的算法,一个麦克风需要检测一次,共有32个麦克风,这将势必不可取。后来尝试了短时过零率和短时能量等方法。结果不太理想,应该来说检测结果不太理想,有时说话了确不出声,一句话的前面几个字像被吃掉了一样。 总结来说,短时过零率等方法并不能准确判断语音,第二个这类检测方法都需要延时缓冲,大概10ms检测数据,吃字也是正常的。 被抛弃的想法就不细说了,有兴趣的可以看看相关资料。
采用RMS检测方法, RMS我们都知道,就是均方根嘛。相对来说算法简单易实现, 根据过去一段时间的RMS值作为该麦克风的参考噪声阈值。这里面最重要的就是时间的选取,要反应的是过去的噪声水平,而不是有信号的状态。语音信号属于非平稳信号,利用这一特点应取最小值。记为瞬态RMS, N取值30ms对应的采样值。 T为噪声阈值,等于过去的K帧RMS最小值, K值根据实际情况调节。
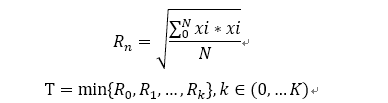
K 取值依据,应大于说话尾音所能持续的时间,正常说话一个字也就100多ms,字与字之间会出现停顿,噪声阈值的依据也就是停顿期间的噪声水平。说一个情况,同事在测试期间,一个字不停的拖尾音,喂……….,持续10几秒。这种情况导致算法提高了噪声阈值,刚开始可以导通,之后的喂出不了声。 那么这个K值应取得更大,K*30ms 需要大于最大能持续的时间才能检测到空隙。
根据测试情况,RMS方法可以作为自适应噪声阈值判断的方法。在测试中,会存在另外一种情况,一只麦克风说话时,另一只麦克风采集到了音箱扩声的信号被打开。如果NOM Limit设置成1,只允许一个麦克风打开。采集信号的麦克风就会抢占说话的麦克风,引起两个麦克风互相切换。此时,应调节2个参数,一是保持时间,第二个灵敏度。
保持时间,停止说话后,该麦克风保持多久才关闭,改时间要设置得比混响传递时间大一点。
灵敏度,实际上信号超过自适应噪声阈值+灵敏度才能判定为可以打开麦克风。灵敏度需要设置高一点,即使有反馈也不会轻易打开话筒。
以上就是Gating自动混音的全部内容,代码就不贴了,也没什么意义,关键还是思路吧。
-
麦克风
+关注
关注
15文章
649浏览量
55118 -
混音
+关注
关注
0文章
6浏览量
7721 -
混音器
+关注
关注
2文章
28浏览量
13162
原文标题:Gating 自动混音(二)
文章出处:【微信号:ddongcloud,微信公众号:嵌入式DSP】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
clock-gating的综合实现
浅析clock gating模块电路结构
基于数字语音教室的多路混音算法及应用Multi-Point

构建一个简单的模拟音频混音器

深度解读智能汽车车载传感器标定技术
AND GATE的clock gating check简析





 工商网监
工商网监
评论