 TrellisNet在CNN和RNN间架起了一座桥梁
TrellisNet在CNN和RNN间架起了一座桥梁
长期以来,序列建模一直是循环神经网络(RNN)的天下。然而,近年来,卷积神经网络(CNN)开始入侵这一RNN的保留领地,在建模长距离上下文方面表现尤为出色。这两年来,更出现了独立于RNN和CNN之外的完全基于自注意力机制的模型。
CMU和Intel的研究人员Shaojie Bai、J. Zico Kolter、Vladlen Koltun刚刚(2018年10月15日)发布了论文Trellis Networks for Sequence Modeling,提出了一种新颖的架构——网格网络(TrellisNet)。网格网络的结构融合了CNN和RNN,因此可以直接吸收许多为CNN和RNN设计的技术,从而在多项序列建模问题上战胜了当前最先进的CNN、RNN、自注意力模型。
TrellisNet架构
TrellisNet的基本单元如下图所示:
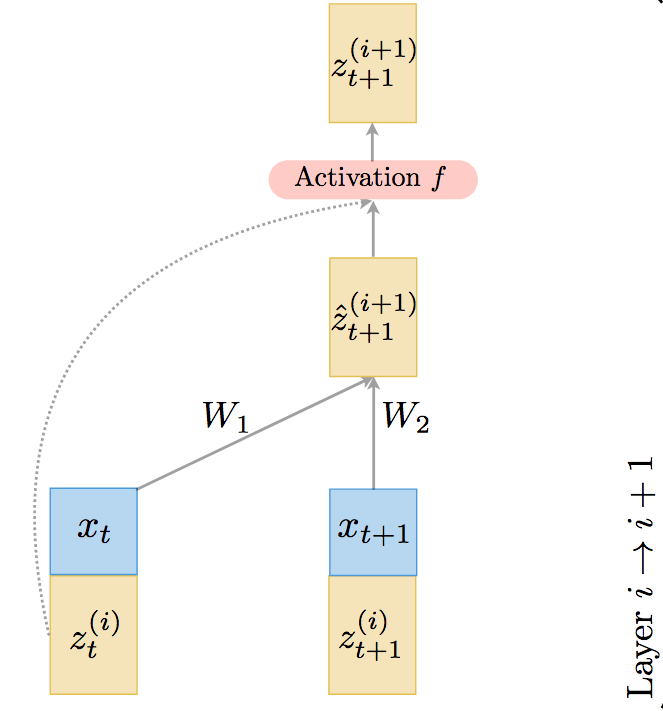
上图中,t表示时刻,i表示网络层,W表示权重,x表示序列输入(蓝色),z表示隐藏状态(黄色)。可以看到,这一基本构件的输入是前一层i在t、t+1时刻的隐藏状态,以及t、t+1时刻的输入向量。
这些输入经过前馈线性变换(省略了偏置):
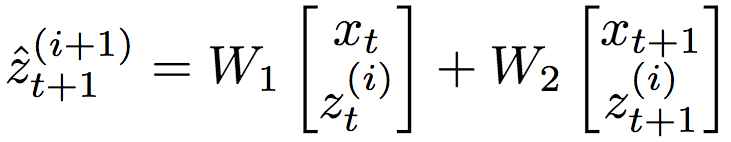
和前一层t时刻的隐藏状态一起传给非线性激活函数f:
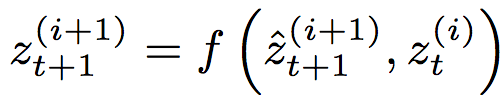
平铺上述单元,我们就得到了完整的TrellisNet:
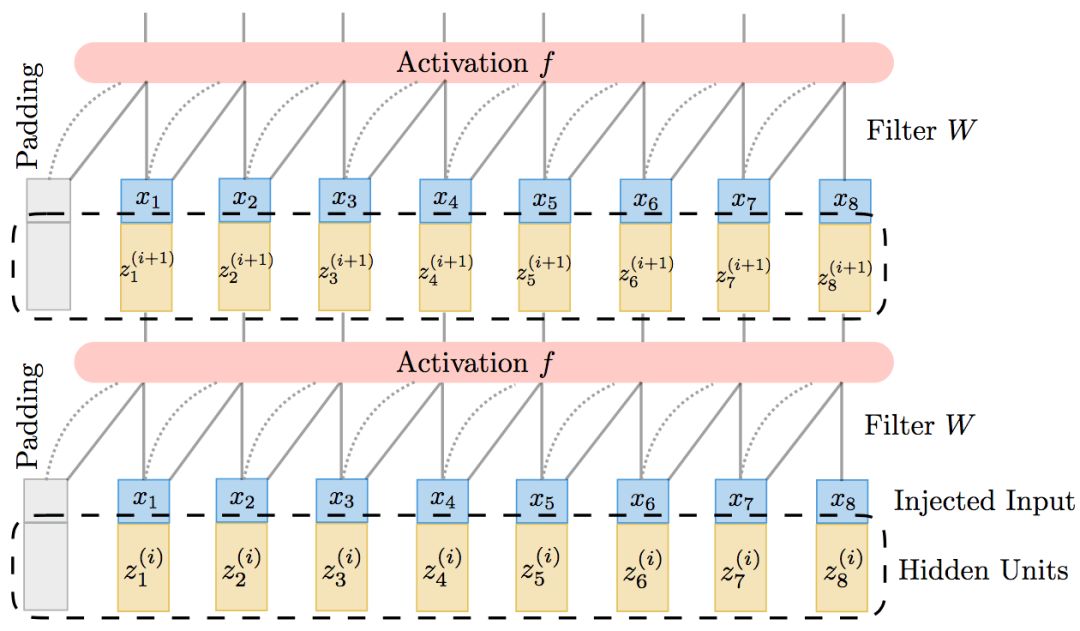
注意,所有时刻和网络层的权重都是一样的,这也是TrellisNet的一个重要特征。
顺便提一下,由于TrellisNet每层都接受(相同的)输入序列x1:T作为(部分)输入,我们可以预先计算输入序列的线性变换:
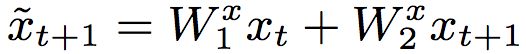
然后在所有网络层使用。
TrellisNet和CNN
回过头去看下完整的TrellisNet示意图,可以看到,其实TrellisNet的每一层,都可以视为对隐藏状态序列进行一维卷积运算,然后将卷积输出传给激活函数。也就是说,TrellisNet的网络层i的运算可以总结为:
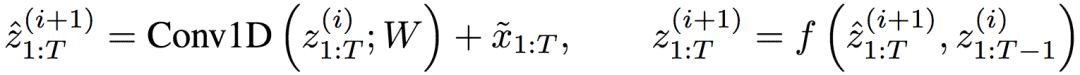
这就意味着TrellisNet可以看成一种特殊的CNN,随着网络层的加深,感受野也随之增大。
不过,TrellisNet和一般的(时序)CNN有两个地方不一样:
如前所述,所有时刻和网络层的权重是一样的。换句话说,所有网络层共享过滤矩阵。这样的权重系联大大降低了模型的尺寸,而且可以看成一种正则化(更稳定的训练、更好的概括性)。
(线性变换后的)输入序列直接插入每个隐藏层。输入序列的插入混合了深层特征和原始序列。
相应地,TrellisNet也可以直接应用一些为CNN设计的技术:
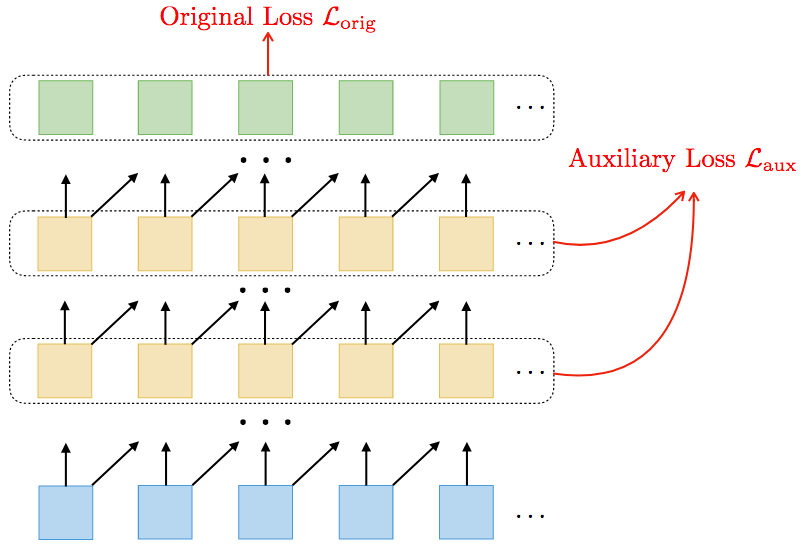
深度监督。深度监督技术使用CNN的中间层损失作为辅助,即
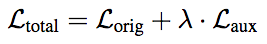
(λ是固定参数,控制辅助损失的权重)。
例如,在训练一个L层TrellisNet的过程中,为了预测t时刻的输出,除了最后一层的zt(L)外,我们可以同时在zt(L-l)、zt(L-2l)等隐藏状态上应用损失函数。
空洞卷积。在CNN中应用空洞卷积可以更快地扩大感受野。TrellisNet可以直接应用这一技术。注意,如果我们改动了核大小或卷积设定,TrellisNet的激活函数f可能需要做相应调整。例如,假设空洞为d,核大小为2,则激活函数需调整为
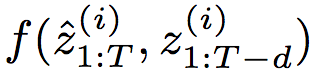
权重归一化。在卷积核上应用权重归一化(WN)能起到正则化作用,并加速收敛。
并行。TrellisNet同样可以利用并行卷积操作。
TrellisNet和RNN
RNN和CNN看起来完全不一样。CNN的每个网络层并行操作序列的所有元素,而RNN每次处理序列的一个元素,并在时间上展开。
然而,论文作者证明了,任何展开至有限长度的RNN等价于核矩阵W使用特别的稀疏结构的TrellisNet:
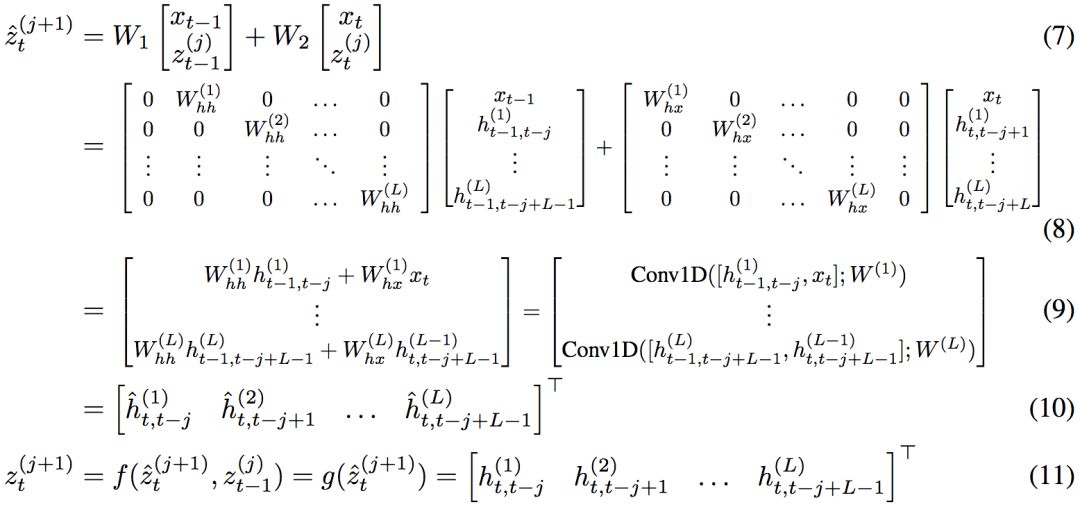
论文作者以一个双层RNN为例,演示了两者的等价性。TrellisNet的每个单元同时表示3个RNN单元(输入xt、第一层的隐藏向量ht(1)、第二层隐藏向量ht(2))。
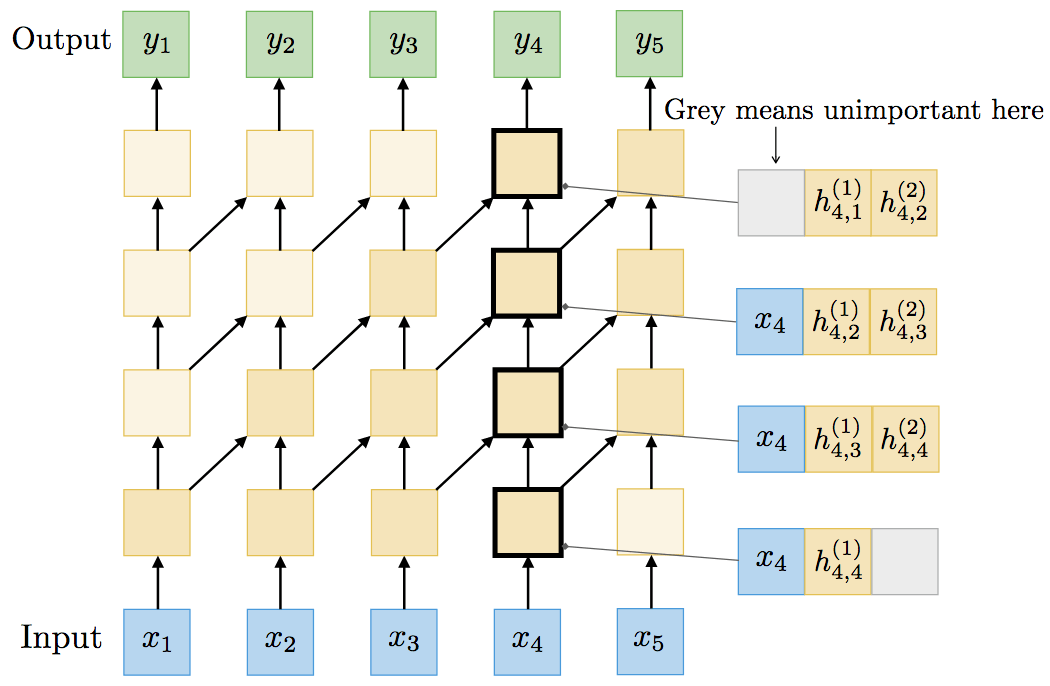
而层间线性变换构成了混合分组卷积(mixed group convolution)——一种非常规的分组卷积,t时刻的分组k通过t+1时刻的分组k-1进行卷积。应用非线性g之后,便精确重现了原本的双层RNN的输出。
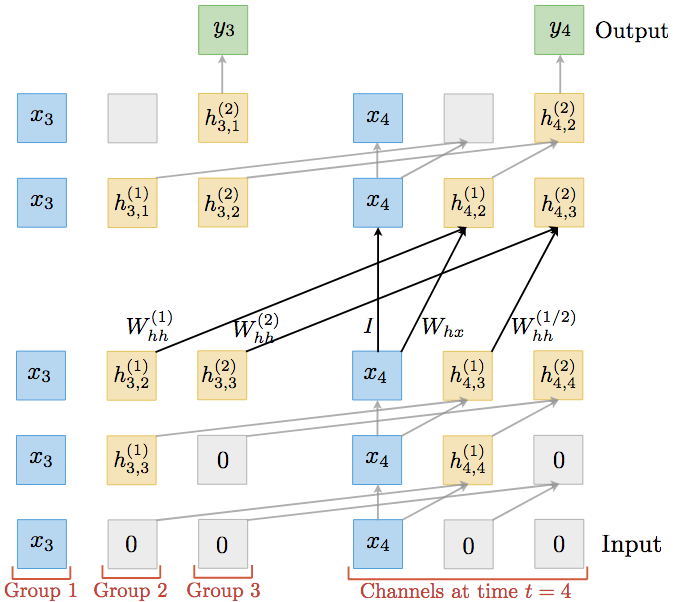
由于之前的等价性推导不涉及RNN的非线性变换g的内在结构,因此,同样适用于LSTM和GRU等RNN变体。例如,对LSTM而言:
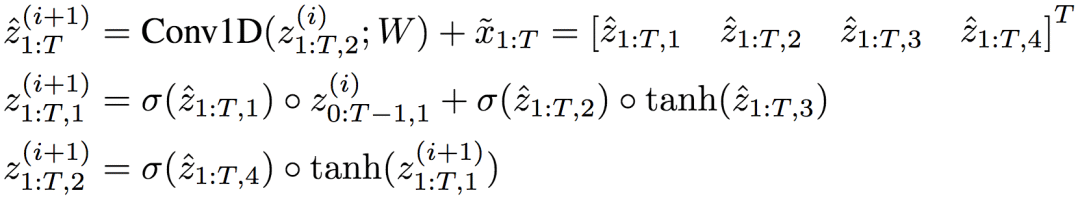
和之前的例子同理,一个双层LSTM可以表达为使用混合分组卷积的TrellisNet:
另一方面,LSTM细胞可以作为TrellisNet的非线性激活。下一节的各项试验中,论文作者就使用了LSTM细胞作为TrellisNet的激活。
同样,TrellisNet也可以使用一些源自RNN的技术:
History repackaging:理论上,RNN可以表示无限长度的历史。但在许多应用中,序列长度太长,会导致反向传播难以为继(梯度消失)。经典的解决方案是将序列分为较小的子序列,在每个子序列上进行截断BPTT。在序列边界处,重新打包隐藏状态ht并传给下一个RNN序列。因此梯度流停在序列边界处。TrellisNet也可以利用这一技术。如下图所示,在RNN中传递压缩历史向量ht等价于在TrellisNet的混合分组卷积中指定非零补齐,也就是在TrellisNet中使用先前序列上最后一层的最后一步作为补齐(“历史”补齐)。
门控激活如前所述,TrellisNet可以使用LSTM的门控函数作为激活。实际上,GRU等其他门控激活同样可以应用于TrellisNet。
变分dropoutRNN的变分dropout(VD)是一种在每层的所有时步应用相同掩码的正则化方案(参见下图,每种颜色代表一种dropout掩码)。如果直接翻译这一技术到TrellisNet的话,需要为网络的每条对角线和混合分组卷积的每个分组创建不同掩码。论文作者转而采用了一种极其简单的替代方案,在每次迭代中,时间维度和深度维度上的每一时步都应用相同的掩码。论文作者的试验表明,这一方案效果优于其他dropout方案。
循环权重dropout/DropConnectDropConnect推广了dropout,dropout归零随机选择的激活子集,而DropConnect归零随机选择的权重子集(如下图所示)。
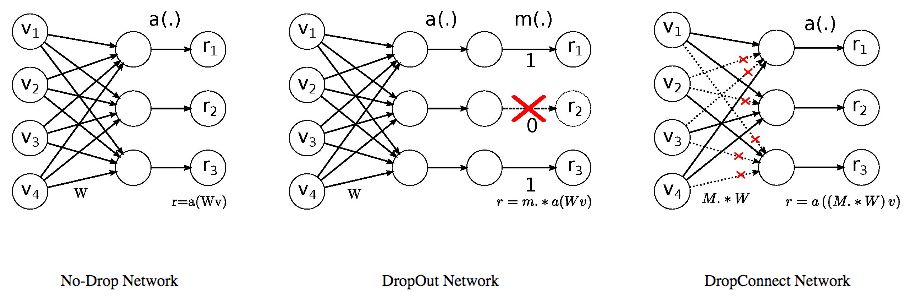
Merity等表明,在隐藏层之间的权重Whh上应用DropConnect,可以优化LSTM语言模型的表现(arXiv:1708.02182)。受此启发,TrellisNet的卷积核应用了DropConnect。
另外,如前所述,等价于RNN的TrellisNet的权重矩阵使用了特别的稀疏结构。那么,有理由相信,去除了这一权重矩阵限制的TrellisNet应该具有更强的表达能力,可以建模比原本的RNN更广的变换。
试验结果
论文作者在单词层面和字符层面的语言建模问题上的测试表明,TrellisNet表现优于当前最先进模型。
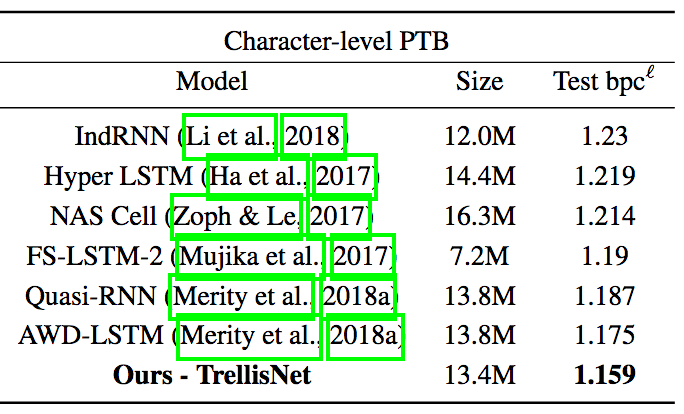
单词层面的语言建模测试是在Penn Treebank(PTB)数据集和WikiText-103(WT103)数据集上进行的。PTB是相对较小的数据集,因此比较容易出现过拟合现象,需要应用前两节提到的一些正则化技术。
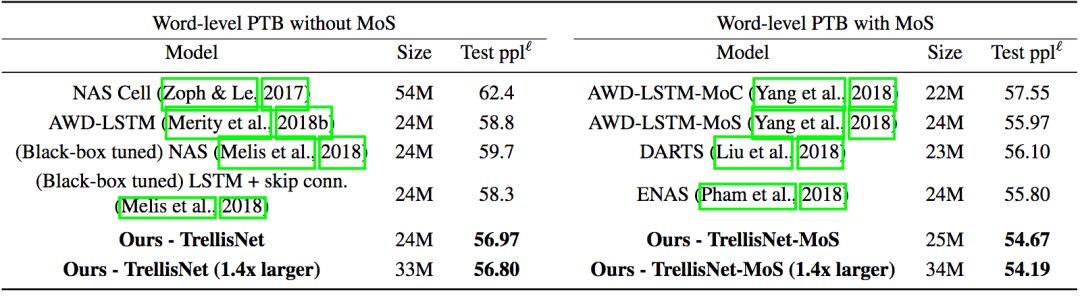
在PTB上的测试结果(MoS指混合softmax)
而WT103规模比PTB大一百倍,过拟合风险较低,但268K的词汇量使得训练很有挑战性。参照之前研究的成果,论文作者在TrellisNet上应用了自适应softmax,提高了内存效率。
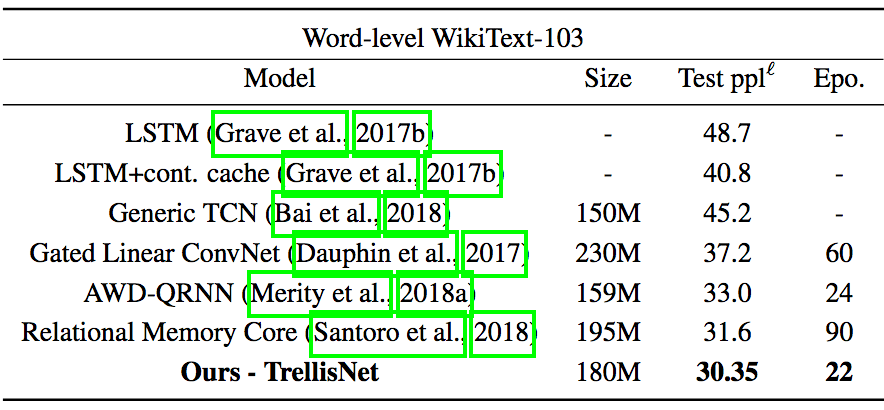
在WT103上的测试结果
在WT103上,TrellisNet不仅表现优于当前最先进的基于自注意力机制的RMC模型(提升约4%),而且收敛速度比RMC要快很多:TrellisNet在22个epoch内收敛,而RMC需要90个epoch。
对于字符层面的语言建模而言,PTB算是中等规模的数据集。因此,论文作者使用了更深的TrellisNet,同时采用了权重归一化和深度监督技术。
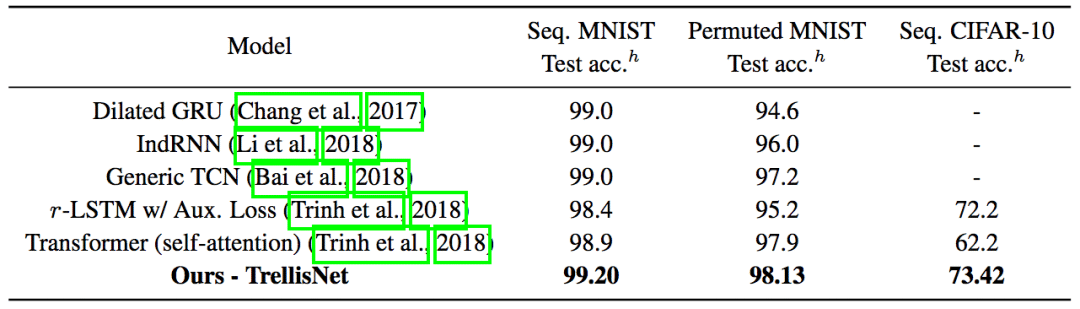
论文作者也评估了TrellisNet建模长期依赖的能力。序列化MNIST、PMNIST、序列化CIFAR-10任务,将图像视作长序列,每次处理一个像素。论文作者为此实现的TrellisNet模型有八百万参数,和之前的研究所用的模型规模相当。为了覆盖更多上下文,论文作者在TrellisNet的中间层应用了空洞卷积。同样,TrellisNet在这些任务上的表现超过了之前的成果。
如前所述,不同任务的TrellisNet采用了不同的超参数和设定,详见下表:
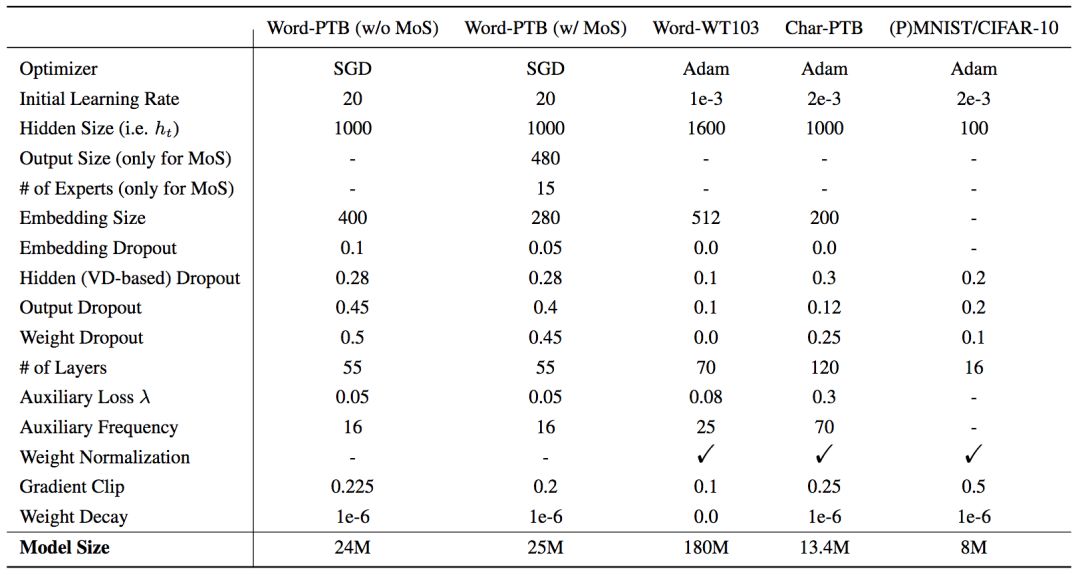
“-”表示未使用
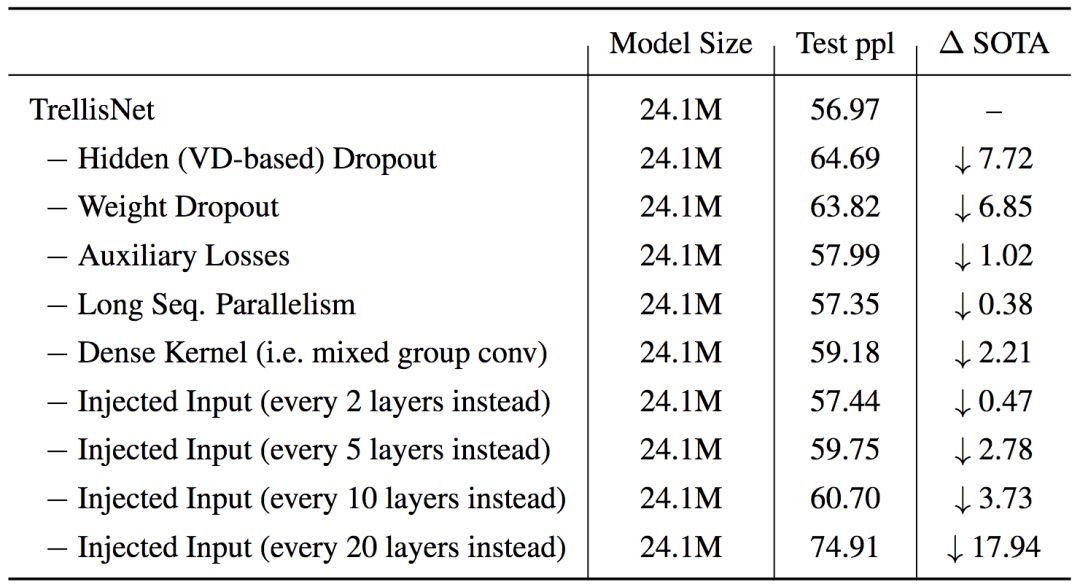
为了验证吸收自CNN和RNN的各种技术的效果,论文作者在单词层面的PTB数据集上进行了消融测试:
结语
TrellisNet在CNN和RNN间架起了一座桥梁。在理论层面,这可能有助于我们得到对序列建模更深入、更统一的理解。在实践层面,通过吸收源自CNN和RNN的技术,TrellisNet的表现超越了当前最先进模型。而且,TrellisNet的表现仍有优化空间。例如,相比经典的LSTM细胞,其他门控激活可能带来更好的效果。同理,其他超参数调整也可能进一步提升TrellisNet的表现。
另外,如果能够建立TrellisNet和基于自注意力机制的架构(如Transformers)的连接,就可以统一时序建模的三大主要范式。
-
神经网络
+关注
关注
42文章
4785浏览量
101279 -
cnn
+关注
关注
3文章
353浏览量
22367
原文标题:CNN和RNN混血儿:序列建模新架构TrellisNet
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论