 深度学习和神经网络的学习是什么样的?
深度学习和神经网络的学习是什么样的?

怎样理解非线性变换和多层网络后的线性可分,神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换。
线性可分:
一维情景:以分类为例,当要分类正数、负数、零,三类的时候,一维空间的直线可以找到两个超平面(比当前空间低一维的子空间。当前空间是直线的话,超平面就是点)分割这三类。但面对像分类奇数和偶数无法找到可以区分它们的点的时候,我们借助 x % 2(除2取余)的转变,把x变换到另一个空间下来比较0和非0,从而分割奇偶数。
二维情景:平面的四个象限也是线性可分。但下图的红蓝两条线就无法找到一超平面去分割。
神经网络的解决方法依旧是转换到另外一个空间下,用的是所说的5种空间变换操作。比如下图就是经过放大、平移、旋转、扭曲原二维空间后,在三维空间下就可以成功找到一个超平面分割红蓝两线 (同SVM的思路一样)。
上面是一层神经网络可以做到的空间变化。若把y⃗y→ 当做新的输入再次用这5种操作进行第二遍空间变换的话,网络也就变为了二层。最终输出是y⃗y→=a2(W2⋅(a1(W1⋅x→+b1))+b2)。设想当网络拥有很多层时,对原始输入空间的“扭曲力”会大幅增加,如下图,最终我们可以轻松找到一个超平面分割空间。
当然也有如下图失败的时候,关键在于“如何扭曲空间”。所谓监督学习就是给予神经网络网络大量的训练例子,让网络从训练例子中学会如何变换空间。每一层的权重WW就控制着如何变换空间,我们最终需要的也就是训练好的神经网络的所有层的权重矩阵。。这里有非常棒的可视化空间变换demo,一定要打开尝试并感受这种扭曲过程。
线性可分视角:神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。
增加节点数:增加维度,即增加线性转换能力。
增加层数:增加激活函数的次数,即增加非线性转换次数。
数学表达式
上面数学思维角度学习了神经网络的原理。下面推到数学表达式
神经网络如下图:
因为每一个节点都是一个神经元。有 Y=a*(W*X+b) a 是激活函数。w是权值,b是偏移量。
对于a4有如下
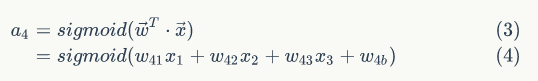
y1有如下的表达式
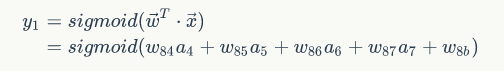
所以有如下表达式:
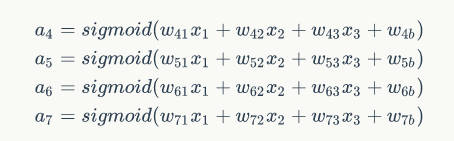
然后:令

代入上面的的方程得到
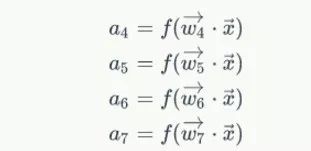
再带入带入
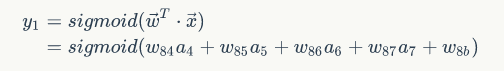
得到y1 = f(w8*a8)其中w8= [w84 w85 w86 w87 w8b]a = [a4,a5,a6,a7,1]所以对于多次网络
可以写成
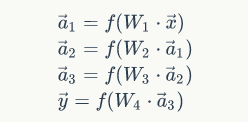
训练参数
因为所有的参数都不能通过求解获得,而是根据不同的输入和输出的比较训练出来的,所以都是监督学习。
结论: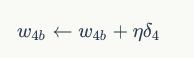 (这里在下节会介绍推理过程,为什么要这样调整权值呢?因为原式为:Wji(新)<-Wji(旧)-(步长*(误差函数对权值的偏导数)))
(这里在下节会介绍推理过程,为什么要这样调整权值呢?因为原式为:Wji(新)<-Wji(旧)-(步长*(误差函数对权值的偏导数)))
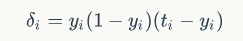
过程如图:注意里面的变量符号:&
从输出层到&有如下表达式:推倒过程下一个节分析
其中,&是节i的误差项,是节点的输出值,是样本对应于节点的目标值。举个例子,根据上图,对于输出层节点8来说,它的输出值是,而样本的目标值是,带入上面的公式得到节点8的误差项应该是:
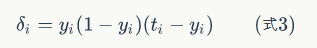
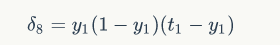
同时对于隐含层有
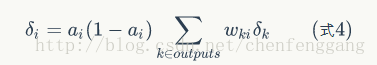
所以有
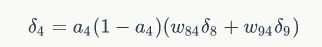 将③和④合并,然后求出w有
将③和④合并,然后求出w有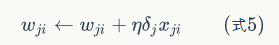 所以有:
所以有:
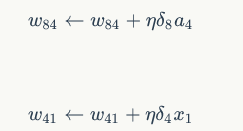
有
这个过程叫做BP过程。
-
神经网络
+关注
关注
42文章
4844浏览量
108229 -
深度学习
+关注
关注
73文章
5612浏览量
124669
原文标题:深度学习——BP神经网络
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
详解深度学习、神经网络与卷积神经网络的应用

带你了解深入深度学习的核心:神经网络

《神经网络和深度学习》中文版电子教材免费下载
快速了解神经网络与深度学习的教程资料免费下载
深度学习与图神经网络学习分享:Transformer



评论