 探讨当下最新AI芯片格局
探讨当下最新AI芯片格局
AI 芯片设计是人工智能产业链的重要一环。 自 2017 年 5 月以来,各 AI 芯片厂商的新品竞相发布,经过一年多的发展,各环节分工逐渐明显。 AI 芯片的应用场景不再局限于云端,部署于智能手机、 安防摄像头、及自动驾驶汽车等终端的各项产品日趋丰富。 除了追求性能提升外, AI 芯片也逐渐专注于特殊场景的优化。
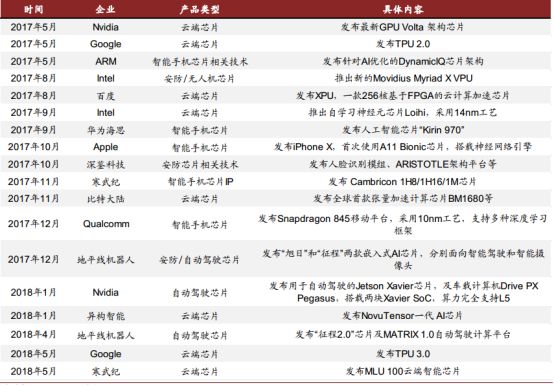
自 2017 年 5 月以来发布的 AI 芯片一览
目前, 人工智能产业链中,包括提供 AI 加速核的 IP 授权商,各种 AI 芯片设计公司,以及晶圆代工企业。
► 按部署的位置来分, AI 芯片可以部署在数据中心(云端),和手机,安防摄像头,汽车等终端上。
► 按承担的任务来分,可以被分为用于构建神经网络模型的训练芯片,与利用神经网络模型进行推断的推断芯片。 训练芯片注重绝对的计算能力,而推断芯片更注重综合指标, 单位能耗算力、时延、成本等都要考虑。
► 训练芯片受算力约束,一般只在云端部署。推断芯片按照不同应用场景,分为手机边缘推断芯片、安防边缘推断芯片、自动驾驶边缘推断芯片。为方便起见,我们也称它们为手机 AI 芯片、安防 AI 芯片和汽车 AI 芯片。
► 由于 AI芯片对单位能耗算力要求较高,一般采用 14nm/12nm/10nm等先进工艺生产。台积电目前和 Nvidia、 Xilinx 等多家芯片厂商展开合作,攻坚 7nm AI 芯片。
AI 芯片投资地图
AI 芯片市场规模: 未来五年有接近 10 倍的增长, 2022 年将达到 352 亿美元。根据我们对相关上市 AI 芯片公司的收入统计,及对 AI 在各场景中渗透率的估算, 2017年 AI 芯片市场规模已达到 39.1 亿美元,具体情况如下:
► 2017 年全球数据中心 AI 芯片规模合计 23.6 亿美元,其中云端训练芯片市场规模 20.2亿美元,云端推断芯片 3.4 亿美元。
► 2017 年全球手机 AI 芯片市场规模 3.7 亿美元。
► 2017 年全球安防摄像头 AI 芯片市场规模 3.3 亿美元。
► 2017 年全球自动驾驶 AI 芯片的市场规模在 8.5 亿美元。
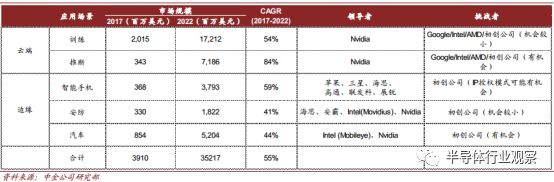
AI 芯片市场规模及竞争格局
Nvidia 在 2017 年时指出,到 2020 年,全球云端训练芯片的市场规模将达到 110 亿美元,而推断芯片(云端+边缘) 的市场规模将达到 150 亿美元。 Intel 在刚刚结束的 2018 DCI峰会上,也重申了数据业务驱动硬件市场增长的观点。 Intel 将 2022 年与用于数据中心执行 AI 加速的 FPGA 的 TAM 预测,由 70 亿美元调高至 80 亿美元。
而同时我们也注意到:
1)手机 SoC 价格不断上升、 AI 向中端机型渗透都将为行业创造更广阔的市场空间。
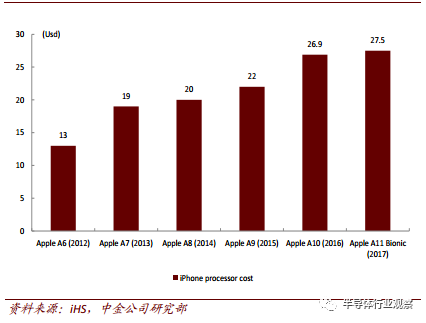
历代 Apple 手机芯片成本趋势
2)安防芯片受益于现有设备的智能化升级,芯片需求扩大。
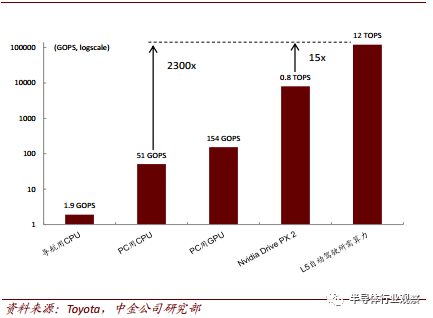
自动驾驶算力需求加速芯片升级
3)自动驾驶方面,针对丰田公司提出的算力需求,我们看到当下芯片算力与 L5 级自动驾驶还有较大差距。 英飞凌公司给出了各自动驾驶等级中的半导体价值预测, 可以为我们的 TAM 估算提供参考。
英飞凌对各自动驾驶等级中半导体价值的预测
结合以上观点,及我们对 AI 在各应用场景下渗透率的分析,我们预测:
► 云端训练芯片市场规模在 2022 年将达到 172 亿美元, CAGR~54%。
► 云端推断芯片市场规模在 2022 年将达到 72 亿美元, CAGR~84%。
► 用于智能手机的边缘推断芯片市场规模 2022 年将达到 38 亿美元, CAGR~59%。
► 用于安防摄像头的边缘推断芯片市场规模 2022 年将达到 18 亿美元, CAGR~41%。
► 用于自动驾驶汽车的边缘推断芯片市场规模 2022 年将达到 52 亿美元, CAGR~44%。
云端训练芯片: TPU 很难撼动 Nvidia GPU 的垄断地位
训练是指通过大量的数据样本,代入神经网络模型运算并反复迭代,来获得各神经元“正确”权重参数的过程。 CPU 由于计算单元少,并行计算能力较弱,不适合直接执行训练任务,因此训练一般采用“CPU+加速芯片”的异构计算模式。目前 Nvidia 的 GPU+CUDA计算平台是最成熟的 AI 训练方案,除此还有:
AI 芯片工作流程
► 第三方异构计算平台 OpenCL + AMD GPU 或 OpenCL+Intel/Xilinx 的 FPGA。
► 云计算服务商自研加速芯片(如 Google 的 TPU) 这两种方案。各芯片厂商基于不同方案,都推出了针对于云端训练的 AI 芯片。
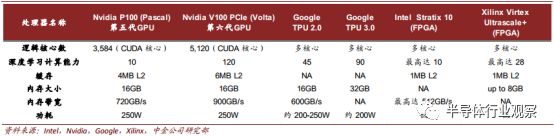
云端训练芯片对比
在 GPU 之外,云端训练的新入竞争者是 TPU。 Google 在去年正式发布了其 TPU 芯片,并在二代产品中开始提供对训练的支持,但比较下来, GPU 仍然拥有最强大的带宽(900GB/s,保证数据吞吐量)和极高的深度学习计算能力(120 TFLOPS vs. TPUv2 45 TFLOPS),在功耗上也并没有太大劣势(TPU 进行训练时,引入浮点数计算,需要逾 200W 的功耗,远不及推断操作节能)。目前 TPU 只提供按时长付费使用的方式,并不对外直接销售,市占率暂时也难以和 Nvidia GPU 匹敌。
► Intel
虽然深度学习任务主要由 GPU 承担,但 CPU 目前仍是云计算芯片的主体。 Intel 于 2015年底年收购全球第二大 FPGA 厂商 Altera 以后,也积极布局 CPU+FPGA 异构计算助力 AI,并持续优化 Xeon CPU 结构。 2017 年 Intel 发布了用于 Xeon 服务器的,新一代标准化的加速卡,使用户可以 AI 领域进行定制计算加速。得益于庞大的云计算市场支撑, Intel 数据中心组业务收入规模一直位于全球首位, 2016-17 年单季保持同比中高个位数增长。 2017年 4 季度起,收入同比增速开始爬坡至 20%左右,但相比 Nvidia 的强劲增长态势仍有差距。
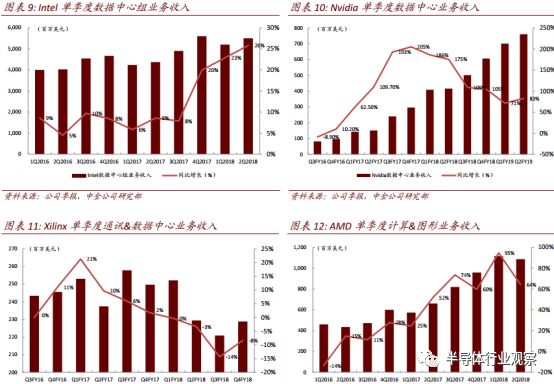
► AMD
AMD 虽未单独拆分数据中心收入,但从其计算和图像业务的收入增长情况来看, GPU 销量向好。目前 AMD GPU 也开始切入深度学习训练任务,但市场规模落后于 Nvidia。
云端推断芯片:百家争鸣,各有千秋
推断是指借助现有神经网络模型进行运算, 利用新的输入数据来一次性获得正确结论的过程。 推断过程对响应速度一般有较高要求, 因此会采用 AI 芯片(搭载训练完成的神经网络模型)进行加速。
相比训练芯片,推断芯片考虑的因素更加综合:单位功耗算力,时延,成本等等。初期推断也采用 GPU 进行加速,但由于应用场景的特殊性,依据具体神经网络算法优化会带来更高的效率, FPGA/ASIC 的表现可能更突出。除了 Nvidia、 Google、 Xilinx、 Altera(Intel)等传统芯片大厂涉足云端推断芯片以外, Wave computing、 Groq 等初创公司也加入竞争。中国公司里,寒武纪、比特大陆同样积极布局云端芯片业务。
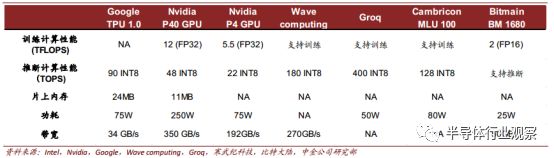
主要云端推断芯片对比
我们认为, 云端推断芯片在未来会呈现百花齐放的态势。 具体情况如下:
► Nvidia
在云端推断芯片领域, Nvidia 主打产品为 P40 和 P4, 二者均采用 TSMC 16nm 制程。 TeslaP4 拥有 2560 个流处理器,每秒可进行 22 万亿次(TOPS) 计算(对应 INT 8)。而性能更强的 Tesla P40 拥有 3840 个流处理器,每秒可进行 47 万亿次(TOPS)计算(对应 INT 8)。从单位功耗推断能力来看, P4/P40 虽然有进步,但仍逊于 TPU。 GPU 在推断上的优势是带宽。
Google TPU 1.0 为云端推断而生,其运算单元对神经网络中的乘加运算进行了优化,并采用整数运算。 TPU 1.0 单位功耗算力在量产云端推端芯片中最强,达 1.2TOPS/Watt,优于主流 Nvidia GPU。 TPU 2.0 在推断表现上相比于 1 代并没有本质提升,主要进步是引入对浮点数运算的支持,及更高的片上内存。正如前文所述,支持训练的 TPU 功耗也会变得更高。
► Wave Computing
Wave computing 于 2010 年 12 月成立于加州,目前累计融资 1.2 亿美元,是专注于云端深度学习训练和推理的初创公司。Wave computing 的一代 DPU 深度学习算力达 180 TOPS,且无需 CPU 来管理工作流。目前公司正与 Broadcomm 合作在开发二代芯片,将采用 7nm制程。
► Groq
Groq 是由 Google TPU 初始团队离职创建的 AI 芯片公司,计划在 2018 年发布第一代 AI芯片产品,对标英伟达的 GPU。其算力可达 400 TOPs(INT 8),单位能耗效率表现抢眼。
► 寒武纪科技
寒武纪在 2017 年 11 月发布云端芯片 MLU 100,同时支持训练和推断,但更侧重于推断。MLU 100 在 80W 的功耗下就可以达到 128 TOPS(对应 INT 8)的运算能力。
► 比特大陆
比特大陆的计算芯片 BM 1680,集成了深度学习算法硬件加速模块(NPUs),应用于云端计算与推理。 BM1680 还提供了 4 个独立的 DDR4 通道,用于高速数据缓存读取,以提高系统的执行速度。其典型功耗只有 25W,在单位能耗推断效率上有一定优势。
应用场景#1:云端推断芯片助力智能语音识别
云端推断芯片提升语音识别速度。 语音识别是推断芯片的工作场景之一,如 Amazon 的语音助手 Alexa,其“智能”来自于 AWS 云中的推断芯片。 Alexa 是预装在亚马逊 Echo内的个人虚拟助手,可以接收及相应语音命令。通过将语音数据上传到云端,输入推断芯片进行计算,再返回结果至本地来达到与人实现交互的目的。原先云端采用 CPU 进行推断工作,由于算力低,识别中会有 300-400ms 的延迟,影响用户体验。
智能音箱通过云端推断芯片工作
而现今 AWS 云中采用了 Nvidia 的 P40 推断芯片,结合 Tensor RT 高性能神经网络推理引擎(一个 C++库),可以将延迟缩减到 7ms。 此外, AI 芯片支持深度学习,降低了语音识别错误率。 目前, 借助云端芯片的良好推断能力,百度语音助手的语音识别准确度已达到 97%之高。
Nvidia 云端推断芯片提升语音识别速度
应用场景#2:推断芯片应用于智能搜索
RankBrain 是 Google 众多搜索算法的一部分,它是一套计算机程序,能把知识库中上十亿个页面进行排序,然后找到与特定查询最相关的结果。 目前, Google 每天要处理 30 亿条搜索,而其中 15%的词语是 Google 没有见过的。 RankBrain 可以观察到看似无关复杂搜索之间的模式,并理解它们实际上是如何彼此关联的, 实现了对输入的语义理解。 这种能力离不开 Google 云端推断芯片 TPU 的辅助。
推断芯片助力深度学习实现语义识别
先前,在没有深度学习情况下,单纯依靠 PageRanking 及 InvertedIndex, Google 也能实现一定程度的对搜索词条排序的优化,但准确率不够。 TPU 利用 RankBrain 中的深度学习模型,在 80%的情况下计算出的置顶词条,均是人们最想要的结果。

TPU+RankBrain 在推断正确率上获得提高
用于智能手机的边缘推断芯片:竞争格局稳定,传统厂商持续受益
手机芯片市场目前包括:(1)苹果,三星,华为这类采用芯片+整机垂直商业模式的厂商,以及(2)高通,联发科,展锐等独立芯片供应商和(3) ARM, Synopsys、 Cadence 等向芯片企业提供独立 IP 授权的供应商。 采用垂直商业模式厂商的芯片不对外发售,只服务于自身品牌的整机,性能针对自身软件做出了特殊优化,靠效率取胜。独立芯片供应商以相对更强的性能指标,来获得剩余厂商的市场份额。
从 2017 年开始,苹果,华为海思,高通,联发科等主要芯片厂商相继发布支持 AI 加速功能的新一代芯片(如下图), AI 芯片逐渐向中端产品渗透。由于手机空间有限, 独立的AI 芯片很难被手机厂采用。在 AI 加速芯片设计能力上有先发优势的企业(如寒武纪)一般通过 IP 授权的方式切入。
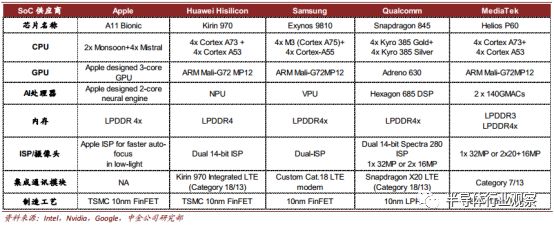
手机 AI 芯片对比
对这些厂商来说,我们认为 AI 化的主要作用是提升芯片附加价值与产品单价。根据 IHS的数据,随着硬件性能的增强及针对于 AI 的运算结构不断渗透,苹果 A11 芯片的成本已达到 27.5 美元。
智能手机 SoC 市占率分析(2017)
芯片成本持续上涨有望带动垂直模式厂商整机售价走高,在出货量相同的情况下为现有芯片厂商贡献更多的营业收入。高通、联发科、展锐等独立芯片供应商则会受益于芯片本身 ASP 的提升。
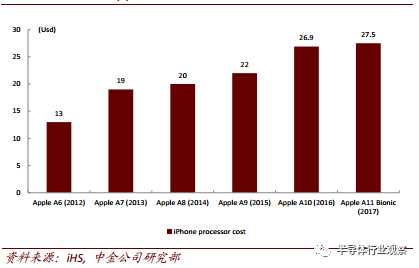
历代 Apple 手机芯片成本趋势
应用场景#1:推断芯片为 AI 拍照技术提供硬件支持
智能手机通过 AI 算法+终端推断芯片,可实现对于现实世界图像的智能识别,并在此基础上进行实时优化:
1)从整个场景识别,到特殊优化过程中,推断芯片为算法运行提供硬件支持。
2)手机推断芯片中 GPU、 NPU 等单元的协同工作,实现了对边缘虚化更准确的处理,使小尺寸感光元件的手机获得“单反” 级的景深效果,增加相片的层次感。
3)人脸结构的识别也离不开边缘推断芯片,芯片性能的提升直接导致了 AI 美颜、 3D 光效等特殊效果变得更加自然。 如果缺少终端芯片的支持,一旦运行高负载的 AI 任务手机就需要呼唤云端。而云端的相应速度不够,导致 AI 摄影的识别率和准确率下降,用户体验将大打折扣。
手机 AI 芯片辅助图片渲染优化
应用场景#2:推断芯片助力语音助手处理复杂命令
从“听清”到“听懂”,自然语言理解能力提升与推断芯片硬件的支持分不开:多麦克风方案的普及解决了“听清”的问题,而到“听懂”的跨越中自然语言理解能力是关键。这不仅对云端训练好的模型质量有很高要求,也必须用到推断芯片大量的计算。随着对话式 AI 算法的发展,手机 AI 芯片性能的提升,语音助手在识别语音模式、分辨模糊语音、剔除环境噪声干扰等方面能力得到了优化,可以接受理解更加复杂的语音命令。
手机 AI 芯片辅助 Vivo Jovi 处理复杂命令
用于安防边缘推断芯片: 海思、安霸与 Nvidia、 Mobileye 形成有力竞争
视频监控行业在过去十几年主要经历了“高清化”、“网络化”的两次换代,而随着 2016年以来 AI 在视频分析领域的突破,目前视频监控行业正处于第三次重要升级周期——“智能化”的开始阶段。 前端摄像头装备终端推断芯片,可以实时对视频数据进行结构化处理,“云+边缘”的边缘计算解决方案逐渐渗透。 我们预计, 应用安防摄像头的推断芯片市场规模,将从 2017 年的 3.3 亿美元,增长至 2022 年的 18 亿美元, CAGR~41%。
应用场景:安防边缘推断芯片实现结构化数据提取,减轻云端压力
即便采用 H.265 编码,目前每日从摄像机传输到云端的数据也在 20G 左右,不仅给存储造成了很大的压力,也增加了数据的传输时间。 边缘推断芯片在安防端的主要应用,基于将视频流在本地转化为结构化数据。 这样既节省云端存储空间, 也提升系统工作效率。“视频结构化”,简言之即从视频中结构化提取关键目标,包括车辆、人及其特征等。虽然这种对数据的有效压缩要通过算法实现,但硬件的支持不可或缺。
视频结构化数据提取实例
根据海康威视提供传统视频解码芯片厂商积极布局 AI 升级。 华为海思、安霸(Ambarella)都在近一年内推出了支持 AI 的安防边缘推断芯片。海思的 HI3559A 配备了双核神经网络加速引擎,并成为第一款支持 8k 视频的芯片;安霸也通过集成 Cvflows 张量处理器到最新的 CV2S 芯片中,以实现对 CNN/DNN 算法的支持。
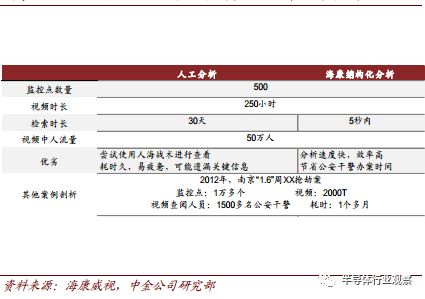
AI 芯片助力结构化分析实现工作效率提升
打入视频监控解决方案龙头海康威视,实现前装的 Nvidia,Movidius 同样不甘示弱, Movidius 发布的最新产品 Myriad X 搭载神经计算引擎,在 2W的功耗下可实现 1TOPS 的算力。Nvidia TX2 是 TX1 的升级产品,算力更强,达到 1.5TFLOPS,存储能力也有提升。
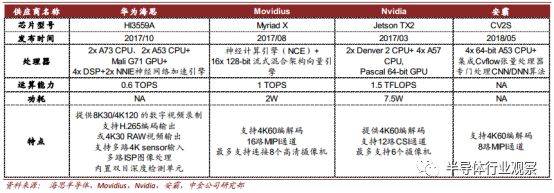
安防 AI 芯片对比
我们认为,目前整个安防 AI 芯片市场竞争格局稳定,现有厂商凭借与下游客户长期的合作,有望继续受益于安防智能化的升级,属于新进入者的市场空间有限。 安防 AI 芯片下游客户稳定,为海康威视、大华股份等视频监控解决方案提供商。客户与传统视频解码芯片厂商的长期合作具有粘性,同样推出新产品,初创公司的竞争优势弱一些,尤其是在安防 AI 芯片性能差异化很难做到很大的情况下。
用于自动驾驶的边缘推断芯片:一片蓝海,新竞争者有望突围
除了智能手机, 安防外, 自动驾驶汽车也是人工智能的落地场景之一。 车用半导体强大需求已经使供给端产能开始吃紧,而用于自动驾驶的推断芯片需求,同样有望在未来 5年内实现高速增长。我们预计,其市场规模将从 2017 年的 8.5 亿美元,增长至 2022 年的 52 亿美元,CAGR~44%。若想使车辆实现真正的自动驾驶,要经历在感知-建模-决策三个阶段,每个阶段都离不开终端推断芯片的计算。
应用场景#1:自动驾驶芯片助力环境感知
在车辆感知周围环境的过程中,融合各路传感器的数据并进行分析是一项艰巨的工作,推断芯片在其中起到了关键性作用。 我们首先要对各路获得的“图像”数据进行分类,在此基础之上,以包围盒的(bounding box) 形式辨别出图像中的目标具体在什么位置。
但这并不能满足需求:车辆必须要辨别目标到底是其他车辆,是标志物,是信号灯,还是人等等,因为不同目标的行为方式各异,其位置、状态变化,会影响到车辆最终的决策,因而我们要对图像进行语义分割(segmantation,自动驾驶的核心算法技术)。语义分割的快慢和推断芯片计算能力直接相关,时延大的芯片很显然存在安全隐患,不符合自动驾驶的要求。
自动驾驶推断芯片+算法实现视频的像素级语义分割
应用场景#2:自动驾驶芯片助力避障规划
避障规划是车辆主要探测障碍物, 并对障碍物的移动轨迹跟踪(Moving object detection and tracking,即 MODAT)做出下一步可能位臵的推算,最终绘制出一幅含有现存、及潜在风险障碍物地图的行为。出于安全的要求,这个风险提示的时延应该被控制在 50ms级。
随着车速越来越快,无人车可行驶的路况越来越复杂,该数值在未来需要进一步缩短,对算法效率及推断芯片的算力都是极大的挑战。 例如,在复杂的城区路况下,所需算力可能超过 30TOPS。未来 V2X 地图的加入,将基本上确保了无人车的主动安全性,但同样对推断芯片的性能提出了更高的要求。
自动驾驶推断芯片+算法实现自动驾驶避障规划
从以上应用场景不难看出, 自动驾驶对芯片算力提出了很高的要求, 而受限于时延及可靠性,有关自动驾驶的计算不能在云端进行,因此边缘推断芯片升级势在必行。根据丰田公司的统计数据,实现 L5 级完全自动驾驶,至少需要 12TOPS 的推断算力,按现行先进的 Nvidia PX2 自动驾驶平台测算,差不多需要 15 块 PX2 车载计算机,才能满足完全自动驾驶的需求。
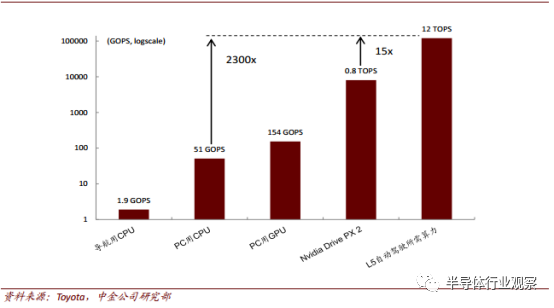
自动驾驶算力需求加速芯片升级
传统车载半导体厂商积极布局自动驾驶。 近些年来,各传统车载半导体供应商纷纷涉猎自动驾驶业务,推出了各自的自动驾驶,或辅助驾驶平台,如 TI 推出了面向于 L1/2 级的平价产品,而 Renesas 和 NXP 步入中高端市场。 V3M 与 Bluebox 分别是两家的代表性产品,均满足客户 L3 级自动驾驶需求。目前 NXP 的 Bluebox 2.0 也在测试中。
老牌厂商中Mobileye(被 Intel 收购) 在自动驾驶边缘推断芯片上表现最为抢眼,其 EyeQ3 芯片已经被集成于新一代量产 Audi A8 中的 zFAS 平台上,而 A8 也因此成为第一款支持 L3 级自动驾驶的车型。
下一代产品中, Mobileye 和新秀 Nvidia 有望实现领先。 Mobileye 更注重算法端, 强调软硬件结合带来的效率提升,其开发的最新 EyeQ5 芯片在 10W 的功耗下就能达到 24TOPS的算力。 英伟达作为传统硬件厂商,借助于 GPU 图形处理的优势,也在自动驾驶市场取得了相应的领先地位,其芯片更注重绝对算力表现。将于今年三季度流片, 2019 年三季度量产的“算力怪兽” Pegasus 平台,搭载了两块 Nvidia 下一代的 GPU,将实现 320TOPS的超强计算能力,完全覆盖 L5 级别应用的需求。
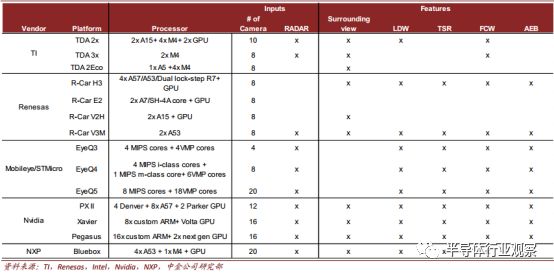
自动驾驶平台对比
对比其他终端应用场景,自动驾驶不仅计算复杂程度最高,车规级要求也为芯片设立了更高的准入门槛, 其硬件升级落地相对缓慢。 目前各厂商下一代的自动驾驶平台最早计划于 2019 年量产,现今上市平台中,芯片大多只支持 L2/3 级。之前 Uber 的无人车事故,也对整个行业的发展造成了拖累。
下一代自动驾驶 AI 芯片流片及投产时间预估
自动驾驶芯片市场仍处于初期起步阶段。 虽然 NXP 等传统半导体厂商深耕于汽车电子多年,获得了一定的客户粘性,但在自动驾驶业务上,整个市场还未形成非常明显的竞争格局。客户也在不断测试芯片厂商的产品,来实现最优选择。根据各公司披露的数据,目前各大芯片厂商与整车厂(OEM)及 Tier 1 厂商都开展了紧密的合作,但客户数量不相上下。
从客户的偏好来看,传统大厂愿意自行搭建平台, 再采购所需芯片,而新车厂偏向于直接购买自动驾驶平台。 介于实现完全自动驾驶非常复杂,目前还在起步阶段,我们认为初创公司在整个行业的发展中是有机会的,并看好技术领先,能与车厂达成密切合作的初创公司。
各芯片厂商合作方比较
主要中国 AI 芯片公司介绍
中国大陆目前有超 20 家企业投入 AI 芯片的研发中来。 除了像华为海思、紫光展锐这种深耕于芯片设计多年的企业之外,也有不少初创公司表现抢眼,如寒武纪、比特大陆等。此外,***地区的 GUC(创意电子)是一家 IC 后端设计公司,凭借 20 年的行业经验,和投资方晶圆制造巨头台积电的鼎力支持,在 AI 芯片高速发展的大环境下也有望受益。
中国大陆主要 AI 芯片设计公司至少有 20 家
以下企业值得关注:
海思半导体(Hisilicon)
海思半导体成立于 2004 年 10 月,是华为集团的全资子公司。海思的芯片产品覆盖无线网络、固网及数字媒体等多个领域,其 AI 芯片为 Kirin 970 手机 SoC 及安防芯片 Hi3559A V100。 Kirin 970 集成 NPU 神经处理单元,是全球第一款手机 AI 芯片, 它在处理静态神经网络模型方面有得天独厚的优势。而 Hi3559A V100 是一款性能领先的支持 8k 视频的 AI芯片。
清华紫光展锐 (Tsinghua UNISOC)
清华紫光集团于 2013 年、 2014 年先后完成对展讯及锐迪科微电子的收购, 2016 年再将二者合并,成立紫光展锐。紫光展锐是全球第三大手机基带芯片设计公司,是中国领先的 5G 通信芯片企业。 Gartner 的数据显示,紫光展锐手机基带芯片 2017 年出货量的全球占比为 11%。除此之外,展锐还拥有手机 AI 芯片业务,推出了采用 8 核 ARM A55 处理器的人工智能 SoC 芯片 SC9863,支持基于深度神经网络的人脸识别技术, AI 处理能力比上一代提升 6 倍。
GUC(***创意电子, 3443 TT)
公司介绍: GUC 是弹性客制化 IC 领导厂商(The Flexible ASIC LeaderTM),主要从事 IC 后端设计。后端设计工作以布局布线为起点,以生成可以送交晶圆厂进行流片的 GDS2 文件为终点,需要很多的经验,是芯片实现流片的重要一环。初创公司同时完成前后端设计难度较大。在 AI 芯片设计发展的大环境下,加上大股东台积电的支持, GUC 有望获得大的后端订单。 公司已在***证券交易所挂牌上市,股票代号为 3443。
以下为初创公司:
寒武纪科技(Cambricon Technologies)
寒武纪创立于 2016 年 3 月,是中科院孵化的高科技企业,主要投资人为国投创业和阿里巴巴等。公司产品分为终端 AI 芯片及云端 AI 芯片。终端 AI 芯片采用 IP 授权模式,其产品 Cambricon-1A 是全球首个实现商用的深度学习处理器 IP。去年年底公司新发布了第三代机器学习专用 IP Cambricon-1M,采用 7nm 工艺,性能差不多高出 1A 达 10 倍。云端产品上,寒武纪开发了 MLU 100 AI 芯片,支持训练和推断,单位功耗算力表现突出。
比特大陆(Bitmain)
比特大陆成立于 2013 年 10 月, 是全球第一大比特币矿机公司,目前占领了全球比特币矿机 60%以上的市场。由于 AI 行业发展迅速及公司发展需要,公司将业务拓展至 AI 领域,并于与 2017 年推出云端 AI 芯片 BM1680,支持训练和推断。目前公司已推出第二代产品BM1682,相较上一代性能提升 5 倍以上。
地平线机器人(Horizon Robotics)
成立于 2015 年 7 月,地平线是一家注重软硬件结合的 AI 初创公司,由 Intel、嘉实资本、高瓴资本领投。公司主攻安防和自动驾驶两个应用场景,产品为征程 1.0 芯片(支持 L2自动驾驶)和旭日 1.0(用于安防智能摄像头),具有高性能(实时处理 1080P@30 帧,并对每帧中的 200 个目标进行检测、跟踪、识别)、低功耗(典型功耗在 1.5W)、和低延迟的优势(延迟小于 30 毫秒)。公司二代自动驾驶芯片将于 1Q19 流片,实现语义建模。
云天励飞(Intellifusion)
公司创立于 2014 年 8 月,由山水从容传媒、松禾资本领投,主攻安防 AI 芯片。其自研IPU 芯片是低功耗的深度学习专用处理器,内含专用图像处理加速引擎,通过级联扩展最多可处理 64 路视频。能耗比突出,超过 2Tops/Watt。
异构智能(NovuMind)
异构智能创立于 2015 年 8 月,由洪泰基金、宽带资本、真格基金和英诺天使投资。 2018年公司展示了其首款云端 AI 芯片 NovuTensor,基于 FPGA 实现,性能已达到目前最先进的桌面服务器 GPU 的一半以上,而耗电量仅有 1/20。公司即将推出的第二款 ASIC 芯片,能耗不超 5W, 计算性能达 15 TOPs,将被用于安防和自动驾驶应用中。
龙加智(Dinoplus)
创立于 2017 年 7 月龙加智是专注于云端芯片的 AI 初创公司,由挚信资本和翊翎资本领投。其产品 Dino-TPU 在 75W 功耗下,计算能力超过除最新款 Nvidia Volta 之外的所有 GPU,时延仅为 Volta V100 的 1/10。同时, Dino-TPU 提供市场上独一无二的冗余备份和数据安全保障。 公司计划于 2018 年底完成第一款芯片的流片。
-
自动
+关注
关注
0文章
118浏览量
26038 -
AI芯片
+关注
关注
17文章
1883浏览量
34997
原文标题:AI芯片最新格局分析
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
苹芯科技亮相2024中国AI芯片开发者论坛
杭州灵伴科技推动AR+AI产业新格局
DEKRA德凯探讨AI安全技术的前沿趋势
NVIDIA和Meta CEO探讨AI与仿真模拟技术的潜力
NVIDIA黄仁勋和Meta马克·扎克伯格探讨开源AI的变革潜力
AI时代的芯片革命:GPU、FPGA与TPU竞相涌现


risc-v多核芯片在AI方面的应用

院士称全球芯片产业格局即将重构








 工商网监
工商网监
评论