 Julia和TPU的结合意味着快速、易于表达的ML计算!
Julia和TPU的结合意味着快速、易于表达的ML计算!
将Julia代码直接部署到谷歌Cloud TPU,让程序运行更快的官方指南来了!Julia和TPU的结合意味着快速、易于表达的ML计算!”
Julia是一门集众家所长的编程语言。随着Julia 1.0在8月初正式发布,Julia语言已然成为机器学习编程的新宠。
这门由 MIT CSAIL 实验室开发的编程语言结合了 C 语言的速度、Ruby 的灵活、Python 的通用性,以及其他各种语言的优势于一身,并且具有开源、简单易掌握的特点。
随着用户越来越多,围绕Julia的开发工具、技术、教程等也愈加丰富。昨天,Julia开发人员Keno Fischer和Elliot Saba发表了一篇新论文AutomaticFullCompilationof JuliaProgramsandMLModelstoCloudTPUs,介绍如何将Julia代码直接部署到Google Cloud TPU,让程序运行更快。
Jeff Dean在推特上推荐了这篇论文,评价称:“Julia和TPU的结合意味着快速、易于表达的ML计算!”
谷歌的Cloud TPU是一种用于机器学习工作负载的很强大的新硬件架构。近年来,Cloud TPU为谷歌的许多里程碑式的机器学习成就提供了动力。
谷歌现在已经在他们的云平台上开放提供一般用途的TPU,并且最近已经进一步开放,允许非TensorFlow前端使用。
这篇论文描述了通过这个新的API和Google XLA编译器,将Julia程序的适当部分卸载(offload)到TPU的方法和实现。
这一方法能够将表示为Julia程序的VGG19模型的前向传递(forward pass)完全融合到单个TPU可执行文件中,以便卸载到设备。该方法也很好地与Julia代码上现有的基于编译器的自动微分技术相结合,因此我们也能够自动获得VGG19的反向传递并类似地将其卸载到TPU。
使用这一编译器定位TPU,能够在0.23秒内对100张图像的VGG19前向传递进行评估,这与CPU上原始模型所需的52.4秒相比大幅加速了。他们的实现仅需不到1000行Julia代码,没有对核心Julia编译器或任何其他Julia包进行TPU特定的更改。
具体方法和实现细节请阅读原论文。以下主要从分别从回顾TPU硬件架构、Julia编译器的workflow、将XLA嵌入到Julia IR的细节,以及结果与讨论几个部分进行介绍。

谷歌TPU和XLA编译器
2017年,谷歌宣布他们将通过云服务向公众提供其专有的张量处理单元(TPU)机器学习加速器。最初,TPU的使用仅限于使用谷歌的TensorFlow机器学习框架编写的应用程序。幸运的是,2018年9月,Google通过较低级别的XLA(Accelerated Linear Algebra)编译器的IR开放了对TPU的访问权限。该IR是通用的,是用于表示线性代数原语的任意计算的优化编译器,因此为非Tensorflow用户以及非机器学习工作负载的TPU目标提供了良好的基础。
XLA(加速线性代数)是谷歌的一个部分开源编译器项目。它具有丰富的输入IR,用于指定多线性代数计算,并为CPU,GPU和TPU提供后端代码生成功能。XLA的输入IR(称为HLO高级优化IR)在基本数据类型或其元组(但没有元组数组)的任意维数组上运行。HLO操作包括基本算术运算、特殊函数、广义线性代数运算、高级数组运算以及用于分布式计算的原语。XLA可以执行输入程序的语义简化,以及执行整个程序的内存调度,以便有效地使用和重用可用内存(这是大型机器学习模型的一个非常重要的考虑因素)。
每个HLO操作都有两种操作数:
静态操作数,它的值必须在编译时可用并配置操作。
动态操作数,由上述张量组成。
这篇论文介绍了使用这个接口将常规的Julia代码编译带TPU的初步工作。这一方法不依赖跟踪,而是利用Julia的静态分析和编译功能来编译完整的程序,包括对设备的任何控制flow。特别是,我们的方法允许用户在编写模型时充分利用Julia语言的完整表现力,能够编译使用Flux机器学习框架编写的完整机器学习模型,将前向和后向模型传递以及训练loop融合到单个可执行文件,并将其卸载到TPU。
Julia编译器的工作原理
为了理解如何将Julia代码编译为XLA代码,了解常规Julia编译器的工作原理是有益的。Julia在语义上是一种非常动态的语言。但是,在标准配置中,Julia的最终后端编译器是LLVM(Lattner&Adve,2004),它是一个静态编译器后端。
Julia编译器需要将语言的动态语义与LLVM表示的静态语义之间联系起来。为了理解这个过程,我们将研究Julia系统的四个方面:动态语义、静态编译器内部函数的嵌入、过程间类型推断,以及静态子图的提取。此外,我们还将研究这些特征与宏和生成的函数的交互,这些函数将与XLA编译器相关。
如何将XLA嵌入到Julia IR
XLA嵌入
要编译为XLA而不是LLVM,我们应用了上一节中概述的策略。实际上,我们可以重用大多数编译器本身(特别是所有类型推断和所有mid-level优化传递)。
让我们先定义动态语义和静态嵌入。
张量表示(Tensor representation)
由于其作为线性代数的教学和研究语言的传统,Julia具有非常丰富的数组抽象层次结构。Julia的标准库数组是可变的,并且在类型和维度上进行参数化。此外,StaticArrays.jl(Ferris&Contributors,2018)包提供了在元素类型和形状上进行参数化的不可变数组。因此,成形的N维不可变张量的概念对Julia代码来说并不陌生,并且大多数现有的通用代码能够毫无问题地处理它。
因此,我们通过定义一个runtime结构来嵌入XLA values。

Listing 1: XRTArray3的定义。
操作表示(Operation representation)
分离静态和动态操作数
HLO操作数(HLO operands)分为静态和动态操作数。假设我们有一个示例XLA操作'Foo'采用一个静态操作数(例如一个整数)和两个动态操作数。这个嵌入如下所示:

在这个示例中,“execute”函数实现在远程设备上运行操作的动态语义。函数(hlo::HloFoo)(...) 语法表示调用运算符重载。因此,这意味着对HloFoo(1) 的调用将构造并返回一个callabale对象,当在两个XRTArrays上调用时,它将使用静态操作数'1'远程执行'Foo'HLO操作,并且对应于两个数组的动态操作数。这种分离并不是绝对必要的,但确实有嵌入到Julia IR的有用特性,易于理解:
在Listing 2的示例中,我们将HLO操作数(包括静态操作数)拼接到AST中。这产生了一个非常简单的XLA映射(遍历每个语句,从拼接指令规范获取静态操作数,从类型推断获得动态形状并生成相应的XLA代码)。
当然,我们通常不会手动拼接这些指令,但是手动拼接的示例说明了为什么分离静态操作数很有用,并说明了成功offload到XLA的条件。
如果经过所有相关的Julia级别优化之后,IR可以完全卸载:
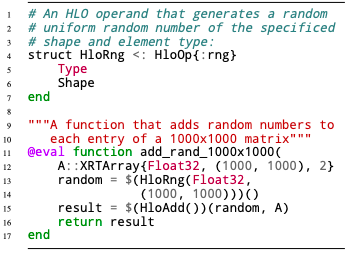
Listing 2: 手动构建的XLA嵌入
满足这些条件的IR可以简单地转换成XLA IR。
结果
本文描述的方法在很大程度上依赖于Julia中间端编译器,以确定足够精确的信息,在程序的足够大的子区域中分摊任何启动开销。
在本节中,我们证明了Julia编译器确实足够精确,使该方法适用于实际的程序。
VGG19 forward pass

图1:在编译到XLA之后,Metalhead.jl VGG19的forward pass 和backwards pass 生成的XLA指令摘要。
这里显示了未优化(在Julia前端之后)和优化的计数(在类似于CPU后端使用的XLA优化pipeline之后,但没有HLO融合)。
VGG19 backward pass
为了获得backwards pass,我们使用基于Zygote.jl编译器的AD框架(Innes, 2018)。Zygote对Julia代码进行操作,其输出也是Julia函数(适合重新引入Zygote以获得更高阶导数,也适合编译到TPU)。
示例如下:

结论
在这篇论文中,我们讨论了如何将Julia代码编译为XLA IR,从而实现卸载到TPU设备。这里描述的实现重新利用了现有Julia编译器的重要部分,因此所有代码不到1000行,但是仍然能够编译模型的forward和backward pass(及其融合,包括 training loop)到单个XLA内核,模型例如VGG19。
我们还演示了Julia的多重调度语义如何在这个转换的规范中提供帮助。这项工作表明,不仅可以将用Julia编写的多个ML模型编译到TPU,而且可以编写更通用的非ML Julia代码(只要这些代码也由线性代数操作控制)。我们希望这可以加速对非ML问题领域的探索,TPU可能对这些领域有用。
-
谷歌
+关注
关注
27文章
6211浏览量
106468 -
编程语言
+关注
关注
10文章
1952浏览量
35244 -
机器学习
+关注
关注
66文章
8460浏览量
133400
原文标题:Jeff Dean推荐:用TPU跑Julia程序,只需不到1000行代码
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论