 深度文本匹配的简介,深度文本匹配在智能客服中的应用
深度文本匹配的简介,深度文本匹配在智能客服中的应用
▌一、深度文本匹配的简介
1. 文本匹配的价值
文本匹配是自然语言理解中的一个核心问题,它可以应用于大量的自然语言处理任务中,例如信息检索、问答系统、复述问题、对话系统、机器翻译等等。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配,对话系统可以归结为前一句对话和回复的匹配,机器翻译则可以归结为两种语言的匹配。
2. 深度文本匹配的优势
传统的文本匹配技术如图1中的 BoW、TFIDF、VSM等算法,主要解决词汇层面的匹配问题,而实际上基于词汇重合度的匹配算法存在着词义局限、结构局限和知识局限等问题。
词义局限:的士和出租车虽然字面上不相似,但实为同一种交通工具;而苹果在不同的语境下表示的东西不同,或为水果或为公司;
结构局限:机器学习和学习机器虽词汇完全重合,但表达的意思不同;
知识局限:秦始皇打 Dota,这句话虽从词法和句法上看均没问题,但结合知识看这句话是不对的。
传统的文本匹配模型需要基于大量的人工定义和抽取的特征,而这些特征总是根据特定的任务(信息检索或者自动问答)人工设计的,因此传统模型在一个任务上表现很好的特征很难用到其他文本匹配任务上。而深度学习方法可以自动从原始数据中抽取特征,省去了大量人工设计特征的开销。首先特征的抽取过程是模型的一部分,根据训练数据的不同,可以方便适配到各种文本匹配的任务当中;其次,深度文本匹配模型结合上词向量的技术,更好地解决了词义局限问题;最后得益于神经网络的层次化特性,深度文本匹配模型也能较好地建模短语匹配的结构性和文本匹配的层次性[1]。
3. 深度文本匹配的发展路线
图 1 深度文本匹配的发展路线
随着深度学习在计算机视觉、语音识别和推荐系统领域中的成功运用,近年来有很多研究致力于将深度神经网络模型应用于自然语言处理任务,以降低特征工程的成本。最早将深度学习应用于文本匹配的是微软 Redmond 研究院。2013年微软 Redmond 研究院发表了 DSSM [2],当时 DSSM 在真实数据集上的效果超过了SOTA(State of the Art);为了弥补 DSSM 会丢失上下文的问题,2014年微软又设计了CDSSM [3];2016年又相继发表了 DSSM-LSTM, MV-DSSM。微软的 DSSM 及相关系列模型是深度文本匹配模型中比较有影响力的,据了解百度、微信和阿里的搜索场景中都有使用。
其他比较有影响的模型有:2014年华为诺亚方舟实验室提出的 ARC-I和ARC-II [4],2015年斯坦福的 Tree-LSTM [5],2016年 IBM 的 ABCNN [6],中科院的 MatchPyramid [7],2017年朱晓丹的 ESIM[8],2018 年腾讯 MIG 的多信道信息交叉模型 MIX [9]。
一般来说,深度文本匹配模型分为两种类型,表示型和交互型。表示型模型更侧重对表示层的构建,它会在表示层将文本转换成唯一的一个整体表示向量。典型的网络结构有 DSSM、CDSMM 和 ARC-I。这种模型的核心问题是得到的句子表示失去语义焦点,容易发生语义偏移,词的上下文重要性难以衡量。交互型模型摒弃后匹配的思路,假设全局的匹配度依赖于局部的匹配度,在输入层就进行词语间的先匹配,并将匹配的结果作为灰度图进行后续的建模。典型的网络结构有 ARC-II、DeepMatch 和 MatchPyramid。它的优势是可以很好的把握语义焦点,对上下文重要性合理建模。由于模型效果显著,业界都在逐渐尝试交互型的方法。

图 2 深度文本匹配模型的类型
▌二、智能客服的简介
1. 智能客服的应用背景
由于人工客服在响应时间、服务时间和业务知识等方面的局限性,有必要研发智能客服系统,使其通过智能化的手段来辅助人工客服为用户服务。智能客服与人工客服的优劣势对比如图 4 所示。
图 3 智能客服与人工客服的优劣势对比
2. 智能客服的核心模块
智能客服的一般框架如图 5 所示:当有 Query 请求时,首先对 Query 进行补全、解析和需求理解;其次,问题召回模块通过精准召回、核心召回和语义召回从 FAQ 库召回与 Query 相关的问题;接着,问题排序模块通过 CTR 模型和相似度模型对召回的问题进行排序,选出 Top k 返回给用户;最后,反馈系统记录用户的点击行为等,对模型进行更新。具体哪些模型会被更新,与语义召回和相似度模型阶段使用的算法有关。
图 4 智能客服的一般框架
在智能客服的框架中,最重要的模块是 FAQ 库的构建、语义召回、相似度模型和模型更新,它们性能的好坏对用户的使用体验有很大影响。
FAQ 库的构建
对于重视用户体验的客服系统来说,FAQ 库的构建是非常严格的,它的内容需要非常完整和标准,不能像聊天机器人那样可以插科打诨。一般的做法是将积累的 FAQ ,或是将场景相关的设计文档、PRD文档中的相应内容整理成 FAQ,添加到 FAQ 库中。日常的维护就是运营人员根据线上用户的提问做总结,把相应的问题和答案加入 FAQ 库。不难想像,随着用户量的增加,用户的问题种类五花八门,问法多种多样,这种维护方式肯定会给运营带来很大的压力,也会给用户带来糟糕的体验。那么,有没有什么自动或是半自动的方法可以解决新问题的挖掘和 FAQ 库的更新?
一种理想的 FAQ 库构建的流程应该是:从客服的直接对话出发,提取出与产品相关的问题,计算问题之间的距离,通过增量聚类的方法把用户相似的问题聚到一起,最后由运营人员判断新增的问题能否进入 FAQ 库,同时将他们的反馈更新给文本匹配模型。
图 5 理想的FAQ 库构建的流程
语义召回
当 FAQ 库达到一定规模时,再让用户请求的 Query 与 FAQ 库中的问题一一计算相似度是非常耗时的,而问题召回模块可以通过某些算法只召回与请求 Query 相关的问题,减少问题相似度模型阶段的复杂度。精准召回和核心召回是基于词汇重合度的检索方法,它们的局限是不能召回那些 FAQ 库中与请求 Query 无词汇重合,但语义表达是一样的问题,而语义召回可以解决此类问题。
相似度模型
相似度模型分别计算召回的相关问题与请求 Query 之间的相似度,作为排序模型的特征之一。需要注意,此处的相似度模型不同于语义召回中的相似度计算,前者更靠近输出端,对准确率要求高;后者对召回率要求高。因此,这两个模块在实现时使用的模型往往不同,在我们的文本匹配引擎中,语义召回使用的是基于表示型的深度文本匹配模型,相似度模型使用的是基于交互型的深度文本匹配模型和其他传统文本匹配模型的混合模型。
模型更新
智能客服投入线上使用后,用户 query 可能与某些模型的训练数据分布不一致,导致智能客服的响应不理想。因此,十分有必要从收集到的用户行为数据中挖掘相关知识,并更新相关模型。
▌三、深度文本匹配在智能客服中的应用
1. 为什么使用深度文本匹配
问题聚类、语义召回和相似度模型都可以归结为文本匹配问题。传统智能客服在这些模块中使用的是传统文本匹配方法,不可避免地会遇到词义局限、结构局限和知识局限等问题;加上传统文本匹配方法多是无监督的学习方法,那么由这些方法训练的模型就无法利用运营人员的反馈和用户的点击行为等知识。然而,使用深度文本匹配的方法则可以有效地解决这些弊端。具体改进方面如图 6 所示。
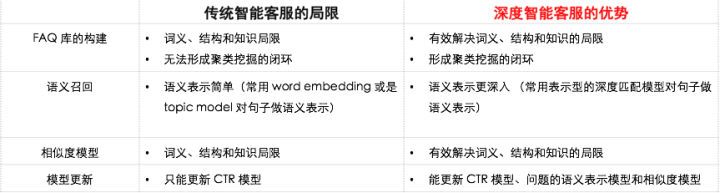
图 6 深度文本匹配对传统智能客服的改进
2. 怎么样使用深度文本匹配
我们曾在智能客服的不同领域中尝试过多种深度文本匹配方法,通过业务场景推动技术演进的方式,逐淅形成了一套成熟的文本匹配引擎。我们的文本匹配引擎除了使用传统的机器学习模型(如话题匹配模型、词匹配模型、VSM等)外,还使用了基于表示型和基于交互型的深度文本匹配模型。
深度文本匹配模型
Representation-based Model
表示型的深度文本匹配模型能抽出句子主成分,将文本序列转换为向量,因此,在问题聚类模块,我们使用表示型的深度文本匹配模型对挖掘的问题和 FAQ 库的问题做预处理,方便后续增量聚类模块的计算;在语义召回模块,我们使用表示型的深度文本匹配模型对 FAQ 库的问题做向量化处理,并建立索引,方便问题召回模块增加对用户 query 的召回。另外,我们使用基于 Bi-LSTM 的表示型模型以捕获句子内的长依赖关系。模型结构如图 7 所示。
图 7 基于 Bi-LSTM 的表示型模型
我们在相似度模型模块使用了基于交互型的深度文本匹配模型 MatchPyramid,其原因有三点:
第一点,表示型的深度文本匹配模型对句子表示时容易失去语义焦点和发生语义偏移,而交互型的深度文本匹配模型不存在这种问题,它能很好地把握语义焦点,对上下文重要性进行合理建模。
第二点,在语义召回阶段,用户 query 与召回问题间的语义相似度会作为排序模型的特征之一,同样地,相似度模型阶段,用户 query 与召回问题间的另一种语义相似度也会作为排序模型的特征之一。
第三点,相似度模型需要实时计算,用户每请求一次,相似度模型就需要计算 n 个句对的相似度,n 是问题召回的个数。而序列型的神经网络不能并行计算,因此我们选择了网络结构是 CNN 的 MatchPyramid 模型。模型结构如图 8 所示。

图 8 An overview of MatchPyramid on Text Matching
文本匹配引擎
由于自然语言的多样性,文本匹配问题不是某个单一模型就能解决的,它涉及到的是算法框架的问题。每个模型都有独到之处,如何利用不同模型的优点去做集成,是任何文本匹配引擎都需要解决的问题。我们的文本匹配引擎融合了传统文本匹配模型和深度文本匹配模型,具体的框架如图 9 所示。

图 9 文本匹配引擎的框架
3. 深度智能客服的效果评测
应用上述的文本匹配引擎后,我们为某汽车公司开发的智能客服系统,在测试集上的 precision 达到了 97%;与某寿险公司合作完成的智能客服,其 precision 比 baseline 高出 10 个点。除此之外,在对话系统的音乐领域中,使用深度文本匹配引擎替代模糊匹配后,整体 precision 提高了 10 个点;在通用领域的测试集上,我们的文本匹配引擎也与百度的 SimNet 表现不相上下。
-
计算机视觉
+关注
关注
8文章
1698浏览量
46015 -
机器学习
+关注
关注
66文章
8422浏览量
132714 -
深度学习
+关注
关注
73文章
5504浏览量
121222
原文标题:深度文本匹配在智能客服中的应用
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问DAC5682z内部FIFO深度为多少,8SAMPLE具体怎么理解?
如何使用自然语言处理分析文本数据
NPU在深度学习中的应用
图纸模板中的文本变量
如何在文本字段中使用上标、下标及变量

手写图像模板匹配算法在OpenCV中的实现

使用语义线索增强局部特征匹配

【《大语言模型应用指南》阅读体验】+ 基础知识学习
如何学习智能家居?8:Text文本实体使用方法

利用TensorFlow实现基于深度神经网络的文本分类模型
卷积神经网络在文本分类领域的应用
电路的阻抗如何匹配







 工商网监
工商网监
评论