 OpenAI的研究人员提出了一种全新的AI安全策略——迭代放大法
OpenAI的研究人员提出了一种全新的AI安全策略——迭代放大法
近日,OpenAI的研究人员提出了一种全新的AI安全策略——迭代放大法(iterated amplification),通过描述如何将一个复杂的任务分解成简单的子任务而不是提供标签数据或奖励函数,实现了对于复杂行为和目标的描述。虽然这一方法还处于比较初级的阶段,但研究人员认为这种方法将为AI安全提供一种大规模的实现手段。
如果我们想要训练一个机器学习模型完成特定的任务,我们一定需要训练信号来评价模型的表现并帮助模型不断学习和改进。例如监督学习中的标签和强化学习中的奖励函数就是训练讯号。机器学习体系中的一个重要假设就是这些讯号已经存在,并且算法可以按照它来学习。但实际情况是训练信号可能来自于不知道的某个地方。如果我们没有训练信号就意味着我们没有办法学习。如果我们得到的是错误信号,那么算法可能会得到无意识的甚至危险的结果。所以对于新的任务和AI安全来说,提高得到训练讯号的能力是十分必要且极具价值的。
那么让我们看看目前是怎么获取训练信号的呢?有时候我们可以利用算法得到,比如在围棋游戏中可以通过计数评分得到信号。不过大多数真实世界的任务并没有一个数学形式表达的信号,但通常我们可以人工的手段来获取训练信号。但实际情况是,很多复杂的任务已经远远超过了人类的认知能力,我们没办法判断模型的输出是否正确,例如设计一个复杂的运输系统或者管理庞大计算机网络安全细节的管理系统这样的任务,或者是预测全球长期气候趋势这种复杂的任务。
需要不同训练信号的问题,训练序号可以来自表达式评价、人类反馈,但有的任务超出了人类的能力。
本文提出的迭代放大,是一种在确定性假设下为后续任务生成训练假设的方法。实际上,虽然人类不能在全局上直接把握复杂的问题,但我们可以假设人类可以有效的评估复杂任务中的一小块任务是否符合要求。例如在计算机网络安全的例子中,人们可以将“防御一系列针对于服务器和路由器的攻击”分解为“针对服务器的攻击”和“针对路由的攻击”以及“两个攻击间可能的相关性”。此外,我们还可以假设,人类可以承担很少的一部分任务,例如“识别出日志中的一行可疑记录”。如果人类的分解任务能力和分担任务能力得以落实,这两项假设得以成立,那我们就可以为一项庞大的任务建立训练信号,这些讯号来自于人类针对分解任务讯号的组合。
迭代放大的机制
研究人员在实际训练放大的过程中,首先训练AI系统从一个很小的子任务开始学习,通过寻求人类的帮助(标签/奖励信号)来学会解决这一子问题。随后让系统学习一个稍大的问题,这时候需要人类将较大的任务进行分解,AI系统依靠上一步的学习来解决这些问题。研究人员将这种解决方案用于那些稍微困难的问题,在这些问题中系统从人类处得到训练信号,来直接训练二级任务(此时无需人类帮助)。
随着训练的进行,研究人员继续为AI提供更为复杂的复合任务,不断构建出训练信号。如果这个过程得以完成,AI系统将学会解决高度复杂的问题,尽管这个系统一开始没有从任务中获得直接的训练信号。
这一过程在一定程度上与AlphaGo Zero专家迭代过程很像,不过个专家迭代在强化现存的训练信号,而迭代放大则从零开始构建训练信号。它也和最近的一些问题分解的算法很像,但区别在于它可以用于没有先前训练信号的问题。
实 验
先前的实验表明,直接用AI系统解决超越人类能力的问题十分困难,同时利用人类作为训练信号也会引入复杂性。所以研究人员的第一个实验在于尝试放大了算法的训练信号,来验证这种方法可以在简单任务的有效性。同时也限制了对于监督学习的注意力。研究人员在5个示例算法任务上进行了尝试。这五个算法示例都有具体的数学表达,但研究人员先排除算法信号,了利用一步步从简单到复杂的方法从零开始解决。利用迭代放大的方法,从一些不直接的子任务中间接学习出训练信号。
在五个任务中(排列、序列赋值、通配符匹配、最短路径、查找并集),新的方法可以与表达式方法获得同等甚至更好的效果。

在没有label的情况下迭代放大法获得了与监督学习相同甚至更好的结果
放大法在寻求解决那些超越人类直接认知和能力的问题,通过迭代的过程使得人类可以提供间接的监督信号。这项工作同时也建立在人类反馈的基础上,通过实现奖励预测系统,接下来的版本将会包含来自于真实人类的反馈。目前研究人员仅仅在探索的初级阶段,随着研究的深入和规模的扩大将会为很多复杂的问题带来新的可能。
人类反馈
-
AI
+关注
关注
87文章
31977浏览量
270786 -
函数
+关注
关注
3文章
4350浏览量
63090 -
机器学习
+关注
关注
66文章
8457浏览量
133203
原文标题:OpenAI提出全新AI安全策略—迭代放大法,助力机器实现复杂目标学习
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ZigBee接入EPA网络的安全策略
一种参数自调节优化控制策略
一种参数自调节优化控制策略
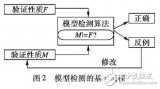
基于多维整数空间的安全策略冲突检测与消解
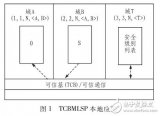
基于可信计算的多级安全策略TCBMLSP分析
研究人员提出了一种柔性可拉伸扩展的多功能集成传感器阵列





 工商网监
工商网监
评论