 如何选合适的AI硬件加速方案
如何选合适的AI硬件加速方案
从很多方面来看,AI加速热潮与1990年代末期和2000年代初的DSP淘金热很类似;在那个时候,随着有线和无线通信起飞,市场上纷纷推出高性能DSP协同处理器(co-processor)以因应基带处理的挑战。与DSP协同处理器一样,AI加速器的目标是找到最快速、最节能的方法来执行所需的运算任务。
从云端的大数据(big data)处理到边缘端的关键词识别和影像分析,人工智能(AI)应用的爆炸式成长促使专家们前仆后继地开发最佳架构,以加速机器学习(ML)算法的处理。各式各样的新兴解决方案都凸显了设计人员在选择硬件平台之前,明确定义应用及其需求的重要性。
从很多方面来看,AI加速热潮与1990年代末期和2000年代初的DSP淘金热很类似;在那个时候,随着有线和无线通信起飞,市场上纷纷推出高性能DSP协同处理器(co-processor)以因应基带处理的挑战。与DSP协同处理器一样,AI加速器的目标是找到最快速、最节能的方法来执行所需的运算任务。
神经网络处理背后的数学,涉及统计学、多元微积分(multivariable calculus)、线性代数、数值优化(numerical optimization)和机率等;虽然很复杂,也是高度可平行化的(parallelizable)。但事实上这是令人尴尬的可平行化──与分布式计算不同,在路径的输出被重组并产生输出结果之前,很容易被分解为没有分支(branches)或从属关系(dependencies)的平行路径。
在各种神经网络算法中,卷积神经网络(CNN)特别擅长对象识别类任务——也就是从影像中过滤筛选出感兴趣的对象。CNN以多维矩阵(multidimensional matrices)──即张量(tensor)──架构来理解资料,将超出第三个维度的每个维度都嵌入到子数组中(如图1),每个添加的维度称为“阶”(order),因此,五阶张量会有五个维度。
图1:CNN以张量架构摄取数据,也就是可被可视化为3D立方体的数字矩阵(数据集);每个数组中还有一个子数组,该数字定义了CNN的深度。
与数学相关度不高,AI重点在于快速反复运算
这种多维分层对于理解CNN所需之加速的本质很重要,卷积过程使用乘法在数学上将两个函数“卷绕”(roll)在一起,因此广泛使用乘加(multiply-accumulate,MAC)数学运算;举例来说,在对象识别中,一个函数是源影像,另一个函数是用来识别特征然后将其映像到特征空间的过滤器(filter)。每个过滤器都要多次执行这种“卷绕”,以识别影像中的不同特征,因此数学运算变得非常重复,且是令人尴尬(或令人愉悦)的可平行化。
为此,某些AI加速器的设计采用多个独立的处理器核心(高达数百或上千个),与内存子系统一起整合在单芯片中,以减轻数据存取延迟并降低功耗。然而,由于业界已设计了绘图处理器(GPU)来对图像处理功能进行高度平行处理,因此它们对于AI所需的这种神经网络处理也可以实现很好的加速。AI应用的多样性和深度,特别是在语音控制、机器人、自动驾驶和大数据分析等方面,已经吸引了GPU供应商将重点转移到AI处理硬件加速的开发。
然而AI硬件加速的问题,在于有如此多的数据,所需的准确性和响应时间又有如此大的差别,设计人员必须对于架构的选择非常讲究。例如数据中心是数据密集型的,其重点是尽可能快速处理数据,因此功耗并非特别敏感的因素——尽管能源效率有利于延长设备使用寿命,降低设施的整体能耗和冷却成本,这是合理的考虑。百度的昆仑(Kunlun)处理器耗电量为100W,但运算性能达到260 TOPS,就是一款特别适合数据中心应用的处理器。
接下来看另一个极端的案例。如关键词语音识别这样的任务需要与云端链接,以使用自然语言识别来执行进一步的命令。现在这种任务在采用法国业者GreenWaves Technologies之GAP8处理器的电池供电边缘设备上就可以实现;该处理器是专为边缘应用设计,强调超低功耗。
介于中间的应用,如自动驾驶车辆中的摄影机,则需要尽可能接近实时反应,以识别交通号志、其他车辆或行人,同时仍需要最小化功耗,特别是对于电动车来说;这种情况或许需要选择第三种方案。云端连结在此类应用中也很重要,如此才能实时更新所使用的模型和软件,以确保持续提高准确度、反应时间和效率。
ASIC还不足以托付AI加速任务
正因为这是一个在软、硬件方面都迅速发展,需要在技术上持续更新的领域,并不建议将AI神经网络(NN)加速器整合到ASIC或是系统级封装(SiP)中——尽管这样的整合具有低功耗、占用空间小、成本低(大量时)和内存访问速度快等优点。加速器、模型和神经网络算法的变动太大,其灵活性远超过指令导向(instruction-driven)方法,只有像Nvidia这种拥有先进技术、资金雄厚的玩家才能够负担得起不断在硬件,而在硬件上根据特定方法进行迭代。
这种硬件加速器开发工作的一个很好的例子,就是Nvidia在其Tesla V100 GPU中增加了640个Tensor核心,每个核心在一个频率周期内可以执行64次浮点(FP)融合乘加(fused-multiply-add,FMA)运算,可为训练和推理应用提供125 TFLOPS的运算性能。借助该架构,开发人员可以使用FP16和FP32累加的混合精度(mixed precision)进行深度学习训练,指令周期比Nvidia自家上一代Pascal架构高3倍。
混合精度方法很重要,因为长期以来人们已经认识到,虽然高性能运算(HPC)需要使用32~256位FP的精确运算,但深度神经网络(DNN)不需要这么高的精度;这是因为经常用于训练DNN的反向传播算法(back-propagation algorithm)对误差具有很强的弹性,因此16位半精度(FP16)对神经网络训练就足够了。
此外,储存FP16数据比储存FP32或FP64数据的内存效率更高,从而可以训练和部署更多的网络,而且对许多网络来说,8位整数运算(integer computation)就足够了,对准确性不会有太大影响。
这种使用混合精度运算的能力在边缘甚至会更实用,当数据输入的来源是低精度、低动态范围的传感器——例如温度传感器、MEMS惯性传感器(IMU)和压力传感器等——还有低分辨率视频时,开发人员可以折衷精度以取得低功耗。
AI架构的选择利用雾计算从边缘扩展至云端
可扩充处理(scalable processing)的概念已经扩展到更广泛的网络——利用雾运算(fog computing)概念,透过在网络上的最佳位置执行所需的处理,来弥补边缘和云端之间的能力差距;例如可以在本地物联网(IoT)网关或更接近应用现场的本地端服务器上进行神经网络图像处理,而不必在云端进行。这样做有三个明显的优势:一是能减少由于网络等待时间造成的时延,二来可以更安全,此外还能为必须在云端处理的数据释出可用的网络带宽;在更高的层面上,这种方法也通常更节能。
因此,许多设计师正在开发内建摄影机、影像预处理和神经网络AI信号链(signal chains)功能的独立产品,这些产品仅在相对较闭回路(closed-loop)的运作中呈现输出,例如已识别标志(自驾车)或人脸(家用安防系统)。在更极端的案例中,例如设置在偏远或难以到达之处,以电池或太阳能供电的设备,可能需要长时间地进行这种处理。
图2:GreenWave的GAP8采用9个RISC-V处理器核心,针对网络边缘智能设备上的低功耗AI处理进行了优化。
为了帮助降低这种边缘AI图像处理的功耗,GreenWaves Technologies的GAP8处理器整合了9个RISC-V核心;其中一个核心负责硬件和I/O控制功能,其余8个核心则围绕共享数据和指令内存形成一个丛集(如图2)。这种结构形成了CNN推理引擎加速器,具备额外的RISC-V ISA指令来强化DSP类型的运算。
GAP8是为网络边缘的智能设备量身打造,在功耗仅几十毫瓦(mW)的情况下可实现8GOPS运算,或者在1mW时可实现200 MOPS运算;它完全可以用C/C++语言来编程,最小待机电流为70nA。
AI处理器架构比一比:RISC-V vs. Arm
RISC-V开放性硬件架构在一开始遭到质疑,因为那需要一个忠实稳固的使用者社群,以提供一系列丰富的支持工具和软件;而随着该架构透过各种测试芯片和硬件实作吸引更多开发者加入,那些质疑也逐渐消退。RISC-V吸引人之处在于它正成为Arm处理器的强劲对手,特别是在超低功耗、低成本应用上;只要谈到低成本就会锱铢必较,因此免费方案总是会感觉比需要支付授权费的方案更好。
不过虽然RISC-V架构的GAP8可以节能并且针对边缘神经网络处理进行了高度优化,从系统开发的角度来看仍然需要考虑周边功能,例如摄影机传感器本身和网络通讯接口,以及是采用有线还是无线技术等;依据系统通讯和处理影像的次数频率,这些功能占用的功耗比例可能较高。根据GreenWaves的说法,GAP8若采用3.6Wh的电池供电,能以每3分钟分类一张QVGA影像的频率持续工作长达10年;但该数字并未考虑整体系统中其他因素的影响。
GreenWaves将其GAP8处理器与采用Arm Cortex-M7核心、运作频率216MHz的意法半导体(ST)处理器STM32 F7进行了直接比较(图3);两者以CIFAR-10数据集的影像进行训练,权重量化为8位定点(fixed point)。
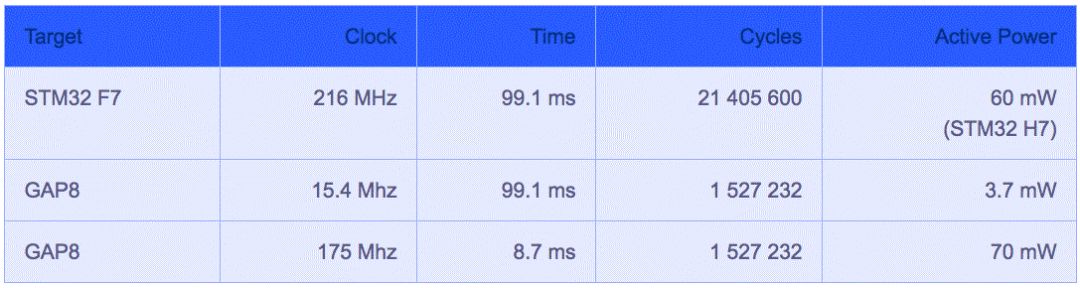
图3:GreenWaves Technologies的GAP8与ST的STM32 F7处理器性能比较。
虽然GAP8因为拥有八核心架构而呈现更高效率,并能以较低时钟速率与更少的周期实现推理,Arm架构也不遑多让──Arm已经发表了针对行动设备和其他相邻、网络边缘应用的机器学习(ML)处理器,其应用场景包括AR/VR、医疗、消费性电子产品以及无人机等;该架构采用固定功能引擎(fixed-function engines)来执行CNN层,并采用可程序化层(programmable layer)引擎来执行非卷积层以及实现所选基元(primitive)和运算符(operator),参考图4。
图4:Arm的ML处理器设计用于CNN类型固定功能以及可程序化层引擎的低功耗边缘处理。
有趣的是,ML处理器是以高度可扩充架构为基础,因此同一处理器和工具可用于开发从物联网到、嵌入式工业和交通,到网络处理和服务器等各种应用,运算性能要求从20 MOPS到70 TOPS以上不等。
如果开发团队希望从云端往下扩充,或从边缘往上扩充,那么这种可扩充性比较适合之前讨论的雾运算概念。此外该处理器本身与主流神经网络学习框架紧密整合,例如Google的TensorFlow和TensorFlow Lite,以及Caffe和Caffe 2;它还针对Arm Cortex CPU和Arm Mali GPU进行了优化。
在异构处理体系架构中部署AI
透过ML处理器,Arm还强调了异质(heterogenous)方法对AI应用之神经网络的重要性,但仅限于其CPU和GPU的狭窄范围内。从更广泛的角度来看,英特尔(Intel)的OpenVINO (Visual Inference & Neural Network Optimization,视觉推理和神经网络优化)工具套件可以实现异质混合架构的开发,包括CPU、GPU与FPGA,当然还有英特尔自家的Movidius视觉处理器(VPU)和基于Atom的图像处理器(IPU)。利用通用API以及针对OpenCV和OpenVX优化的呼叫(call),英特尔声称其深度学习性能可以提高19倍。
异质方法对于针对AI的神经网络处理既有好处又不可或缺;当从头开始一个设计,这种方法能开启更多的处理可能性和潜在的优化机会。但许多嵌入式系统已经部署了相关硬件,通常是混合了MCU、CPU、GPU和FPGA,因此如果有开发工具可以在这样的已设置硬件基础上开发AI应用,并透过单一API进行相对应的优化(假设像OpenVINO这样的工具套件是与底层硬件兼容),可以解决很多问题。
百度將AI處理性能推向新高
在今年7月初于北京举行的百度开发者大会Create 2018上,该公司发表了昆仑(图5),号称是中国首款从云端到边缘的AI芯片组,包括818-300训练芯片和818-100推理芯片。
图5:百度的昆仑是中国第一款从云端到边缘的AI处理器芯片组,虽然其架构细节尚未公布,但号称比百度2011年发表、基于FPGA的AI加速器快30倍。
昆仑号称比百度2011年发表、基于FPGA的AI加速器快30倍,达到260 TOPS@100W;该芯片将采用三星(Samsung)的14纳米工艺,内存带宽为512GB/s。虽然百度尚未公布其架构参数,但它可能包含数千个核心,能为百度自己的数据中心进行巨量数据的高速平行处理;该公司也有计划针对各种客户端设备和边缘处理应用推出低性能版本。
在百度的昆仑发表前不久,Google于5月份也发表了TPU 3.0;Google并未透露该芯片细节,只说速度比去年的版本快8倍,达到100 PFLOPS。
使用现有技术来启动AI设计
虽然还有许多其他新兴的神经网络处理架构,如果是对“运算性能vs.实时性能要求”有合理期望,目前也有许多处理器和工具套件能充分满足边缘运算需求。例如,基本的家用保全系统可能包括一台摄影机,负责人脸识别处理并透过Wi-Fi连接到家庭网关或路由器,这用市面上现有的处理器或工具套件就可以实现。
想尝试这种设计的开发人员不必从零开始,而是只要选择一个已经获得广泛支持的平台,具备各种CPU、视频与图片处理GPU、高速内存、内建无线和有线通讯模块,还有恰当的操作系统支持和广泛、活跃的用户生态系统。
图6:NXP的i.MX 8M解决了快速启动开发的问题,同时还可以使用基于Arm的处理器来扩展AI应用。
恩智浦半导体(NXP)的i.MX 8M就是一个合适的起点(图6)。该方案实际上是一系列处理器,配备最多达四个的1.5GHz Arm Cortex-A53和Cortex-M4核心;内含两个GPU类型处理器,一个可用于影像预处理,另一个用于神经网络加速。
另一个关键设计需求是现场使用寿命要够长,也就是系统要能够耐受恶劣使用环境,特别像是安装在室外的摄影机;还要能随着时间持续更新。后者特别重要,因为设计人员得确保设计中预留足够的空间,以便在功能增加时实现更高的处理性能要求;同时还要保证低功耗,特别是对电池供电产品来说。
AI加速的重要性在于,其处理能力需求正从传统的CPU和FPGA转移到GPU和VPU,或者所有以上处理器的异质组合;当然这取决于应用。在此同时,即使针对越来越庞大数据集的AI加速成为主流,CPU的关键控制功能仍将保持不变。
-
无线通信
+关注
关注
58文章
4567浏览量
143520 -
AI
+关注
关注
87文章
30829浏览量
268982
原文标题:如何针对不同的应用,选合适的AI硬件加速方案?
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

适用于数据中心应用中的硬件加速器的直流/直流转换器解决方案

西门子推出Catapult AI NN软件,赋能神经网络加速器设计
PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?
新思科技硬件加速解决方案技术日在成都和西安站成功举办
Elektrobit利用其首创的硬件加速软件优化汽车通信网络的性能

【国产FPGA+OMAPL138开发板体验】(原创)7.硬件加速Sora文生视频源代码
音视频解码器硬件加速:实现更流畅的播放效果






 工商网监
工商网监
评论