 传统去除马赛克的方法,如何通过多帧画面去除马赛克的原理
传统去除马赛克的方法,如何通过多帧画面去除马赛克的原理

本文来自Google AI博客,介绍了传统去除马赛克的方法,以及如何通过多帧画面去除马赛克的原理。但在手机上应用这一技术,需要面对不少挑战。感谢快手图像算法工程师章佳杰的翻译。
一直以来, 对移动设备上的数码相机来说, 数码变焦 (非光学变焦) 就是一个 "丑小鸭". 相对数码单反的光学变焦能力而言, 移动设备上的数码变焦拍摄的图片质量是无法与单反相机的光学变焦的图片质量相提并论的。传统观点认为, 单反变焦镜头的复杂光学和机械结构有其优越性, 更紧凑的移动设备上的数码相机即使加上聪明的算法也并不能取代之.
有了 Pixel 3 上全新的超分辨变焦 (Super Res Zoom) 技术, 我们正在挑战这一传统观点。
Pixel 3上的超分辨变焦技术优于以前的数码变焦技术是由于它可以直接将多帧图像合成为一张高分辨率图像,而不是像之前的数码变焦技术仅仅基于单张图片的裁剪并放大的策略。这种多帧图像的合成技术可以得到细节大幅提升的结果, 几乎可以与其他智能手机上 2x 光学变焦的结果相媲美。超分辨变焦意味着, 与先按下快门然后裁剪放大相比, 先捏指缩放画面来变焦, 然后按下快门, 你能得到更多的细节。
2x 变焦对比: Pixel 2 vs. Pixel 3 上的超分辨变焦
数码变焦的难点
数码变焦是一项困难的工作, 因为一个好的算法必须从一个低分辨率的图像出发, 可靠地 "重构" 出丢失的细节。典型的数码变焦是对单张图像的一小部分进行裁剪并放大而得到一张更大的图像。传统算法是用线性插值的方法来完成的,线性插值尝试生成原图中没有的细节, 但是这带来了模糊, 或者称之为 "塑料感", 缺乏细节和纹理。相对而言, 大多数现代的单图放大算法使用了机器学习的手段 (包括我们早先的工作,RAISR)。这些方法能放大特定的图像特征, 比如直线边缘, 甚至可以合成一些纹理, 但是不能恢复出高分辨率的自然细节。虽然我们仍旧在用 RAISR 对图像视觉质量进行增强, 但是分辨率方面的提升 (至少对大多数变焦倍数比如 2-3x), 更多的来自于我们的多帧方法, 超分辨变焦技术。
色彩滤镜阵列与去马赛克
重建精细细节是非常困难的, 因为数码照片本身是不完整的, 一张数码照片实际上是从一部分的颜色信息重建而来的, 这称为去马赛克的过程。在典型的消费级数码相机中, 相机传感器元件仅能记录光的强度, 而不是直接记录颜色。为了捕捉场景中存在的真实颜色, 相机使用放在传感器前面的色彩滤镜阵列, 以便每个像素仅记录单一颜色 (红色, 绿色或蓝色),这些滤镜以拜耳模式(Bayer Pattern)排列, 如下图所示。
拜耳色彩滤镜马赛克阵列示意图:每一个 2x2 的像素组通过一个特定的色彩滤镜记录光线的颜色,两个绿色像素 (因为人的眼睛对绿色的光线更敏感), 一个红色像素, 一个蓝色像素. 这种模式不断重复, 填满整个画面。
然后相机内部的处理流程必须重建真实颜色和所有像素的所有细节。(注:值得注意的是, 在某种程度上这个情况与我们的视觉系统相似。在人类和其他哺乳动物的眼睛中, 不同的视锥细胞对不同的颜色敏感, 最后大脑填充了剩下的细节以重建完整的图像。) 算法通常会从附近像素中的颜色进行插值, 对缺失的颜色信息进行最佳猜测, 以此来完成去马赛克的过程, 这意味着 RGB 数码照片的三分之二像素实际上是通过重建得到的!
去马赛克的过程, 使用了相邻像素来重建丢失的颜色信息。
在最简单的情形中, 去马赛克可以通过对相邻像素值进行平均来实现。虽说大多数真正的去马赛克算法比这更为复杂, 但受限于本质上的信息不完整, 这些算法仍然会导致不完美的结果和伪像。这种情况即使是大画幅的数码单反相机也存在, 但是它们的传感器和镜头更大, 在典型情况下, 单反能比移动设备相机记录更多的细节。
如果你在移动设备上捏指缩放进行变焦 (数码变焦), 算法不得不从附近像素再一次插值来构成更多信息, 情况会变得更差。但 (在成像过程中) 并非所有信息都丢失了, 即使受到移动设备光学系统限制, 也可以使用连拍摄影和多帧图像融合来实现超分辨率。
从连拍摄影到多帧超分
虽然单幅图片不能提供足够的信息来填充缺失的颜色, 但我们可以从连续拍摄的多帧图像中获取一些缺少的信息。拍摄并融合多帧连续照片的过程称为连拍摄影,在 Nexus 和 Pixel 手机上成功应用的谷歌 HDR+ 算法就使用了多帧的信息, 使手机拍摄的照片能达到更大传感器的画质水平。我们是否可以采用类似的方法来提高图像分辨率?
其实这个方法已经有十多年的历史, 在包括天文学领域。其基本概念被称为 "drizzle", 对从略微不同的位置拍摄的多个图像进行融合, 在 2x 低放大率下或 3x 而照明条件良好的情况下, 可以产生相当于光学变焦的分辨率。这就是多帧超分辨率算法, 通常的思路是将低分辨率连拍摄影的图像直接进行对齐, 然后合并到所需 (更高) 分辨率的像素网格上。以下是理想化的多帧超分辨率算法如何工作的示例:
标准去马赛克过程 (最上一排) 需要对确实的颜色进行差值。与此相比, 理想情况下, 每一帧图像水平或垂直移动一个像素, (多帧超分辨率算法) 可以从这些图像获得信息来填充缺失的颜色。
在上面的例子中, 我们拍摄了 4 帧, 其中三帧正好移动了一个像素, 分别是水平方向, 垂直方向, 水平和垂直两个方向。这样的话, (利用这些移动了的图像上的像素值) 所有缺失的颜色都会得到补充, 根本不需要任何去马赛克的过程! 实际上, 一些数码单反相机就支持这种操作, 但只有当相机在三脚架上时, 传感器/光学器件才会主动移动到不同位置,这有时被称为 "microstepping"。
多年来, 这种用于更高分辨率成像的 "超分辨率" 方法的实际应用仍主要限于实验室用途, 或用于某些受控环境下, 传感器和拍摄主体之间可以对齐, 人们可以控制或严格限制它们之间的移动。例如, 在天文摄影中, 望远镜是固定的, 望远镜拍摄的天空区域是移动的, 而天空的移动是可预测的。但在像现代智能手机这样广泛使用的成像设备上, 在需要放大的场合 (如移动相机数码变焦) 实际使用超分辨率算法, 仍然大部分情况下都无法实现。
部分原因是, 为了使算法正常工作, 需要满足某些条件。首先, 也是最重要的一点是, 镜头分辨率要比使用的传感器本身更高 (相比之下, 你可以想象这样一种情况, 即镜头的设计非常糟糕, 以至于采用更好的传感器不会带来任何好处)。这种特性通常带来我们不喜欢的图像瑕疵,也就是数码相机中的混叠现象。
图像混叠
当相机传感器无法忠实地记录场景中存在的所有图案和细节时, 会产生混叠效应。混叠的一个很好的例子是摩尔纹, 有时可以在电视上看到, 由于不幸地选择了一件条纹衣服, 拍摄的画面中有明显的摩尔纹 (https://www.youtube.com/watch?v=jXEgnRWRJfg)。此外, 当物体在场景中移动时, 物理特征 (例如桌子的边缘) 的混叠效果会发生变化。你可以在以下连拍序列中观察到这一点, 其中, 连拍序列期间相机的轻微运动会产生时变混叠效果:
左图: 高分辨率单图, 桌子的边缘与高频模式的背景。右图: 连拍序列中的不同帧。不同帧之间, 混叠效应和摩尔纹现象很明显, 像素看起来在跳动, 产生了不同的彩色条纹。
然而, 这种现象对我们来说是一种幸运。如果我们分析产生的条纹, 可以知道它提供了不同像素的颜色和亮度值信息, 正如前一节所述,我们可以借此实现超分辨率。虽说如此, 许多挑战仍然存在. 因为实际上用户会手持手机, 拍摄一组连拍序列, 超级分辨率算法需要在任何情况下都能奏效。
利用手震进行实际超分辨率合成
如前所述, 一些数码单反相机提供了特殊的三脚架超分辨率模式, 其工作方式与我们到目前为止所描述的方式类似。这些方法依赖于相机内部的传感器和光学器件的物理移动, 但是这些方法需要相机完全稳定, 而这在移动设备中是不切实际的。移动设备几乎总是手持的,这似乎给移动平台上的超分辨率成像制造了一个障碍。
然而, 我们通过利用人手的自然动作来克服这种困境。当我们用手持相机或手机拍摄一连串照片时, 每一帧的图片之间总会有一些移动,光学防抖 (OIS) 系统可以补偿大的相机运动, 比如相隔 1/30 秒的连续帧之间通常为 5-20 像素, 但无法完全消除更快, 更低幅度, 自然的手震。这种手震所有人都有 (即使是那些 "铁手" 也会有轻微的手震)。当使用高分辨率传感器的手机拍摄照片时, 手震的幅度仅为几个像素。
对多帧图像全局对齐, 裁剪之后, 很明显能看出手震效应。
为了利用手震, 我们首先需要将图像对齐在一起。我们选择连拍中的单帧图像作为 "基础" 或参考帧, 并相对于它对齐其余每帧。对齐后, 图像大致组合在一起, 如前文所示。当然,手震不太可能恰好把图像移动单个像素, 因此我们在将颜色填入参考帧的像素网格之前, 需要在每个新帧中的相邻像素之间进行插值。
即使当设备完全稳定 (例如放置在三脚架上) 而不存在手震时, 我们仍然可以通过强制 "摇晃" 相机来强制 OIS 模块在镜头之间轻微移动来模拟自然手震。这种动作非常小, 不会干扰正常照片,但你可以这样来观察到, 将手机完全静止, 例如将其按在窗户上, 然后在取景器里捏指缩放到最大放大率, 在 Pixel 3 上自行观察, 在远处的物体中可以看到一个微小但连续的椭圆运动, 如下图所示。
克服超分辨率的难点
我们上面给出的理想过程的描述听起来很简单, 但超分辨率并不那么容易。有很多原因导致它没有被广泛用于手机等消费产品, 我们需要在算法上进行重要的创新。难点包括:
1. 即使在良好的照明条件下, 连拍序列中的单个图像也会产生噪声。对一个实用的超分辨率算法来说, 算法需要知道这种噪声, 并尽量忽略这些噪声。我们不希望得到一个高分辨率的带噪声图像, 我们的目标是既增加分辨率又产生更少噪声的结果。
2. 连拍图像之间的运动不仅限于相机的运动。场景中可能会有复杂的运动, 例如风吹过的树叶, 在水面上移动的涟漪, 汽车, 移动的人, 人也会改变他们的面部表情, 或者火焰的闪烁, 甚至有一些不能进行单一的运动估计的情况, 有些物体是透明的或多层的, 例如烟雾或玻璃. 完全可靠的局部对齐通常是不现实的, 即使运动估计不完美, 超分辨率算法也需要运算正确。
3. 由于大部分运动是随机的, 即使存在良好的对齐, 数据在图像的某些区域可能是密集的, 而在另一些区域则是稀疏的。超分辨率的关键是一个复杂的插值问题, 而算法的目标是在整个像素网格的所有部分都中生成更高分辨率的图像, 数据的不规则散布使得这项任务变得更具有挑战性。
所有上述困难似乎使现实世界的超分辨率在实践中不可行, 或者至多仅限于静态场景和放置在三脚架上的相机. 借助 Pixel 3 上的超分辨变焦技术, 我们开发出一种稳定而准确的方法, 用于连拍照片分辨率提升, 该方法使用自然的手部动作, 并且足够稳健且高效, 可以部署在手机上。
以下是我们对其中一些困难是如何克服的:
1. 为了有效地合并连拍中的帧, 并为每个像素生成红绿蓝像素值值, 从而不需要去马赛克, 我们开发了一种在帧之间融合信息的方法。该方法自适应地考虑了图像的边缘信息。具体来说, 我们分析输入帧, 调整融合的方法, 在增加细节和分辨率, 与减少噪声和平滑图像之间做权衡。我们通过沿着明显边缘的方向合并像素, 而不是跨越边缘来实现这一点。实际效果是我们的多帧方法在降噪和细节增强之间提供了最佳的平衡。
左图: 降噪和超分辨之间没有达到最优权衡。右图: 降噪和超分辨之间更好的权衡。
2. 为了使算法可靠地处理具有复杂局部运动 (人, 车, 水或树叶移动) 的场景, 我们开发了一种鲁棒的模型, 用于检测对齐误差并将其减小。我们选择一个帧作为 "参考图像", 并当我们确定找到了正确的相应特征时才将来自其他帧的信息合并到其中。通过这种方式,我们可以避免诸如 "重影" 或运动模糊之类的伪像, 以及图像被错误融合的部分。
一个快速移动巴士的场景。左图: 没有使用鲁棒融合模型。右图: 使用了鲁棒融合模型。
让手机摄影更上一层楼
去年的人像模式, 以及之前的 HDR+ 算法, 展示了手机摄影可以达到的优秀程度。今年, 我们在变焦方面做出了同样的工作。这是推动计算摄影学发展的又一进步, 同时缩小了手机摄影和数码单反相机之间的画质差距。这里有一份包含原始视角图像的图集, 以及采用超分辨变焦技术拍摄的图像 (https://photos.app.goo.gl/E8LZW9LRBdFV8kXD8)。请注意, 此图集中的超分辨变焦图像未被裁剪, 拍摄的时候使用捏指缩放直接在手机上进行拍摄。
左图: Pixel 2 上裁剪并进行 7x 放大的图像。右图: Pixel 3 上同样视角使用超分辨变焦技术的图像。
超分辨率的想法比智能手机的出现早了至少十年,几乎同样早的, 这种技术就通过电影和电视的虚构情节出现在公众面前。在学术期刊和会议上, 有成千上万篇论文对此进行研究,而现在, 它已经成为现实, 就在你手中的 Pixel 3 里。
-
图像
+关注
关注
2文章
1097浏览量
42485 -
马赛克
+关注
关注
0文章
14浏览量
7271 -
Pixel
+关注
关注
1文章
238浏览量
11066
原文标题:Pixel 3的超分辨变焦技术
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

NDK 视频传输马赛克问题
基于ArkUI开发框架,图片马赛克处理的实现
数字电视的马赛克业务
iPhone8支持去马赛克功能,钱包已经饥渴难耐
如何解决"马赛克"问题呢?
如何解决LED显示屏“马赛克”问题
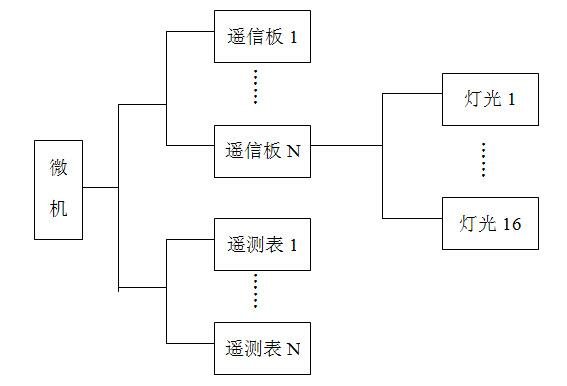
马赛克模拟屏组成单元_马赛克模拟屏的分类

iPhone13拍照有马赛克 又现新bug
教程:在ArkUI开发框架中实现马赛克处理功能

Pooling与马赛克的秘密



评论