 英特尔AI实验室推出了高性能的神经网络压缩工具Distiller
英特尔AI实验室推出了高性能的神经网络压缩工具Distiller
近日,英特尔AI 实验室推出了高性能的神经网络压缩工具Distiller,便捷地实现了更小更快更高效的神经网络计算。Distiller目前在PyTorch中实现了一系列压缩分析算法,包括稀疏引导算法和低精度近似算法。工具包主要由以下三个部分组成:
一套集成了剪枝、正则化与量化的算法;
一系列分析和评价压缩表现的工具;
以及一系列前沿压缩算法的实现样例。
更小更快更节能
目前的绝大多数神经网络都越来越深,其参数达到了百万量级。如此庞大的模型即使在硬件加速的条件下也是十分消耗资源的计算密集型算法,即使只考虑推理阶段也需要花费较多的时间。在某些低延时的场合,比如说自动驾驶和控制领域这样的处理时间就会造成很多问题。同时在消费电子上较长的延时也会造成用户体验的下降。
大型模型同时也会消耗大量的内存,以及随之而来的算力与能耗,这对于移动设备来说是十分重要的问题。同样对于大型数据中心来说模型的能耗也是不同忽视的问题。同时考虑到存储和传输的限制,神经网络的压缩具有十分重要的现实需求。在精度可以接受的条件下,压缩的越小神经网络需要的计算资源和带宽就越少。由于深度神经网络的权重矩阵具有稀疏性,通过正则化和剪枝以及量化过程可以很好的压缩模型的体量。
稀疏的神经网络模型表示可以被大幅度压缩。目前很多神经网络性能都受制于带宽,这意味着它们的计算性能主要取决于可用的带宽,带宽不足的情况下硬件需要用更多的时间将数据输入到计算单元中。全连接层、RNN和LSTM等典型的结构就受制于带宽。如果能够减小这些层所需要的带宽就能大幅提高它们的速度。
通过修剪模型中的某些权重、核甚至是整个层实现减小带宽提高速度的功能,但同时却不影响算法最终精度的表现,也减小了功耗和延时。最后考虑到读写非片上存储的能耗是片上存储的两个量级以上,如果较小的模型可以保存在片上存储中,可以使性能得到质的飞跃,让延时和能耗也随之降低。所以同时稀疏或者压缩表示时,可以有效提升算法的表现。
工具框架
Distiller目前的设计与PyTorch进行集成,其设计理念如下图所示,PyTorch的训练与Distiller进行交互。在distiller中包含了调度、算法和应用等主要模块以及汇总、日志的辅助功能,在很多常见的科学计算包的基础上利用jupyter实现交互功能,基于tensorboard实现模型和日志信息的展示。
算法
Distiller中集成了先进的剪枝和量化算法,帮助用户有效的压缩模型的体量。
剪枝算法主要分为了权重正则化、权重修剪、低精度等三种实现方式,7种具体的方法。
幅度剪枝利用阈值来将每一个权重进行二值化,小于阈值的权重将被设为0,不同的层可以设置不同的权值;
敏感度剪枝与阈值的方法类似,但使用了敏感因子s与这一层的权重分布标准差σ的乘积来作为阈值。越敏感的层(靠近输入的)设置的s就越小;
level剪枝通过设置稀疏度来实现剪枝,这种方法相较于前面方法稳定,因为目标的稀疏程度与元素的赋值不相关。
自动梯度剪枝(AGP)
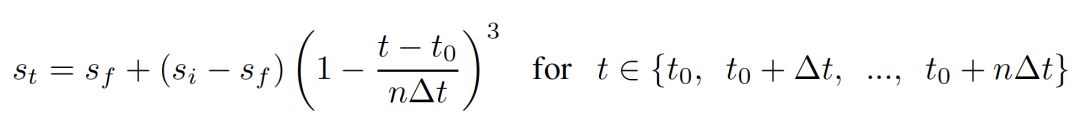
这种方法的稀疏度将会随着初始稀疏和最终稀疏自适应的变化;
RNN剪枝
结构剪枝(通过移除整个核、滤波器甚至是整个特征图来实现):包含了结构排序剪枝和对于较少激活特征图的激活相关剪枝。
量化也是一类重要的压缩算法,Distall中同时也集成了四种量化算法:
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
PACT: Parameterized Clipping Activation for Quantized Neural Networks
WRPN: Wide Reduced-Precision Networks
对称线性量化
安 装
如果想要使用这个工具的小伙伴,可以到git上下载
$ git clone https://github.com/NervanaSystems/distiller.git
$ cd distiller
然后利用你喜欢的工具创建一个python虚拟环境
$ python3 -m virtualenv env
激活环境并安装对应的依赖包:
$ source env/bin/activate
$ pip3 install -r requirements.txt
注:这一版本依赖于CUDA8.0,会自动安装PyTorch3.1
然后就可以愉快的使用了,可以通过运行下面的文件来熟悉工具的使用:
distiller/examples/classifier_compression/compress_classifier.py
#example
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
#对于cifar10压缩
$ time python3 compress_classifier.py -a alexnet --lr 0.005 -p 50 ../../../data.imagenet -j 44 --epochs 90 --pretrained --compress=../sensitivity-pruning/alexnet.schedule_sensitivity.yaml
#利用yaml配置文件来运行
另外example下还有多个例子可以尝试。
-
英特尔
+关注
关注
60文章
9874浏览量
171344 -
神经网络
+关注
关注
42文章
4759浏览量
100445
原文标题:英特尔推出全新可便捷实现「更小更快更高效的神经网络计算」的压缩工具Distiller
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Inflection AI携手英特尔推出企业级AI系统
英特尔发布至强6性能核处理器
英特尔携手运营商伙伴,共探AI驱动通信网络新未来

开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能

卷积神经网络的压缩方法
如何使用MATLAB神经网络工具箱
matlab神经网络工具箱结果分析
英特尔发布AI创作应用AI Playground,将于今夏正式上线!

英特尔推出Hala Point全球最大仿神经形态系统,解决AI效率问题
英特尔发布新一代神经拟态系统Hala Point,11.5亿神经元,12倍性能提升

借助英特尔® QAT从而显著提升网络和存储应用的性能

借助英特尔DLB技术优化网络性能
成都汇阳关于成英特尔推出多款新品,24 年或成为 AI PC 出货元年
开启AI PC新纪元!英特尔酷睿Ultra重磅发布,胜任200亿参数大语言模型






 工商网监
工商网监
评论