 在i.MX RT飞行学习板中的软件优化办法,让C代码在ARM Cortex-M7内核上极速飞奔
在i.MX RT飞行学习板中的软件优化办法,让C代码在ARM Cortex-M7内核上极速飞奔
牡丹虽好,仍需绿叶扶持;RT虽快,仍需优化。本文将分享在i.MX RT飞行学习板中的软件优化办法,让C代码在ARM Cortex-M7内核上极速飞奔!01
概述
i.MX RT飞行学习板,是真的会飞的处理器学习板!它的核心是恩智浦公司的跨界处理器i.MX RT1052, 基于ARM Cortex-M7内核,主频达600 MHz!对于电机驱动,虽然速度惊人,但是这个学习板要同时运行“4无刷电机FOC驱动 + 飞控算法”,所以依然不是轻易的事情。
牡丹虽好,仍需绿叶扶持,下面将分享多种优化手段,让C代码在i.MX RT上极速飞奔,实现这个“单芯片无人机”。先上段热身视频。
视频1 热身视频
02
加快代码速度的秘诀
1、选择硬件浮点
重要而简单的第一步是:在编译器中选择“硬件双精度浮点”,图1是在KEIL中的选择配置。
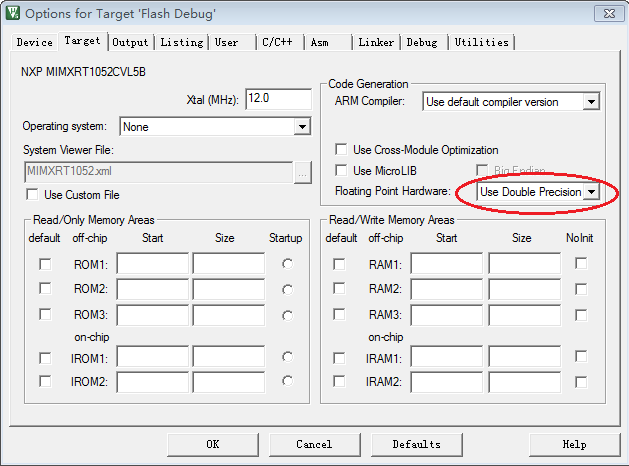
图1 双精度浮点
选择“硬件双精度浮点”的作用是,当C代码需要双精度、单精度浮点运算,编译器就选择最优的浮点指令,速度最快!如果选择“硬件单精度浮点”,单精度浮点运算就用单精度浮点指令,但双精度浮点运算只能结合多条单精度指令完成,速度较慢。如果不选择任何硬件浮点,编译器仅能用定点指令完成浮点运算,速度非常慢。
但要注意,不是任意处理器都支持“硬件浮点”,即便同样是ARM Cortex-M7内核,有些半导体厂家为了降低成本,会裁掉“双精度浮点”单元,只留下“单精度浮点”。而i.MX RT支持完整的单、双精度浮点单元。得益于这个优势,飞行学习板中的ZLG-Soar飞控软件,全部核心代码都使用双精度浮点指令,不单止精度高、而且速度超快,在相同主频下,比定点指令的Cortex-M3快20倍以上!
2、关键代码RAM中运行
将代码放在ITCM相连的RAM中运行,速度最快!
Cortex-M7的中ITCM(Instruction-Tightly Coupled Memories)是专门的指令总线。我们在i.MX RT1052中分配了256Kbytes的内部RAM在ITCM上,而且和Flash相比,内部RAM没有明显的读取延时,所以代码在这段RAM中运行,速度是最快的,没有更快!
程序清单1是飞行学习板在KEIL中的分散加载的配置,全部只读RO数据(即代码和CONST变量等)放在0x00000400地址开始的ITCM RAM里面。KEIL编译后,其实全部原始数据都是存在Flash中,但 KEIL自动在main函数前插入一段Flash函数,该函数将相关的代码从Flash复制到RAM,最后将PC指针改到RAM。这样代码就从RAM开始运行。
程序清单1 ITCM RAM分散加载
如果代码很大,无法全部复制到RAM中运行,那么可以修改分散加载,仅将必要的代码放在RAM中运行,其他代码在Flash中运行。
3、关键算法写成宏定义
在ZLG-FOC电机矢量控制库中,全部核心算法都写成宏定义的形式,如程序清单2的Clarke变换。
程序清单2 宏定义算法
如果写成C函数,那么上层代码调用时,一般先进行入栈操作、保护现场,接着跳转到该函数运行,然后调用返回指令回到上层代码,最后进行出栈操作、恢复现场。这个过程必然会延长争分夺秒的算法执行时间。
可能有的人会说:在函数前面声明inline,函数不就直接嵌入到上层代码中,省去这些啰嗦过程吗?其实不一定,编译器也是很无奈的,KEIL和IAR的编译手册都说得很明白:根据代码调用与被调用的复杂程度,能嵌进去的,编译器就帮忙嵌进去,不能嵌进去的,只能按普通函数那样处理!
但如果将算法写成宏定义,那么编译会100%保证代码会被直接嵌入到上层代码中!只是对于过长的代码,宏定义编写不方便,这时候可以将代码分拆成多个宏定义组合使用,或者仅把最必要的部分写成宏定义。
4、尽量用C,少用汇编
尽量用C,少用汇编?晚上加班眼花,写反了吧?没写错,“汇编比C快”是好多年前、奔腾电脑时代的事情!现在是人工智能、大数据的时代,KEIL和IAR 的C编译器经过几十年的发展,都变得非常聪明了(GCC笔者使用不多,不敢莽加评论)。首先,人脑能想到的最优指令,C编译器很多时候也能想到,可能比人脑想得更优!再者,用汇编写代码,即便绞尽脑汁,顶多就单个函数速度最优,仅此而已!而C编译器还会“综合统筹”,例如,前后重复的代码,它会合拼在一起;废话、没用的代码,它会删除;函数反复跳转时的出入栈过程,它会想办法减少……再配合上面提到的“算法写成宏定义”,C代码的运行速度将更快!
就如我们敬爱的周工教导说:猪脑不如人脑、人脑不如电脑,i.MX RT在极速飞奔下就是很好的体现。
5、巧妙浮点出入栈
图2显示了Cortex-M7的浮点寄存器,S0-S31是浮点的通用寄存器,其他是控制或状态等寄存器。如果软件使能了浮点单元,那么在中断发生后,M7默认会将S0-S15、FPSCR等17个浮点寄存器硬件入栈,中断完成后硬件出栈。虽然说是“硬件”,其实硬件也要花时间一个一个寄存器弄的,只不过比软件处理,省了调用指令的时间。
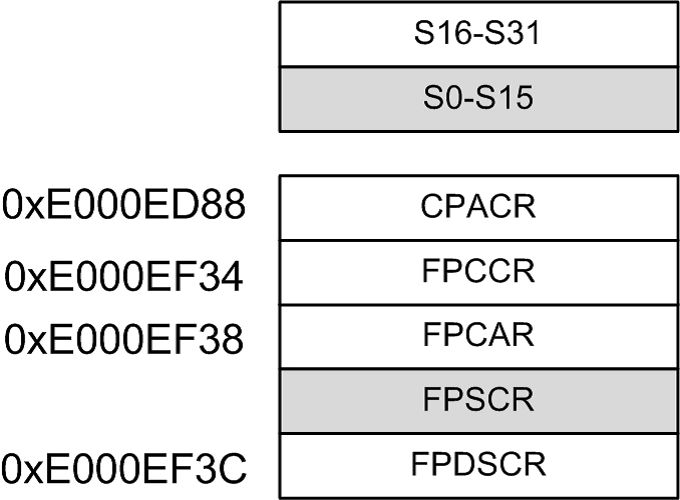
图2 Cortex-M7浮点寄存器
这里提出一个问题:假如有10个中断程序轮流产生,处理器就自动对17个浮点寄存器出入栈操作,但如果仅只有一个中断使用了浮点指令,其他9个都不使用,那么大部分浮点出入栈的操作都是浪费时间的!
如何解决这个问题呢?
ARM提出一种LAZY模式(其实一点都不懒),在中断发生后,硬件只给17个浮点寄存器预留堆栈空间,但不入栈,只有中断函数调用了第一条浮点指令前(例如浮点加、减、乘、除),硬件才补充入栈;中断完成后,如果真的发生过硬件浮点入栈,才会相应地出栈。这样大大提高了浮点出入栈的效率!这种LAZY模式够聪明吧,真不知ARM怎样起名的,可能懒的极端就是聪明吧。
6、代码清晰、聪明
图3中的两条蛇在树上互相纠缠,分不清尾巴是谁的。写代码也同样道理,如果习惯性地想到一点写一点、写前不规划、写后懒修改,就像图3左边的代码,一堆if/else,逻辑模糊、难懂、难改,运行速度没保证。而右边的代码是经过分析推理的聪明办法,用switch case替代一堆if/else,逻辑清晰、易懂、易改,运行速度有保证!
图3 清晰聪明的代码
前面介绍了很多在i.MX RT上加快代码速度的方法,但都是辅助的,最核心的还是:花点心思规划代码要怎样写,代码要清晰、聪明。
03
总结
牡丹虽好,仍需绿叶扶持,RT虽快,但仍需优化才能发挥到极致的速度,将不可能的事情变为现实!就如我们ZLG的i.MX RT飞行学习板,是业界唯一的“4无刷电机FOC +飞控算法”的无人机方案。
11月初期的广州还是茵茵绿草,我们踏青放飞去。
视频2 踏青放飞
-
处理器
+关注
关注
68文章
19275浏览量
229740 -
编译器
+关注
关注
1文章
1634浏览量
49117 -
C代码
+关注
关注
1文章
89浏览量
14300
原文标题:i.MX RT飞行学习板——如何让C代码在M7上极速飞奔?
文章出处:【微信号:Zlgmcu7890,微信公众号:周立功单片机】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
初识Layerscape和I.MX系列处理器
【大联大品佳 NXP i.MX RT1050试用体验】芯林至尊,宝刀RT1050,初识i.MX RT系列跨界处理器 (之一)
Cortex-M7 + M4内核的MCU资料大合集
Cortex-M7 + M4内核的MCU性能及特点是什么
ZLG携手NXP举行i.MX RT 跨界处理器全国巡回研讨会
高达600MHz主频的Cortex-M7 MCU

基于i.MX RT1061处理器的OK1061-S开发板介绍

支持高级语音命令和人脸识别应用的NXP i.MX RT106L和RT106F处理器
恩智浦i.MX RT1170开创GHz MCU时代
恩智浦i.MX RT1170在将该系列带上了更高的层面
恩智浦推出核跨界MCU的第二款产品i.MX RT1160
NXP推出基于i.MX RT117H的智能人机界面解决方案
基于 NXP i.MX RT1050 的 3D 打印机方案





 工商网监
工商网监
评论