 ICLR 2019共接收1591篇投稿,创下历年新高
ICLR 2019共接收1591篇投稿,创下历年新高
ICLR 2019论文评审结果已经公布,相比沸沸扬扬的NIPS评审争议,ICLR的评审结果没有出现太多争论。我们整理介绍了目前平均分≥8分,排名前6的论文,包括备受关注的最强图像生成器BigGAN等。
ICLR 2019共接收1591篇投稿,创下历年新高。
至于录取率,目前还没有官方公布。从ICLR 2018的情况来看,平均分达到6.57可以被接收,Top 33%的论文可以被接收为poster或talk。但今年的投稿量比去年多得多,去年是996篇,因此预计接收比率会降低。
Rebuttal和讨论的期间是11月5日到11月21日,这期间作者可以回复评审人的评论,并对论文进行修改。
有人做了一个网站:https://chillee.github.io,列举了得分前200的论文和它们的得分。
大部分论文处于4~6.5分之间,论文平均得分分布如下(数据来自chillee.github.io):
投稿论文涉及最多的关键词是强化学习、GAN、生成模型、优化、无监督学习、 表示学习等。
ICLR 2019关键词分布(点击图片可放大)
截至11月5日,大部分论文已经收到全部Review,部分已公布1或2个Review,其余也将在接下来几天陆续放出。
或喜或忧,评审结果争议不大
目前来看,关于ICLR评审结果的反馈没有太多争论。
有Reddit用户表示:“我不得不说,今年ICLR的评审比NIPS的要好得多。至少,到目前为止,在我关注的领域我还没有看到任何ICLR的愚蠢评论。确实,有时评审人会漏看一些论文的瑕疵。但总会有另一个评审人指出来。而且,你可以通过添加公共评论来指出你希望评审人注意到的问题。”
当然,也有人认为ICLR匿名评审有相当大“赌运气”的成分。
有Reddit用户写道:
评审人1反复说 Relativistic GAN只是对系统进行小改进(a tweak),说我的整个方法部分都是“错误的”或者“写得不好”。他的给分是3/10,置信度是2/5。其他评审人给我的论文的评价是“写得很好”,给分是6/10 和 7/10。
所以说,评审完全是一场赌博。这太令人沮丧了!
有人表示同病相怜:
我得到了类似的结果。一位评审人刚说“你的论文需要重写”,并给了一个超级低的分数3/10,他的置信度是2/5。第二位审稿人认真阅读了论文,认真写了评论,包括指出我论文的优点和缺陷,最后给的分数是8/10,他的置信度是4/5。现在我还在等待第三位评审人......这是好事还是坏事,我真的不知道该怎么想了......
也有人提出理性的建议:
我建议你们将会议视为一种“必须申请的免费推广机会”,它会对已经很好的论文有帮助,但评分多少并没有论文的实际影响那么重要。如果以后每个人都开始使用你的relativistic GAN,那么它在哪里发表实际上是无关紧要的(比如GAN、WGAN、AlphaGo,无论在哪里、发表与否,都无法否认它们是伟大的工作这一事实)。
下面,我们选取ICLR 2019目前得分排名前6(≥8.00)的论文作简要介绍。
高分论文Top 6:BigGAN、逆强化学习、后验推理等
高分论文1:Large Scale GAN Training for High Fidelity Natural Image Synthesis
得分:8.45(8,7,10)
在介绍这篇论文之前,让我们先看下面这些图片,请猜猜看,其中哪些是AI生成的假图片,哪些是真实的图片:
答案是,以上全部是GAN生成的假图片!
这些图片来自引起热议的论文“BigGAN”。GAN生成图像的论文很多,有很多也达到足以以假乱真、“效果惊艳”的水平,但BigGAN再次让学界惊叹,它直接将图像生成的指标“Inception Score”提高到166.3,比之前的最好分数提高了两倍。
虽然是匿名提交,不过作者也在arXiv上上传了这篇论文,因此我们得知它的作者:来自英国赫瑞瓦特大学的Andrew Brock,以及来自DeepMind的Jeff Donahue和Karen Simonyan。
摘要
尽管最近的研究在生成图像建模方面取得了不少进展,但从ImageNet这样的复杂数据集中成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们训练了迄今为止规模最大的生成对抗网络,并研究了这种规模的不稳定性。我们发现,对生成器应用正交正则化可以使其适用于简单的“截断技巧”(truncation trick),通过截断潜在空间,可以精确地控制样本保真度和多样性之间的权衡。我们的修改导致模型在以类别为条件的图像合成任务中达到新的最优水平。在ImageNet上以128x128分辨率进行训练时,我们的模型(BigGAN)的Inception Score (IS) 为166.3, Frechet Inception Distance (FID)为9.6,之前的最优IS为52.52,FID为18.65。
关键词:GANs, 生成模型, 大规模训练,深度学习
一句话简介:GANs受益于大规模训练
论文地址:
https://openreview.net/pdf?id=B1xsqj09Fm
高分论文2:Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow
得分:8.20(6,10,8)
摘要
对抗性学习方法已经得到广泛应用,但是对抗性模型的训练是出了名的不稳定。有效地平衡生成器和鉴别器的性能是至关重要的,因为一个鉴别器如果达到很高的精度,就会产生相对不提供信息的梯度。在这项工作中,我们提出了一种简单而通用的技术,通过信息瓶颈(information bottleneck)来约束鉴别器中的信息流。通过对观测值与鉴别器内部表示之间的相互信息进行约束,我们可以有效地调节鉴别器的准确度,并保持有用且信息丰富的梯度。
我们证明了我们提出的变分鉴别器瓶颈(VDB)导致对抗性学习算法在三个不同应用领域得到显着改进。我们的初步评估研究了VDB对动态连续控制技能(如跑步)的模拟学习的适用性。我们的研究表明,该方法可以直接从原始视频演示中学习这些技能,大大优于以前的对抗性模仿学习方法。VDB还可以与对抗性逆强化学习相结合,以学习可在新设置中转移和重新优化的奖励函数。最后,我们证明了VDB可以更有效地训练GAN生成图像,改进了之前的一些稳定方法。
关键词:强化学习,生成对抗网络,模仿学习,逆强化学习,信息瓶颈
一句话简介:通过信息瓶颈规范对抗性学习,应用于模仿学习、逆向强化学习和生成对抗网络。
论文地址:
https://openreview.net/pdf?id=HyxPx3R9tm
高分论文3:ALISTA: Analytic Weights Are As Good As Learned Weights in LISTA
得分:8.15(10,6,8)
摘要
基于展开迭代算法的深度神经网络,例如,LISTA(earned iterative shrinkage thresholding algorithm),在稀疏信号恢复方面已经取得了经验上的成功。目前,这些神经网络的权重由数据驱动的“黑盒”训练确定。在这项工作中,我们提出了分析LISTA(ALISTA),其中LISTA中的权重矩阵被计算为一个无数据优化问题的解决方案,只将步长和阈值参数留给数据驱动的学习。这显着简化了训练。具体而言,无数据优化问题是基于一致性最小化的。我们证明ALISTA保留了在(Chen et al.,2018)中证明的最佳线性收敛,并且具有与LISTA相当的性能。此外,我们将ALISTA扩展到卷积线性算子,同样以无数据的方式确定。我们还提出了一种前馈框架,结合无数据优化和端到端的ALISTA网络,可以联合训练以获得编码模型的鲁棒性。
关键词:稀疏恢复,神经网络
论文地址:
https://openreview.net/pdf?id=B1lnzn0ctQ
高分论文4:Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
得分:8.09(9,7,8)
摘要
递归神经网络(RNN)模型广泛用于处理由潜在树结构控制的序列数据。以前的工作表明,RNN模型(特别是基于长短期记忆LSTM的模型)可以学习利用底层树结构。但是,它的性能始终落后于基于树的模型。这项工作提出了一种新的归纳偏差有序神经元(inductive bias Ordered Neurons),它强制执行隐藏状态神经元之间更新频率的顺序。我们证明有序神经元可以将潜在树结构明确地整合到循环模型中。为此,我们提出了一个新的RNN单元:ON-LSTM,它在四个不同的任务上取得了良好的性能:语言建模、无监督解析、有针对性的句法评估和逻辑推理。
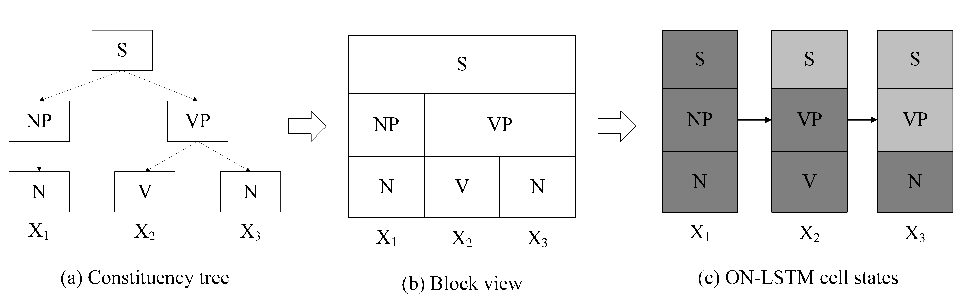
关键词:深度学习,自然语言处理,递归神经网络,语言建模
一句话简介:我们提出一种新的归纳偏差,将树结构集成在递归神经网络中。
论文地址:
https://openreview.net/pdf?id=B1l6qiR5F7
高分论文5:Slimmable Neural Networks
得分:8.08(8,9,7)
摘要
我们提出一种简单而通用的方法来训练可执行不同宽度(一个layer中的通道数)的单个神经网络,从而允许在运行时进行即时且自适应的精确度 - 效率权衡(accuracy-efficiency trade-offs)。
训练好的网络被称为slimmable神经网络,与MobileNet v1、MobileNet v2、ShuffleNet和ResNet-50等单独训练的模型相比,slimmable模型分别在不同的宽度上实现了相似(许多情况下甚至更好)的ImageNet分类精度。在许多任务中,与单个模型相比,slimmable模型有更好的性能,包括COCO边界框对象检测、实例分割和人体关键点检测,而且无需调整超参数。
最后,我们进行了可视化,并讨论了slimmable 网络的学习特性。代码和模型将会开源。
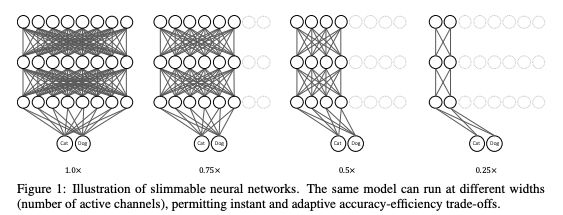
关键词:Slimmable neural networks,移动端深度学习, accuracy-efficiency权衡
一句话简介:我们提出一种简单而通用的方法来训练可执行不同宽度(层中的通道数)的单个神经网络,允许在运行时进行即时和自适应的accuracy-efficiency权衡。
论文地址:
https://openreview.net/pdf?id=H1gMCsAqY7
高分论文6:Posterior Attention Models for Sequence to Sequence Learning
得分:8.00(8,9,7)
摘要
现代神经网络架构严重依赖于将结构化输入映射到序列的注意力机制(attention)。在本文中,我们表明普遍的注意力架构不能充分建模注意力和输出变量之间沿预测序列长度的依赖性。
我们提出一种新的替代架构,称为后验注意力模型(Posterior Attention Models)。它基于注意力和输出变量的完全联合分布的原则分解,提出了两个主要的变化:
首先,注意力被边缘化的位置从输入变成了输出。其次,传播到下一个解码阶段的注意力是一个以输出为条件的后验注意力分布。
在5个翻译任务和2个形态学变换任务中,后验注意力模型比现有的注意力模型产生了更好的预测准确性和对齐精度。

关键词:后验推理,attention,seq2seq learning,翻译
一句话简介:基于后验分布的计算注意力机制可以得到更有意义的attention和更好的表现
-
神经网络
+关注
关注
42文章
4789浏览量
101612 -
GaN
+关注
关注
19文章
2085浏览量
75068 -
强化学习
+关注
关注
4文章
269浏览量
11369
原文标题:ICLR 2019评审结果出炉!一文看全平均8分论文
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
后摩智能5篇论文入选国际顶会






 工商网监
工商网监
评论