 Hashtable的内部结构是怎么样的如何重新发明哈希表Hashtable
Hashtable的内部结构是怎么样的如何重新发明哈希表Hashtable

哈希表Hashtable是计算机中最常见也最基本的数据结构之一,但是有的CS基础不扎实的学习者,其实还是对这个结构一知半解,时时感到困惑。对于这部分朋友,不妨尝试一种全新的方式——从创造者的角度,自己把这个结构重新发明一遍。这个想法听来奇怪,这不是更难了吗?其实不然,重在节奏。只要把思路梳理清楚,把问题一步步分解,你会看见一条自然清晰的道路。
从发明的角度,我们只要问两点:
(1) 我们想解决一个什么问题?
(2) 这个问题如何最好地解决?
1
动机:无处不在的查询
在程序当中,经常碰到需要“查表”的时候,就是用某种形式的标识(key),去查询标识对应的相关信息(value):
存一个用户名到用户信息的lookup table,时时备查
统计一段文字的单词频率: 那你就得建立一个从每个单词到出现次数的对应关系,扫描文字的时候看到哪个词就把它的频次+1
一个运算上成本很高的函数f(n),想让已经算过的结果不再产生重复劳动,那就需要一个表,存储所有算过的n,和它们所对应的计算结果。
这样的“关键字查询”需求在程序设计的过程中无处不在,所以我们需要一个高效的机制,来存储key和value的对应关系。
2
问题
任务:设计一个高效率的从key查询对应value的方法。
原料:由于hashtable过于基本,每个语言都会有自带的结构提供这个功能,不过既然我们在重新设计,只能当这些语言自带的的hashtable不存在。你的原料是最基本的,数组 array。
3
笨办法
先来个最最基本的解法,一来帮助理解待解决的问题,二来可以对照出最终hashtable的优点。
比如一种笨办法就是把要存储的 (key, value) 一对对直接堆放在数组里
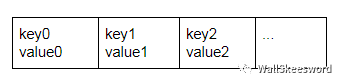
每次查询一个key的时候就从头到尾扫描数组,找到key就停,都找遍了就知道没有这个key。这个做法至少满足了正确性,但是比较慢;因为线性扫描整个数组,里面key的总量一多时间成本就很高。
4
最简问题:数组即查询
回到我们的设计问题上。不过你想想,数组也算是实现了某种查询——key都是0..N-1的查询——输入下标 i,数组 a[i] 告诉你这个下标对应的值。
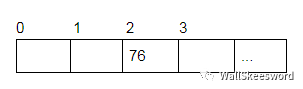
而这也很符合我们的效率需求:查询和修改都非常快。当然,这是因为数组就是连续内存,下标就是内存取址,所以 0..N-1 相比于别的 key 来说,查询尤为简单直接。
那么接下来,我们要问的就是,如何让任意一种形式的key都可以享有和特殊的 0..N-1 下标查询几乎一样的效率呢?一种思路是,只要想办法高效地把key转化为0..N-1的下标就可以了。
5
下标转化: key=’a’..’z’
举例/进阶题:比如说我们要做一个简单的文字加密,我们事先规定加密关系 a -> x, b -> o, c -> p, …,把这个关系写进一个lookup table里面,以后加密的时候,就一个字母一个字母地读原文,查出密文,这个字母就转化好了。比如单词 “cab” 就会变成 “pxo”。
分析:’a’..’z’ 虽然不是整数 0..N-1 吧,但是也差不多…
一种方案:当然是把 ’a’..’z’ 依次序对应到 0..25 咯
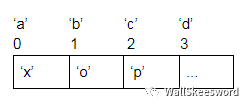
查询任何小写字母 ch 的时候,先计算出下标 i = ch - ‘a’,就可以访问 a[i],在数组中查出这个明文字母该对应的密文了。
6
通用转化:hash function
接着上面这个字母的例子,我们可以笼统地想了,刚才那个’a’..’z’对应到0..N-1的过程,如果能对任何key做就好了。而这个对应机制,就叫做哈希函数 hash function:如果对于某种 key 类型(比如字符串)我们可以提供一个哈希函数hash,把 key 带进去就能输出一个整数 hash(key),那我们可以以它为原料产生数组下标。
通常我们会让 hash(key) 大一些,当然实际上数组空间只有N,所以取个余数,以 hash(key) % N 为最终数组下标。比如 hash(key0) % N = 3, 那存成
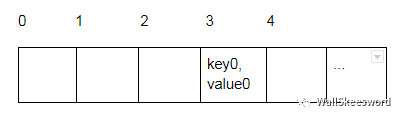
当然这只是理想的情况。如果我们观察 ’a’..’z’ → 0..25 这个对应,就会发现它有一个特殊性,就是“一个萝卜一个坑”:字母和下标一一对应。但是,在一个更加一般的情形下,在 hash 函数和取余数的双重操作下,有时候难免会出现“很多萝卜都想去同一个坑”的状况。怎么解决呢?人们通常想到两种办法:
“把坑挖深”:如果几个key都对应相同的数组下标,那把这几个萝卜都堆放在这个坑里面。具体来说每个数组下标下面挂的不是一对 (key, value),而是一整个列表放着若干个 (key, value) ——这个列表其实就是类似我们最先提出的那个“笨办法”。先用 key 和哈希函数找到坑,之后在坑内查询就退化成我们的“笨办法”了。
“先来后到,后到的萝卜找别的坑占去”:每个坑还是只容纳一个萝卜;如果一个萝卜发现自己该去的坑已经被占了,可以定义一套规则,帮助它找下个坑,一次次直到找到一个空的坑为止。
7
回顾与想象
以上,我们终于完成了hashtable大体框架的设计。想清楚了这些内部原理,我们可以开始对它的运行开始有一些想象,也作为一种回顾。
首先,查询的基本流程如下图所示,输入key,通过hash function算出数组下标,然后在这个数组下标对应的坑里面依次寻找这个具体的key。
在理想的情况下,hash函数可以成功地把 key 均匀地打散到数组下标中,并且数组空间也比较充裕,从而 key 的下标冲突不多,添加、修改、查询元素,都可以通过哈希函数来快速定位,O(1)时间;偶尔碰见一些下标冲突,但是频率低、多找两步还是能找到所需元素,那么总体平均下来还是大致认为是常数时间。
反之,如果hash函数设计得不好,导致下标冲突很多,极限情况下可能所有萝卜都掉进一个坑里,那弄了半天你可能还是退化成了我们最早提出的“笨办法”。或者数组空间不足,里面存的 (key, value) 特别多,那可能也会不得不发生很多下标冲突,非常臃肿,达不到设想的效率。
-
计算机
+关注
关注
19文章
7837浏览量
93447 -
程序
+关注
关注
117文章
3847浏览量
85454 -
数据结构
+关注
关注
3文章
573浏览量
41674
原文标题:重新发明哈希表 Hashtable
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
序列化哈希表到文件
美国普渡大学和哈佛大学的研究人员推出了一项新发明 新...
新发明的另类调光方式来了——发明实验于”精彩的开关电源猎趣“之后
令人难以置信!BodyCom新发明可让人体触摸解锁
Linux内核中的hash与bucket



评论