 一种基于智慧运营平台,将大数据技术和数据挖掘技术相结合
一种基于智慧运营平台,将大数据技术和数据挖掘技术相结合

【摘要】 为减少用户流失,提高用户保有率,文章介绍一种基于智慧运营平台,将大数据技术和数据挖掘技术相结合,对电信客户流失进行预测的模型。该模型利用大数据技术处理用户离网前的海量数据信息,分析流失用户特征,建立用户流失预测,提前锁定流失风险较高的用户,有针对性地制定维挽策略,精准开展维系挽留活动,能够有效降低用户离网率。
引言
随着移动通信成本逐步下降,移动用户渗透率超过100%,新增市场趋于饱和,面对新增市场的激烈竞争,存量用户的保有显得越来越重要。一项调查数据表明,争取1位新客户的成本是保住1位老客户的5倍。面对新的竞争形势,运营商需要从传统只重视增量发展模式向“增存并重”发展模式转变。如何最大限度地降低客户的流失并挽留客户,成为决策者关注的话题。
客户流失给运营商带来了巨大损失,成功挽留一个即将流失的客户比重新发展一个客户节约大量成本。减少客户流失的关键是提前预测潜在的流失客户,采取相关措施提高客户的满意度,实现该预测的关键是数据挖 掘[1]和大数据技术。基于大数据技术的数据挖掘就是从海量的客户资料、使用行为、消费行为、上网轨迹等信息中提取有用的信息进行组合关联,准确判断客户流失的现状或倾向,可以让企业及时并有针对性的对客户进行挽留[2];因此,利用大数据技术进行数据挖掘,预测客户流失、减少客户流失的发生成为电信行业研究的重点。
1国内外研究现状
在数据挖掘方面,国外有很多案例和做法值得学习,比如:文献[3]中运用决策树、Logistic回归、 人工神经网络等算法建立了移动用户流失预测模型。 Lightbridge[4]公司运用CART算法分析了新英格兰的一 家移动服务商的数据并建立了客户流失模型AT&T 公司很早就开始在大数据上的探索[5],2009年开始与 Teradata公司合作引进天睿公司的大数据解决方案。
在过去的几十年中,中国企业都扮演着技术跟随者的角色,现阶段我国互联网企业在数据挖掘、大数据处理以及人工智能、云计算等领域都有了巨大的发展。 比如文献[6]中使用K-means聚类算法对电信客户进行细分,在此基础上探索了客户细分在营销中的实际应用。 文献[7]中利用神经网络算法建立用户流失预测模型,分析用户流失特征。文献[8]中利用Spark平台实现了多种神经网络算法,对用户流失问题提出了快速精确的模型。国内的电信企业虽然都建立了客户流失预测、客户 分群等模型,但大多都是基于数据挖掘软件如SPSS、SAS等应用,使用的数据量有限,不能全面分析用户流失行为。
2大数据平台及技术
安徽联通构建基于B域、O域和M域数据融合的大数据平台——智慧运营平台,实现数字化转型及全业务流程的智慧运营。智慧运营平台通过企业级大数据平台 实现企业全量数据的接入及治理,当前包括Hadoop、 Universe、实时流处理三大资源池,共计140多个节 点,存储容量3PB、2200核CPU、8T内存计算资源,实现资源动态管理;流处理平台具备百万级别消息并发 处理能力,支持1分钟级别提供用户位置能力(见图1)。
智慧运营平台接入BSS、CBSS、OSS、SEQ、上 网等全网多种数据源,利用BDI(Big Data Integration, 数据集成套件)和Flume进行离线数据及日志数据的抽取、转换、加载等数据采集功能,实现高性能海量数 据处理和存储。利用Hadoop、Universe、实时流处理三大资源池,有效支撑上层各种应用的开发和运行。利用基于大数据分析平台构建的新一代智能数据挖掘系统 SmartMiner进行自动化数据挖掘,实现各种算法模型的训练和预测。借助智慧运营平台强大的大数据分析和处理能力,结合现网客户运营的经验,建立有效的用户流失预测模型,实现用户的流失预警、维系策略匹配、客户反馈优化等一整套流程,能够有效降低用户流失。
3离网预测模型构建
3.1离网预测原理
离网预测模型[9]主要是根据历史数据特征,通过数据挖掘算法,建立预测模型,并将模型应用于现网用户,预测出离网概率高的用户。其主要包括数据准备、 模型训练和验证、离网预测三大部分[10]。如图2所示,数据准备阶段,根据出账和充值规律定义离网规则,通过对电信业务和用户行为的理解,从运营商各域数据里提取数据,并筛选离网预测特征字段,构建离网预测特征库。模型训练和验证阶段,选取数据挖掘算法,进行模型训练、评估和调优,训练出最佳模型。离网预测阶段,将训练的最佳模型应用于现网数据,实现准确的流失预测。进一步通过有效的维系手段,对预测流失用户进行精准维系,减少用户离网,提升在网用户价值。
3.2随机森林算法
传统数据挖掘中进行流失预测多采用决策树算法[11],它的特点有训练时间复杂度低、预测的过程比较快、模型容易展示等。但是单决策树容易过拟合,虽然可以通过剪 枝等方法减少这种情况的发生,但仍有不足。2001年Leo Breiman在决策树的基础上提出了随机森林算法[12]。
随机森林是由多个决策树构成的森林,算法分类结果由这些决策树投票得到,决策树在生成过程中分别在行方向和列方向上添加随机过程,行方向上构建决策树 时采用有放回抽样(bootstrapping)得到训练数据,列方向上采用无放回随机抽样得到特征子集,并据此得到其 最优切分点。从图3中可以看到,通过K次训练,得到K棵不同的决策树{T1,T2,…,TK},再将这些树组合成一个分类模型系统,随机森林是一个组合模型,内部仍然是基于决策树,同单一的决策树分类不同的是,随机森林通过多个决策树投票结果进行分类,算法不容易出现过度拟合问题。
3.3 数据准备
3.3.1 离网定义及数据需求
为了进一步提前锁定离网倾向用户,经过历史数据的比对,结合用户使用行为的分析,决定将过缴费期10天未缴费的用户定义为流失用户。根据传统数据挖掘实现的离网预测案例的经验,考虑到大数据系统的处理能力,通过对连续3个月内离网的用户进行离网打标,增加离网用户的样本量,提高离网预测的准确率;通过对目标用户中隔月后离网的用户进行打标,预留1个月的 预测结果干预期,进行维系挽留。如图4所示,采用连续7个月的历史数据,对第N-6月的数据进行隔月后的连 续3个月(N-4月、N-3月、N-2月)离网用户打标,取N-6 月、N-5月、N-4月连续3个月的正负样本并集,解决了传统打标负样本量不足和维系干预期太短等问题。
3.3.2数据特征提取
根据业务经验,选取与用户流失可能存在相关性的所有属性,进行数据审查,筛选存在相关性较大的特 征属性。本次建模数据特征主要采用B域用户通信及消 费行为等基本属性、衍生属性(汇总、比例、趋势和波动)、挖掘属性等,增加O域样本数据,如上网行为、 终端属性指标(换机、应用偏好、掉话率、上网协议响 应成功率等)。如表1所示,数据维度包括基础信息维度、通信行为信息、账务信息、消费行为变化维度、交往圈信息、呼叫异网维度、投诉维度、通信行为维度及上网轨迹、掉话率等。根据这些维度数据合并汇总成数据挖掘特征宽表,用于模型训练和验证。

3.4建立模型
流失客户预测模型的建立,具体包括原始数据处理、特征宽表构建、模型训练、模型评估和模型调优五个部分。如图5所示,智慧运营平台通过连接全网数 据的接口,获取建模所需的BSS系统(业务支持系统)数 据和OSS系统(运营支持系统)数据。BSS系统是运营商 向用户开展业务的主要IT组成部分,OSS系统是电信服务提供商用来管理通信网络的主要系统。BSS数据包括 CRM(客户关系)、Billing(账单数据)、详单数据及投诉数据,OSS数据包括分组交换数据(Package Switch, PS)、测量报告数据(Measurement Report,MR)和电路交换数据(Circuit Switch,CS)。其中PS数据描述了用户连接网络的情况,如上网速度、掉线率和移动搜索文本 信息;MR数据可以用来给用户定位,获取用户运动轨迹;CS数据描述的是用户的通话质量,如掉话率等。
我们将获取的原始数据存储到Hadoop分布式文 件系统中(HDFS),然后再利用Hive进行特征生成和处理工作。HDFS可以处理PB级别的超大文件,Hive可 以提供简单的SQL查询功能,并能将SQL语句转化为 MapReduce任务分布式运行。
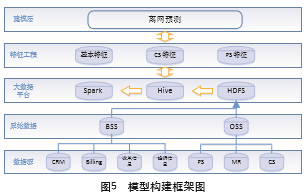
特征宽表生成后,我们利用Spark的高效计算能 力,在SmartMiner中选取随机森林算法进行流失预测模型的训练,经过训练结果的多次验证和评估,我们将 随机森林设置为200颗树,SQR采样方法,树的最大深 度为15层,叶子最小样本数100个,最大分箱数32,进行模型建立。将分类器训练出来的模型应用到现网数据,可以预测未来3个月有离网倾向的用户,按照离网倾向的高低排名,锁定维系挽留的目标客户。
3.5模型评估
训练模型的好坏可以通过对历史流失数据的检验来验证,模型评估参数一般包括准确率和覆盖率,准确率越高、覆盖率越大,模型效果越好,其中:准确率=预测流失准确的客户数 / 预测为流失的客户数;覆盖率=预测流失准确的客户数 / 实际流失的客户数。
如图6所示,我们根据建模训练数据的规则,可以在第N月预测第N+2月、N+3月、N+4月的流失用户, 第N+1月为我们的维系窗口期。
我们选取2016年1~6月数据进行训练,对7~10月数据进行模型预测,如图7所示,经过2016年9月至 2017年2月数据的验证,可以得到7~10月的预测数据 TOP50000中查准率基本在80%,查全率40%。
4离网根因分析
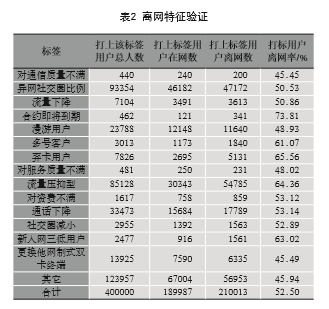
通过对离网用户的特征属性进行聚类分析,离网用户大致原因可以分为:资费原因、合约感知原因、社会交往影响原因、终端换机原因、地域变更原因、服务质量原因、通信质量原因、弃卡原因、新入网质量原因及其他原因等。如表2所示,提取2016年11月数据预测2017年1~3月离网概率top400000用户,对其离网情况进行验证,其准确率达到52%以上。
5应用
5.1策略匹配
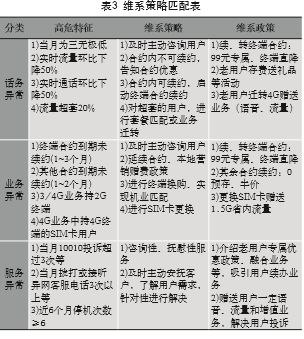
通过对流失用户的根因分析,结合现有维系业务,将预测的离网用户,根据业务特征进行分类,匹配相应策略指导市分VIP维系客户经理进行外呼维系。如表3所示,将离网倾向较高的用户分为话务异常、业务异常和服务异常三类,针对话务异常用户,重点进行优惠活动介绍,增加用户黏性;对于业务异常用户,推荐合约 续约及更换SIM卡;对于服务异常用户,进行及时安抚并给予一定赠送。
5.2维系效果
针对三星级以上用户,我们利用在网维系系统进行了针对性的维系挽留。从2017年1月开始,我们将大数据系统预测出的离网倾向较高的高价值用户通过在网维系系统下发到市分VIP客户经理处,根据匹配的策略进行精准维系。如图8所示,2015年9月至12月,高价值 用户准离网率平均值为2.04%,全网准离网率为3.6%。 模型应用后,高价值离网率从2017年2月开始持续降低,如图9所示,截至2017年7月下降到1.35%,平均准离网率为1.49%,相比应用前的2.04%下降了0.55%, 每月多挽留客户8230户,高价值户均ARPU按90元计算,月均减少损失74万元,年减少损失888万元。
6总结
本文阐述了利用智慧运营大数据平台,对流失客户的特征进行的分析和研究,利用SmartMiner分析系统选取随机森林算法,建立客户流失预测模型,通过多次的训练和优化,逐步提高流失预测模型的准确性。通过对离网用户的根因分析,制定相应维系策略,匹配到相应的离网倾向用户,在全网进行了系统化的精准维系,有效提升了用户保有率。下一步将结合维系效果,继续优化模型参数,完善训练模型,进一步提升流失预测的准确率和覆盖率,继续研究用户流失根因,根据离网根因匹配维系策略,进一步降低用户流失,增强用户黏性,提升客户价值。
-
数字化
+关注
关注
8文章
10951浏览量
67502 -
数据挖掘
+关注
关注
1文章
406浏览量
25146 -
大数据
+关注
关注
64文章
9113浏览量
144170
原文标题:【集客经营】基于大数据技术的电信客户流失预测模型 研究及应用
文章出处:【微信号:xiacoinfo,微信公众号:资治通信】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录




评论