 网络架构对ResNet训练时间有什么影响
网络架构对ResNet训练时间有什么影响
目前为止,我们使用的都是固定网络架构,即在CIFAR10上用单个GPU最快的DAWNBench记录,经过简单改变,我们将网络达到94%精度的时间从341秒缩短至154秒。今天,我们要研究其他的替代性架构。
让我们先回顾下目前所用的网络:
粉色的残差块包含了一个identity shortcut并保留了输入的空间和通道维度:
浅绿色的下采样模块将空间分辨率降低两倍,输出通道的数量增加一倍:
加入残差模块的原因是通过在网络中创建shortcut让优化变得更简单。我们希望较短的路径代表相对容易训练的浅层子网络,而较长的路径可以增加网络的能力和计算深度。这样一来,研究最短路径如何通过网络孤立训练,并且如何采取措施进行改进似乎是合理的。
清除长分支会生成一下主要网络,其中除了第一个网络,所有的卷积网络的步长都为2:
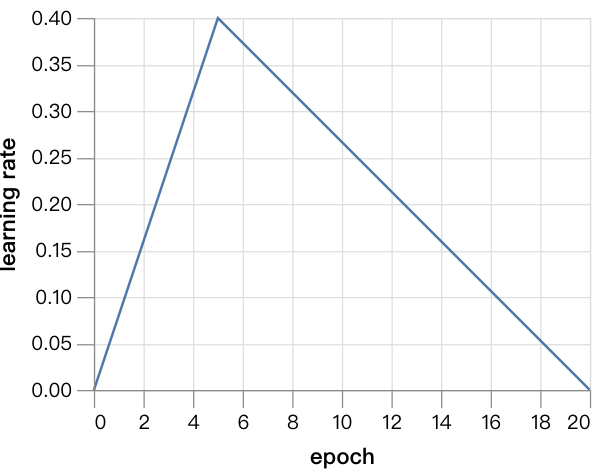
在接下来的实验中,我们会训练20个epoch,利用比之前学习速率更快速的版本训练,因为网络较小,收敛得更快。复现这一结果的代码在此:github.com/davidcpage/cifar10-fast/blob/master/experiments.ipynb
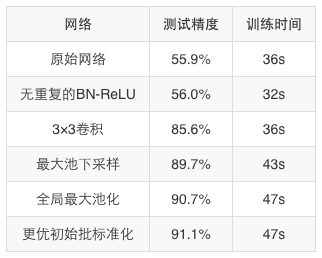
对最短的路径网络训练20个epoch,在36秒内的测试精度仅达到55.9%。删除掉重复的批标准化ReLU群组,将训练时间缩短到32秒,但是测试精度仍然不变。
这一网络有个严重的缺陷,即下采样卷积有1×1的核以及为2的步长,所以与其扩大接受域,它们反而会抛弃信息。如果我们用3×3的卷积替换,测试精度在36秒的训练后达到了85.6%。
我们还能继续对下采样进行优化,使用3×3、步长为1的卷积,并且后面跟一个池化层。我们选择最大池化和2×2的窗口大小,43秒训练后的测试精度为89.7%。用平均池化法得到相似的结果,但时间稍长。
分类器前的最后一个池化层是全局平均池化层和最大池化层的连接,从原始网络中得来。我们用更标准的全局最大池化层替换它,并且将最终的卷积层的输出维度变为原来的两倍,对输入维度进行补偿,最终在47秒内,测试精度达到了90.7%。注意,这一阶段的平均池化层并不如最大池化层。
默认情况下,在PyTorch0.4中,初始批规范化的范围在0到1之间随机选择。初始接近0的通道可能被浪费,所以我们用常数1来替代。这导致通过网络中的信号更大。为了补偿,我们提出了一种整体恒定惩罚对分类器进行重新调整。对这一额外超参数,大致的手动优化值是0.125。经过这些改变,经过20个epoch的训练,网络在47秒内达到了91.1%的测试精度。
下表总结了我们上文中提到的各种改进步骤:
现在的网络看起来没什么问题了,接下来我们要进行收益递减,添加一些图层。目前网络仅有5个图层(四个卷积,一个全连接层),所以还不确定我们是否需要残差分支,或者添加额外的层后能否得到94%的目标精确度。
如果只增加宽度似乎不可行。如果我们让通道维度增加一倍,训练60个epoch后,可以达到93.5%的精确度,但是会用321秒。
在增加网络深度方面,我们还面临着多种问题,例如不同的残差分支类型、深度和宽度以及新的超参数,例如初始范围和残差分支的偏见。为了让结果更进一步,我们要严格限制搜索空间,所以,不能调整任何新的超参数。
特别的是,我们要考虑两种类型的网络。第一种是选择性地在每个最大池化层后添加一个卷积层。第二种是添加一个含有两部分3×3卷积的残差块,其中有identity shortcut,也是在最大池化层之后添加。
我们在最后卷积模块后、全局最大池化层之前插入了一个2×2的最大池化层。是否添加新层要根据不同情况决定,我们还考虑混合两种类型,但这并没有提升性能,所以我们就不在此展开了。
下图是第一种网络示例,其中我们在第二个最大池化层之后添加了额外的卷积:
下图是第二种网络示例,其中我们在第一和第三层之后添加了残差分支:
现在要开始“暴力”架构搜索了!我们训练了15种网络(经过改进的原始网络和上述两类网络中每类的7种变体),各训练20个epoch,另外还对比了训练22个epoch的结果,了解训练时间增长和更深的网络架构之间的差别。如果每个实验仅运行一次,就会花费30分钟的计算时间。但不幸的是,每次最终测试精度的标准偏差约为0.15%。所以为了得出准确的结果,我们会对每个实验运行10次,将每个数据点的标准偏差控制在0.05%左右。即便如此,不同架构之间从20到22个epoch运行后改进率之间的差异主要可能是噪音。
以下是结果,点表示20个epoch和精确度,线条的延伸表示22个epoch的结果:
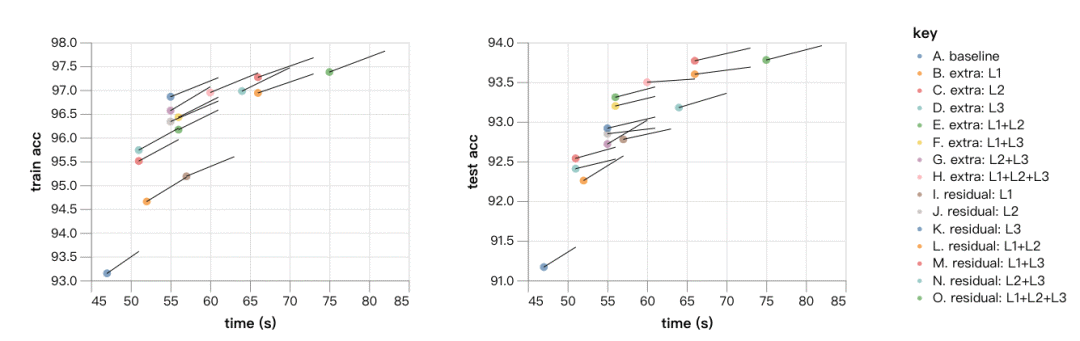
与运用更深层的架构所得到的进步相比,训练更长时间所得到的进步速度似乎很慢。在测试的框架中,最有前景的或许是Residual:L1+L3。网络在66秒内达到了93.8%的精确度,如果我们将训练扩展到24个epoch,平均精确度为94.08%,训练时间为79秒。
目前为止,我们已经得到了一个9层的深度残差网络,能在79秒内达到94%的训练精确度,几乎将训练时间缩短了一半。最后还有一个问题:我们是否真的需要残差分支才能让测试精确度达到94%?答案显然是否定的。例如,单一的分支网络Extra:L1+L2+L3能在180秒、60个epoch内达到95%的精确度,加上正则化或更宽的版本后,精确度会更高。但是至少在现在最快的是一个残差网络。
结语
本文结束前,让我们再简单回顾一下研究的目的。很多观点认为,训练模型在CIAFR10上达到94%的测试精确度是无意义的行为,应为现在最高的精确度都达到98%了(另外还有人认为现在ImageNet才是“唯一”的数据集,其他实验只是浪费时间罢了)。
事实上,我们可以通过9层网络在24个epoch内达到94%的精确度,这也再次说明我们的目标门槛过低。另一方面,人类在CIFAR10上的表现也在94%左右,所以这一情况并不清楚。
在某种程度上,现在的精确度是一种“病态”的目标,只追求更大的模型、调整更多超参数、更多数据增强或者更长的训练时间,让各种工作之间的比较更难。另外,在训练或结构设计上的创新会带来额外的超参数维度,并且调整这些参数可能会导致有关训练更好的隐式优化,否则这些与研究中的扩展无关。如果基础模型的外显超参数的维度空间较低,那么通常被认为是最佳的对比试验无法解决该问题。这种情况的结果是,最先进的模型难以进行比较、复现、重建。
有了这些问题,我们认为任何能轻易在各项实验中进行比较的都是有益的。我们相信创建有竞争力的基准也是应对挑战的一种方法。资源的限制让各实验之间的比较更公平,减少了为了培训所需要做的调整。模型多余的复杂性可能会受到资源限制基线的惩罚,哪些明确控制相关参数的方法通常会获胜。
最近,根据模型推理时间或模型大小公布曲线越来越多。这对于优化和解决上面的问题来说都是积极的方法,但我们相信训练时间所带来的额外正则化会有更多好处。另一方面,优化训练时间并不考虑推理成本是否是次优的,这也是为什么我们的训练时间结构总是包含测量每个epoch中测试集的时间,并且我们避免了类似测试时间增强等技术,它可以在推理时减少训练时间。
-
gpu
+关注
关注
28文章
4799浏览量
129528 -
网络架构
+关注
关注
1文章
95浏览量
12658
原文标题:如何训练你的ResNet(四):网络架构对训练时间的影响
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习与图神经网络学习分享:CNN经典网络之-ResNet
一文读懂物体分类AI算法:LeNet-5 AlexNet VGG Inception ResNet MobileNet
如何进行高效的时序图神经网络的训练
YOLOv6中的用Channel-wise Distillation进行的量化感知训练
形象的理解深度网络架构
索尼发布新的方法,在ImageNet数据集上224秒内成功训练了ResNet-50
百度大脑EdgeBoard计算卡基于Resnet50/Mobile-SSD模型的性能评测
首个关于深度神经网络训练相关的理论证明
基于改进U-Net网络建立HU-ResNet模型

深度解析MLPerf竞赛Resnet50训练单机最佳性能
PyTorch教程8.6之残差网络(ResNet)和ResNeXt






 工商网监
工商网监
评论