 文本数据量不够大的时候可用的一些实用方法,从而赋予小数据集以价值
文本数据量不够大的时候可用的一些实用方法,从而赋予小数据集以价值

数据不够大,就不能玩深度学习?长期存在的一大挑战就是:只有极少数情况下有足够的数据进行深度学习。本文作者提出了一些比较实用的方法,从简单的经典机器学习建模方法开始着手解决这个问题,以应对文本数据量不够大的情况。
深度学习往往需要大量数据,不然就会出现过度拟合,本文作者提出了一些在文本数据量不够大的时候可用的一些实用方法,从而赋予小数据集以价值。
作为数据科学家,为你的问题选择正确的建模方法和算法应该是你最重要的技能之一。
几个月前,我致力于解决一个文本分类问题,关键在于判断哪些新闻文章与我的客户相关。
我只有一个几千条带标注的新闻数据集,所以我从简单的经典机器学习建模方法开始着手解决这个问题,例如用TF-IDF来做Logistic回归分类。
一般说来,这些模型适用于长文档(如新闻、博客文章等)的文本分类,然而在我这个任务上的执行效果却不尽如人意,仅仅略好于随机分类。
在研究了一番模型错在哪里之后,我发现词袋模型(bag of words)这种表示方法对于这个任务是不够的,我需要一个能深入理解文档语义的模型。
深度学习模型在需要深入理解文本语义的复杂任务上已经表现出了非常好的效果,例如机器翻译,自动问答,文本摘要,自然语言推理等。
这看起来对我的任务而言是一个很完美的方法,但是为了训练深度学习模型通常需要数十万甚至数百万个被标记的数据,而我只有一个很小的数据集。怎么办呢?
通常,我们需要大量数据来训练深度学习模型目的在于避免过拟合。深度神经网络具有非常非常多的参数,因此如果没有用足够的数据去训练它们,它们往往会记住整个训练集,这就会导致训练的效果很好,但在测试集上的效果就很差了。
为了避免因缺乏大量数据而导致的这种情况,我们需要使用一些特殊的技巧!一击必杀的技巧!
在这篇文章中,我将展示一些由我自己开发或是我在文章、博客、论坛、Kaggle和其他一些地方发现的方法,看看它们是如何在没有大数据的情况下让深度学习更好地完成我的任务的。其中许多方法都基于计算机视觉中广泛使用的最佳实践。
一个小小的免责声明:我并不是一个深度学习方面的专家,这个项目也只是最初几个我用深度学习完成的大项目之一。这篇文章的所有内容都是对我个人经验的总结,有可能我的方法并不适用你的问题。
正则化
正则化方法以不同的形式呈现在机器学习模型中,它可以被用来避免过拟合。这些方法的理论性很强,对于大多数问题来说是一种普遍通用的方式。
L1和L2正则化
这些方法可能是最古老的,并且在许多机器学习模型中已经使用多年。
使用这种方法时,我们将权重的大小添加到我们试图最小化的模型损失函数中。这样,模型将尽量使权重变小,同时那些对模型影响不明显的权重值将被减小到零。
通过这种方式,我们可以使用更少数量的权重来记住训练集。
更多细节:
https://towardsdatascience.com/only-numpy-implementing-different-combination-of-l1-norm-l2-norm-l1-regularization-and-14b01a9773b
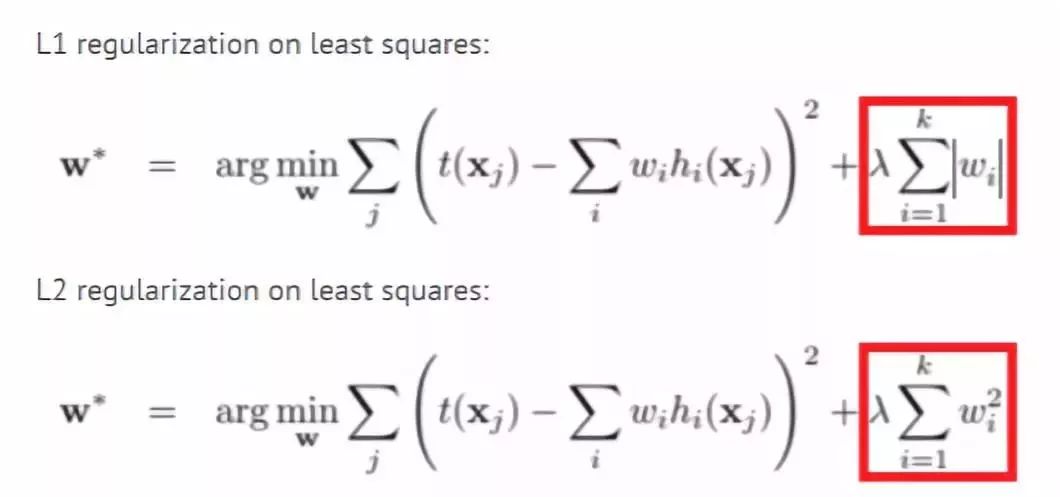
Dropout
Dropout是另一种较新的正则化方法。它具体的做法是在训练期间,神经网络中的每个节点(神经元)按照P的概率被丢弃(即权重被设置为零)。这样,网络就不会依赖于特定的神经元和他们之间的相互作用,而必须在不同的部分学习每一种模式。这就使得模型专注于学习那些更易于适用到新数据的重要模式。
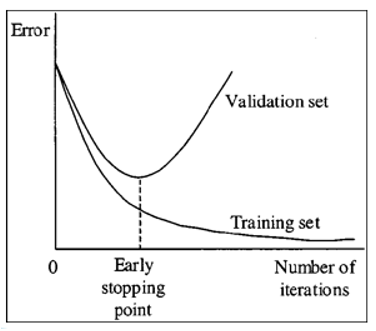
Early stopping
Early stopping是一种简单的正则化方法,只需监控验证集性能,如果你发现验证集性能不再提高,就停止训练。这种方法在没有大数据的情况下非常重要,因为模型在5-10次甚至更少次数的迭代之后,通常就开始出现过拟合了。
减少参数的数量
如果你没有大型数据集,那你就应该谨慎设计网络中的层数和每层的神经元数量。 此外,向卷积层这样的特殊层比全连接层具有更少的参数,所以如果可能的话,使用它们会非常有用。
数据增强
数据增强是一种通过更改训练数据而不改变数据标签的方式来创建更多训练数据的方法。 在计算机视觉中,许多图像变换的方法被用于数据集大小进行扩增,例如翻转、裁剪、缩放、旋转等。
这些变换对于图像类型的数据很有用,但不适用于文本,譬如翻转出像“狗爱我”这样无意义的句子,用它来训练模型的话将不会有什么效果。以下是一些针对文本的数据的增强方法:
同义词替换
在这种方法中,我们随机的选一些词并用它们的同义词来替换这些词,例如,我们将句子“我非常喜欢这部电影”改为“我非常喜欢这个影片”,这样句子仍具有相同的含义,很有可能具有相同的标签。但这种方法对我的任务来说没什么用,因为同义词具有非常相似的词向量,因此模型会将这两个句子当作相同的句子,而在实际上并没有对数据集进行扩充。
回译
在这个方法中,我们用机器翻译把一段英语翻译成另一种语言,然后再翻译回英语。这个方法已经成功的被用在Kaggle恶意评论分类竞赛中。
例如,如果我们把“I like this movie very much”翻译成俄语,就会得到“Мне очень нравится этот фильм”,当我们再译回英语就会得到“I really like this movie”。回译的方法不仅有类似同义词替换的能力,它还具有在保持原意的前提下增加或移除单词并重新组织句子的能力。
文档裁剪
新闻文章通常很长,在查看数据时,我发现对于分类来说并不需要整篇文章。 而且,我发现文章的主要想法通常会重复出现。
这让我想到将文章裁剪为几个子文章来实现数据增强,这样我将获得更多的数据。开始的时候我尝试从文档中抽取几个句子并创建10个新文档。这些新创建的文档句子间没有逻辑关系,所以用它们训练得到的分类器性能很差。第二次,我尝试将每篇文章分成若干段,每段由文章中五个连续的句子组成。这个方法就运行得非常好,让分类器的性能提升很大。
生成对抗网络
GAN是深度学习领域中最令人兴奋的最新进展之一,它们通常用来生成新的图像。下面这篇博客解释了如何使用GAN进行图像数据的数据增强,但它的一些方法或许也可以适用于文本数据。
博客链接:
https://towardsdatascience.com/generative-adversarial-networks-for-data-augmentation-experiment-design-2873d586eb59
迁移学习
迁移学习是指使用为其他任务训练的网络参数来解决你自己的问题,这些网络参数通常是用大性数据集训练得到的。迁移学习有时被用作某些层的初始化,有时也直接被用于特征提取让我们免于训练新模型。在计算机视觉中,从预先训练的ImageNet模型开始是解决问题的一种常见的做法,但是NLP没有像ImageNet那样可以用于迁移学习的大型数据集。
预训练的词向量
一般应用于自然语言处理的深度学习网络架构通常以嵌入层(Embedding Layer)开始,该嵌入层将一个词由独热编码(One-Hot Encoding)转换为数值型的向量表示。我们可以从头开始训练嵌入层,也可以使用预训练的词向量,如 Word2Vec、FastText 或 GloVe。
这些词向量是通过无监督学习方法训练大量数据或者是直接训练特定领域的数据集得到的。
预训练的词向量非常有效,因为基于大数据它们给模型提供了词的上下文并减少了模型的参数,从而显著地降低了过拟合的可能性。
更多有关词嵌入的信息:
https://www.springboard.com/blog/introduction-word-embeddings/
预训练的句向量
我们可以将模型的输入从单词转换为句子,用这种方法我们得到参数少并且性能好的简单模型。为了做到这一点,我们可以使用预训练的句子编码器,如 Facebook 的InferSent或谷歌的通用句子编码器。
我们还可以把数据集中未打标的数据用 skip-thought 向量或语言模型等方法训练句子编码器模型。
更多有关无监督句子向量的信息:
https://blog.myyellowroad.com/unsupervised-sentence-representation-with-deep-learning-104b90079a93
预训练的语言模型
最近很多论文运用大量语料库预训练语言模型来处理自然语言任务得到了惊人的结果,如ULMFIT,Open-AI transformer和BERT。语言模型是通过前面的单词预测句子中会出现的下一个单词。
这种预训练并没有对我取得更好的结果起到真正的帮助,但文章给出了一些我没有尝试过的方法来帮助我做更好地微调。
一个关于预训练语言模型很棒的博客:
http://ruder.io/nlp-imagenet/
预训练无监督或自监督学习
如果掌握大量无标签数据,我们可以使用无监督的方法如自动编码器或掩码语言模型去训练模型,这样仅仅依靠文本本身就可以做到。
对我来说另一个更好的选择是使用自监督模型。自监督模型可以在没有人工标注的情况下自动提取标签。Deepmoji项目是一个很好的例子。
在Deepmoji项目中,作者们训练了一个预测推文中表情符号的模型,在模型表现良好的情况下,他们使用网络预先训练了一个推文者的情绪分析模型来获取表情符号预测模型的状态。
表情符号预测和情绪分析显然非常相关,因此它作为预训练任务表现得非常好。自监督在新闻数据中的运用包括预测标题,报刊,评论数量,转发数量等。自监督是一种非常好的预训练方法,但通常很难分辨出代理标签与真实标签的关联。
使用现成的网络进行预训练
在很多公司中,大部分用于不同任务的机器学习模型都建立在相同的数据集或类似的数据集上。例如推文,我们可以预测其主题、观点、转发数量等。最好通过已经成熟应用的网络预先训练你的网络。对我的任务而言,应用这个方法确实可以提高性能。
特征工程
我知道深度学习“杀死”了特征工程,再谈特征工程已经有点过时了。但是当你没有大量数据时,通过特征工程帮助网络学习复杂模式可以大大提高性能。例如,在我对新闻文章的分类过程中,作者、报刊、评论数、标签以及更多特征可以帮助预测标签。
多模式体系结构
我们可以用多模式体系结构将文档级特征组合到我们的模型中。在多模式体系结构中,我们构建了两个不同的网络,一个用于文本,一个用于特征,合并它们的输出层(无 softmax)并添加更多层。这些模型很难训练,因为这些特征通常比文本具有更强的信号,因此网络主要受特征的影响。
关于多模式网络很棒的Keras教程:
https://medium.com/m/global-identity?redirectUrl=https://becominghuman.ai/neural-networks-for-algorithmic-trading-multimodal-and-multitask-deep-learning-5498e0098caf
这种方法使我的模型提高了不到1%的性能。
词级特征
词级特征是另一种类型的特征工程,如词性标注,语义角色标记,实体抽取等。我们可以将一个独热编码表示或一个词特征的嵌入与词的嵌入相结合并将其用作模型的输入。
我们也可以在这个方法中使用其他词特征,例如在情感分析任务中我们可以采用情感字典并添加另一个维度嵌入其中,用 1 表示在字典中的单词, 0 表示其他单词,这样模型可以很容易地学习它需要关注的一些词。在我的任务中,我添加了某些重要实体的维度,这给模型带来了一个很好的性能提升。
特征工程预处理
最后一种特征工程方法是以一种模型更容易学习的方式预处理输入文本。一个例子是“词干提取”,如果运动并不是一个重要标签,我们可以用运动代替足球,棒球和网球这些词,这将有助于神经网络模型了解到不同运动之间的差异并不重要,可以减少网络中的参数。
另一个例子是使用自动摘要。正如我之前所说,神经网络在长文本上表现不佳,因此我们可以在文本上运行自动摘要算法,如 TextRank 并仅向神经网络网络提供重要句子。
我的模型
尝试了本文中讨论的方法的不同组合后,在我的项目中表现最好的模型是本文中提到分层注意力网络(HAN),模型使用dropout 和 early stopping 作为正则化,并采用文档剪裁的方法进行数据集增强。我使用预训练的词向量以及我公司的一个预训练网络(这个网络使用了同样数据,只是针对的任务不一样)。
在做特征工程时,我新增了实体词级特征到词嵌入向量。这些变化使我的模型精确度提高了近 10%,模型效果从比随机效果稍好一点上升到了到具有重要业务价值的水准。
深度学习在小数据集上的应用仍处于该研究领域的早期阶段,但看起来它越来越受欢迎,特别是对于预训练的语言模型,我希望研究人员和从业者能够找到更多的方法使用深度学习,让每一个数据集产生价值。
-
机器学习
+关注
关注
67文章
8562浏览量
137209 -
数据集
+关注
关注
4文章
1240浏览量
26261 -
深度学习
+关注
关注
73文章
5604浏览量
124615
原文标题:【干货指南】机器学习必须需要大量数据?小数据集也能有大价值!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一些解决文本分类问题的机器学习最佳实践
从一个文本数据的文件夹中,怎样实现数据的连续提取
VS1053录音与数据传输怎么减小数据量
计算最大Lyapunov指数的推广小数据量法
打破深度学习偏见,这事跟数据量有啥关系?
大文本数据集的间接谱聚类
一些在文本数据量不够大的时候可用的一些实用方法
异构文本数据转换过程中解析XML文本的方法对比




评论