 一本100页的机器学习书籍近日大受好评
一本100页的机器学习书籍近日大受好评
这是一本只有100页,任何只要有基础数学知识的人都能看懂的机器学习书籍。本书将涵盖非监督学习和监督学习、包括神经网络,以及计算机科学、数学和统计学中最重要的一些机器学习问题。
一本100页的机器学习书籍近日大受好评。
书名The Hundred-Page Machine Learning Book,作者Andriy Burkov是Gartner的机器学习团队leader,人工智能专业PhD,有近20年各种计算项目的工作经验。
作者表示,他的目标是写一本任何有基础数学知识的人都能看懂的机器学习书籍。
这本书的前5章已经在该书的配套网站上公开。这本书将涵盖非监督学习和监督学习,包括神经网络,以及计算机科学、数学和统计学中最重要的一些ML问题,并通过例子提供直观的解释。代码和数据也将在网站上公开。
作者相信一本书应该“先读后买”,不仅可以免费下载已公开的章节,你也可以在这里订阅即将出版的章节:
http://themlbook.com/wiki/doku.php
已发布章节:
第1章:简介
第一部分:监督学习
第2章:符号和定义
第3章:基本算法
第4章:剖析学习算法
第5章:基本实践
以下是试读:第3章:基本算法
试读:第3章:基本算法
在本章中,我们描述了五种算法,这些算法不仅是最著名的,而且要么自身非常有效,要么被用作最有效的学习算法的构建块。
3.1 线性回归
线性回归是一种常用的回归学习算法,它学习的模型是输入示例特征的线性组合。
问题陈述
我们有一个标记示例的集合,其中N是集合的大小,是示例i = 1的D维特征向量,是一个实值目标(也是一个实数。
我们想要建立一个模型作为示例x的特征的线性组合:
其中w是参数的D维向量,b*是实数,wx是点积。符号表示模型f由两个值参数化:w和b。
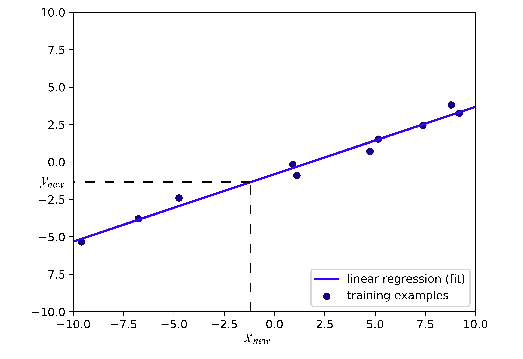
图1:一维示例的线性回归。
3.2 逻辑回归
首先要说的是逻辑回归不是回归,而是一个分类学习算法。这个名称来自统计学,因为逻辑回归的数学公式与线性回归的数学公式相似。
我们将在二元分类的情况下解释逻辑回归。但它也可以扩展到多元分类。
问题陈述
在逻辑回归中,我们仍然希望将这样的特征的线性组合是从负无穷大到正无穷大的函数,而只有两个可能的值。
在没有计算机的年代,科学家们不得不手工进行计算,他们非常想找到一个线性分类模型。他们发现如果将负标签定义为0,将正标签定义为1,就只需要找到一个codomain为(0,1)的简单连续函数。在这种情况下,如果模型为输入x返回的值更接近于0,那么我们为x分配负标签,否则,该示例将被标记为正。具有这种属性的一个函数是标准逻辑函数(也称为sigmoid函数):
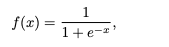
如图3所示。
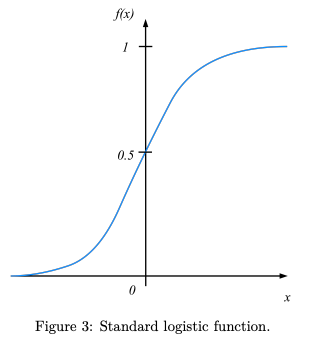
图3:标准逻辑函数
3.3 决策树学习
决策树是一个可用于做决策的非循环图。在图的每个分支节点中,检查特征向量的特定特征j。如果特征的值低于特定的阈值,则遵循左分支,否则,遵循右分支。当到达叶节点时,决定该示例所属的类。
问题陈述
我们有一组带标签的示例;标签属于集合{0,1}。我们想要构建一个决策树,允许我们在给定特征向量的情况下预测示例的类。
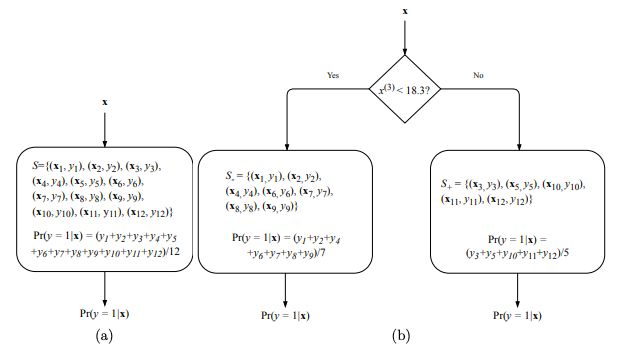
图4:决策树构建算法的图示。
3.4 支持向量机
关于SVM,有两个重要问题需要回答:
如果数据中存在噪声,并且没有超平面可以将正例和负例完美分开,该怎么办?
如果数据不能使用平面分离,但可以用高阶多项式分离呢?
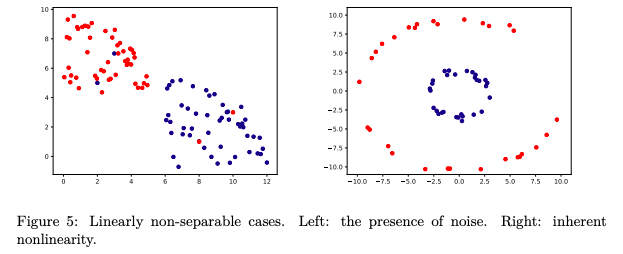
图5:线性不可分的情况。左:存在噪音。右:固有的非线性。
如图5中描述的两种情况。在左边的示例中,如果没有噪声(异常值或带有错误标签的示例),数据可以用直线分隔。在正确的情况下,决策边界是一个圆,而不是一条直线。
3.5 k-Nearest Neighbors
k-Nearest Neighbors(kNN)是一种非参数学习算法。与其他在构建模型后丢弃训练数据的学习算法相反,kNN将所有训练示例保存在内存中。一旦出现了一个新的、以前没见过的示例,kNN算法会在D维空间中找到k个最接近的例子并返回多数标签(在分类的情况下)或平均标签(在回归的情况下)。
两点的接近程度由距离函数给出。例如,上面看到的Euclidean distance在实践中经常使用。距离函数的另一个常用选择是负余弦相似性。余弦相似度的定义如下:
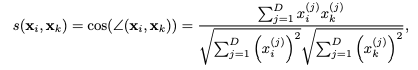
-
神经网络
+关注
关注
42文章
4773浏览量
100874 -
机器学习
+关注
关注
66文章
8423浏览量
132752 -
决策树
+关注
关注
3文章
96浏览量
13564
原文标题:100页的机器学习入门书:只要有基础数学知识就能看懂!(免费下载)
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文详解信号的回流路径
ROSCon China 2024 | RDK第一本教材来了!地瓜机器人与古月居发布新书《ROS 2智能机器人开发实践》

基于PYNQ和机器学习探索MPSOC笔记
什么是机器学习?通过机器学习方法能解决哪些问题?






 工商网监
工商网监
评论