 一台有道翻译王包括多少种AI技术?
一台有道翻译王包括多少种AI技术?
2018 年 9 月 6 日下午,网易有道在 AI 开放日上发布了全新一代有道翻译王 2.0 Pro。随后在 9 月 20 日举办的Google开发者大会上,有道技术总监林会杰分享了端侧 AI 在智能硬件产品上的重要性,并且现场演示了有道翻译王基于端侧 AI技术实现的全离线语音翻译功能。与云侧 AI 相比,端侧 AI 具有无网络延迟、更高的稳定性、数据隐私性、响应实时性, 这些特性使得端侧 AI 满足超低延迟场景,如文档扫描、AR 翻译、实时语音翻译等。
在这场发布会之前,有道技术团队已经在移动端离线 AI 技术上做了很多努力和探索。尤其是在端侧 AI 部分应用了 Google 发布的 TensorFlow Lite,本文将介绍有道翻译王的 AI 技术,以及 TensorFlowLite 在有道翻译王上的应用。
有道翻译王主要用到的 AI 技术有 OCR(光学字符识别)、NMT(神经机器翻译)、ASR(自动语音识别)、TTS(语音合成)。这些技术满足了一个翻译机的基本要求,通过在 TensorFlow Lite 框架上实现和加速,使得应用效果更加优异。
一台有道翻译王包括多少种 AI 技术?
OCR
光学字符识别(Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。有道 OCR 主要分为两个部分,一个是检测部分,另一个是识别部分。检测部分是指在一张图片上寻找文字所在区域并框选出来,然后将标出的区域送入识别部分从而得出结果。
NMT
近年来,深度学习技术的发展为解决上述挑战提供了新的思路。将深度学习应用于机器翻译任务的方法大致分为两类:
仍以统计机器翻译系统为框架,只是利用神经网络来改进其中的关键模块,如语言模型、调序模型等;
不再以统计机器翻译系统为框架,而是直接用神经网络将源语言映射到目标语言,即端到端的神经网络机器翻译(End-to-End Neural Machine Translation,End-to-End NMT),简称为 NMT 模型。
ASR
自动语音识别技术 ( Automatic Speech Recognition,ASR ) 是一种将人的语音转换为文本的技术。语音识别是一个多学科交叉的领域,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。由于语音信号的多样性和复杂性,语音识别系统目前只能在一定的限制条件下获得满意的性能,或者说只能应用于某些特定的场合。
TTS
语音合成(Text To Speech,TTS)技术将文本转化为声音,目前广泛应用于语音助手、智能音箱、地图导航等场景。TTS 的实现涉及到语言学、语音学的诸多复杂知识,因合成技术的区别,不同的 TTS 系统在准确性、自然度、清晰度、还原度等方面也有着不一样的表现。
以上这些 AI 技术会用到 CNN、RNN 等神经网络,这些网络会用到较为常用的算子,如卷积层、全连接层、池化层、Relu 层。由于 TensorFlow 工作流程相对容易,API 稳定,兼容性好,并且 TensorFlow 与 Numpy 完美结合,使其较为容易上手,所以我们在训练模型时主要采用 TensorFlow 框架,可以大大的降低成本和节省精力。
有道首个运用 TensorFlow Lite 技术的智能硬件设备
TensorFlow Lite 简介
TensorFlow Lite 是 TensorFlow 针对移动和嵌入式设备的轻量级解决方案。它为设备上的机器学习预测降低了延迟,减小了二进制大小。TensorFlow Lite 还支持硬件加速的 Android NNAPI。这样一来,就对算法的开发和部署有了很大的优势。
TensorFlow Lite 优势
轻量级:允许小 binarysize和快速初始化/启动的设备端机器学习模型进行推断。
跨平台:运行时的设计使其可以在不同的平台上运行,如目前支持的 Android 和 iOS。
快速:专为移动设备进行优化,包括大幅提升模型加载时间,支持硬件加速。
TensorFlow Lite 集成 Android 项目
(1)首先添加 TensorFlowLite 库到项目中:
compile ‘org.tensorflow:tensorflow-lite:+’
(2)然后导入 TFliteinterpreter:
import org.tensorflow.lite.Interpreter;
(3)这样就可以创建一个 Interpreter:
protected Interpreter tflite;
tflite = new Interpreter(loadModelFile(activity));
(4)载入模型函数示例:
/** Memory-map the model file in Assets. */
private MappedByteBuffer loadModelFile(Activity activity) throwsIOException {
AssetFileDescriptor fileDescriptor =activity.getAssets().openFd(getModelPath());
FileInputStream inputStream = newFileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel(); long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset,declaredLength);
}
(5)执行模型:
tflite.run(imgData, labelProbArray);
模型速度测试及比较
我们测试了常用的深度学习模型在 TensorFlow 和 TensorFlow Lite 上的运行速度, 模型分别为 InceptionV3、MobileNetV1、MobileNetV2。
同时,在 TensorFlow Lite 平台上,对浮点模型和量化模型进行速度测试比较。
TensorFlow 和 TensorFlow Lite 具有良好的通用性,除此之外,对于专有硬件平台,我们还对比了高通公司的SNPE ( Snapdragon Neural Processing Engine),测试InceptionV3 模型运行在骁龙 835 芯片的 CPU、GPU、DSP 上的速度。
测试有道 OCR Detection 模型在 TensorFlow、TensorFlow Lite 和高通 SPNE 上的运行情况。
由此可见,SNPE 的 CPU 运行速度要比 TensorFlow 的 CPU 速度慢了很多,但是在DSP 上的运行速度明显优于 CPU 和 GPU。虽然各大芯片厂商积极推出了高效能的神经网络处理器(NPU),但在模型转换和平台集成方面不尽如人意,其通用性和便利性远远不如 TensorFlow Lite。
TensorFlow Lite + 有道翻译王 探索更多可能性
近年来,网易有道在 AI 领域已经做出了很多尝试和探索,积累了很多经验,同时也创造了很多价值。随着深度学习的模型所需算力的增加,在移动端流畅运行模型则成为了一大挑战,为了解决这一大问题,各大硬件厂商推出神经网络加速芯片,软件厂商也通过各种优化来提高速度。Google 也为此做出了努力, 推出了 TensorFlow Lite,优化了模型体积,提高了运行速度,还可以通过NNAPI 实现硬件加速。
由于 TensorFlow Lite 具有良好的通用性,可以适应多种不同的硬件平台,所以在模型适配上节省了很多成本。目前 TensorFlow Lite 对 LSTM 的支持在不断完善,有道未来打算进一步完成相关模型的迁移和适配。同时也希望 TensorFlow Lite 能通过 Android NNAPI 可以集成更多的硬件平台,包括 Google 最新发布的 Edge TPU 等, 充分利用不同硬件平台的神经网络芯片加速,从而能够使得更多的 AI 技术能够更加高效率、低功耗、低延迟的运行在各种智能硬件设备上,真正实现让 AI 无处不在。
-
机器翻译
+关注
关注
0文章
139浏览量
14881 -
tensorflow
+关注
关注
13文章
329浏览量
60533 -
ai技术
+关注
关注
1文章
1272浏览量
24322
原文标题:当 TensorFlow Lite 遇到有道翻译王 2.0 Pro
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
IMAX携手Camb.AI实现影院实时语言翻译
提升工作效率,从共用一台屏幕开始
多个网站放在同一台服务器ip有什么影响?
主机托管是多个用户共享一台服务器吗?有什么优势
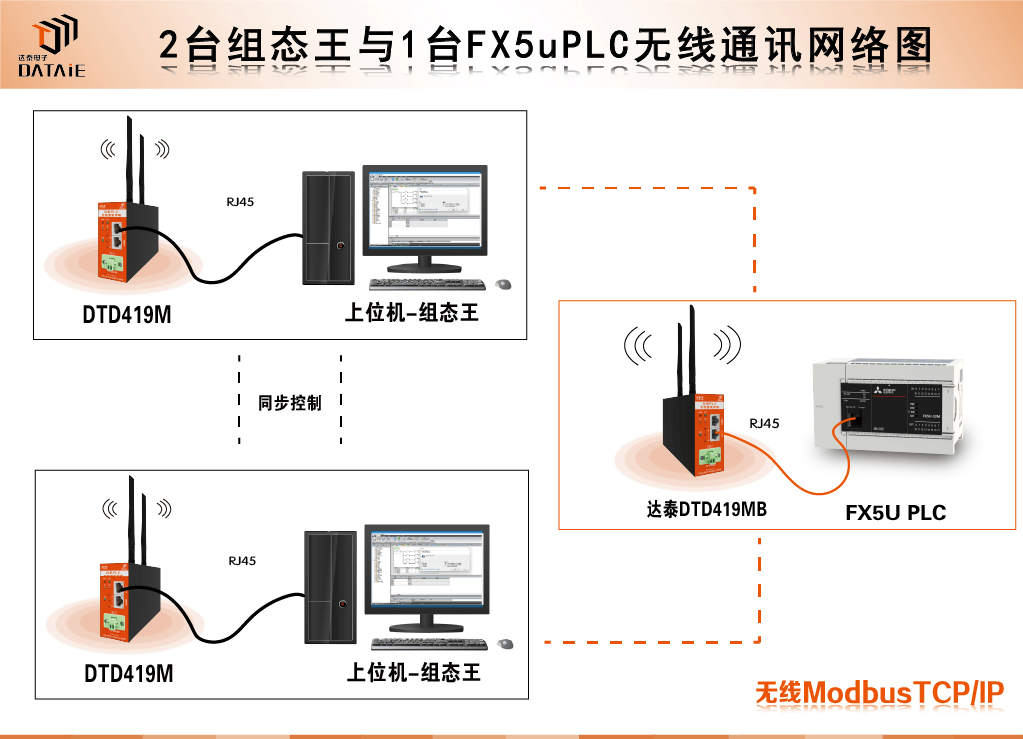
两台组态王与一台FX5u之间无线通信你见过吗?快速了解
王力新一代AI灵犀系列旗舰新品震撼发布,遥感技术3.0引行业热议!
手持式激光焊机一台多少钱?

NanoEdge AI的技术原理、应用场景及优势
Tesla 计划斥资 5 亿美元建造一台由 NVIDIA 的 AI GPU 提供支持的 Dojo 超级计算机

本地电脑远程控制工控现场一台丰炜PLC上,实现读写与监控PLC程序





 工商网监
工商网监
评论