 FAIR和谷歌大脑的合作研究,专注于“反向翻译”方法
FAIR和谷歌大脑的合作研究,专注于“反向翻译”方法
FAIR和谷歌大脑的合作研究,专注于“反向翻译”方法,用上亿合成单语句子训练NMT模型,在WMT’14 英语-德语测试集上达到35 BLEU的最优性能。论文在EMNLP 2018发表。
机器翻译依赖于大型平行语料库,即源语和目的语中成对句子的数据集。但是,双语语料是十分有限的,而单语语料更容易获得。传统上,单语语料被用于训练语言模型,大大提高了统计机器翻译的流畅性。
进展到神经机器翻译(NMT)的背景下,已经有大量的工作研究如何改进单语模型,包括语言模型融合、反向翻译(back-translation/回译)和对偶学习(dual learning)。这些方法具有不同的优点,结合起来能够达到较高的精度。
Facebook AI Research和谷歌大脑的发表的新论文Understanding Back-Translation at Scale是这个问题的最新成果。这篇论文专注于反向翻译(BT),在半监督设置中运行,其中目标语言的双语和单语数据都是可用的。
反向翻译首先在并行数据上训练一个中间系统,该系统用于将目标单语数据转换为源语言。其结果是一个平行的语料库,其中源语料是合成的机器翻译输出,而目标语料是人类编写的真实文本。
然后,将合成的平行语料添加到真实的双语语料(bitext)中,以训练将源语言转换为目标语言的最终系统。
虽然这种方法很简单,但已被证明对基于短语的翻译、NMT和无监督MT很有效。
具体到这篇论文,研究人员通过向双语语料中添加了数亿个反向翻译得到的句子,对神经机器翻译的反向翻译进行了大规模的研究。
实验基于在WMT竞赛的公共双语语料上训练的强大基线模型。该研究扩展了之前的研究(Sennrich et al. , 2016a ; Poncelas et al. , 2018) 对反译法的分析,对生成合成源句的不同方法进行了全面的分析,并证明这种选择很重要:从模型分布中采样或噪声beam输出优于单纯的beam search,在几个测试集中平均 BLEU高1.7。
作者的分析表明,基于采样或noised beam search的合成数据比基于argmax inference的合成数据提供了更强的训练信号。
文章还研究了受控设置中添加合成数据和添加真实双语数据的比较,令人惊讶的是,结果显示合成数据有时能得到与真实双语数据不相上下的准确性。
实验中,最好的设置是在WMT ’14 英语-德语测试集上,达到了35 BLEU,训练数据只使用了WMT双语语料库和2.26亿个合成的单语句子。这比在大型优质数据集上训练的DeepL系统的性能更好,提高了1.7 BLEU。在WMT ‘14英语-法语测试集上,我们的系统达到了45.6 BLEU。
合成源语句子
反向翻译通常使用beam search或greed search来生成合成源句子。这两种算法都是识别最大后验估计(MAP)输出的近似算法,即在给定输入条件下,估计概率最大的句子。Beam search通常能成功地找到高概率的输出。
然而,MAP预测可能导致翻译不够丰富,因为它总是倾向于在模棱两可的情况下选择最有可能的选项。这在具有高度不确定性的任务中尤其成问题,例如对话和说故事。我们认为这对于数据增强方案(如反向翻译)来说也是有问题的。
Beam search和greed search都集中在模型分布的头部,这会导致非常规则的合成源句子,不能正确地覆盖真正的数据分布。
作为替代方法,我们考虑从模型分布中采样,并向beam search输出添加噪声。
具体而言,我们用三种类型的噪音来转换源句子:以0.1的概率删除单词,以0.1的概率用填充符号代替单词,以及交换在token上随机排列的单词。
模型和实验结果
我们使用fairseq工具包在pytorch中重新实现了Transformer 模型。所有的实验都是基于Big Transformer 架构,它的编码器和解码器都有6个block。所有实验都使用相同的超参数。
实验结果:不同反向翻译生成方法的准确性比较
实验评估首先比较了反向翻译生成方法的准确性,并分析了结果。

图1:在不同数量的反向翻译数据上训练的模型的准确性,这些数据分别通过greedy search、beam search (k = 5)和随机采样得到。
如图1所示,sampling和beam+noise方法优于MAP方法,BLEU要高0.8-1.1。在数据量最大的设置下,sampling和beam+noise方法比bitext-only (5M)要好1.7-2 BLEU。受限采样(top10)的性能优于beam 和 greedy,但不如非受限抽样(sampling)或beam+noise。

图2:对于不同的合成数据,每个epoch的Training perplexity (PPL)。
图2显示,基于greedy或beam的合成数据与来自采样、top10、 beam+noise和bitext的数据相比更容易拟合。
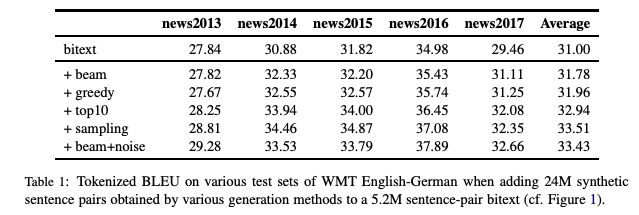
表1
表1展示了更广泛的测试集的结果(newstest2013-2017)。 Sampling和beam+noise 的表现大致相同,其余实验采用sampling。
资源少 vs 资源多设置
接下来,我们模拟了一个资源缺乏的设置,以进一步尝试不同的生成方法。

图3:在80K、640K和5M句子对的bitext系统中添加来自beam search和sampling的合成数据时,BLEU的变化
图3显示,对于数据量较大的设置(640K和5.2M bitext),sampling比beam更有效,而对于资源少的设置(80K bitext)则相反。
大规模的结果
最后,我们扩展到非常大的设置,使用多达226M的单语句子,并且与先前的研究进行了比较。
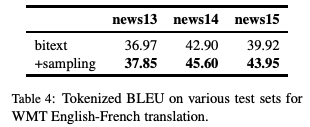
表4:WMT英语-法语翻译任务中,不同测试集上的Tokenized BLEU
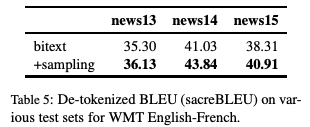
表5:WMT英语-法语翻译任务中,不同测试集上的De-tokenized BLEU (sacreBLEU)

表6:WMT 英语-德语 (En-De)和英语-法语 (En-Fr)在newstest2014上的BLEU。
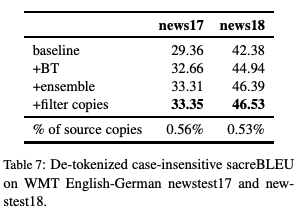
表7:WMT英语-德语newstest17和newstest18上的非标记、不区分大小写的sacreBLEU。
结论
反向翻译是一种非常有效的神经机器翻译数据增强技术。通过采样或在beam输出中添加噪声来生成合成源句子,比通常使用的argmax inference 具有更高的精度。
特别是,在newstest2013-2017的WMT英德翻译中,采样和加入噪声的beam比单纯beam的平均表现好1.7 BLEU。这两种方法都为资源缺乏的设置提供了更丰富的训练信号。
此外,这一研究还发现,合成数据训练的模型可以达到真实双语语料训练模型性能的83%。
最后,我们只使用公开的基准数据,在WMT ‘14英语-德语测试集上实现了35 BLEU的新的最优水平。
-
机器翻译
+关注
关注
0文章
139浏览量
14872 -
数据集
+关注
关注
4文章
1205浏览量
24635
原文标题:NLP重磅!谷歌、Facebook新研究:2.26亿合成数据训练神经机器翻译创最优!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电路反向研究。。
人类首创能生成神经细胞的“迷你大脑”,更精确模拟神经网络!
程序员的大脑有什么不同?
基于浅层句法信息的翻译实例获取方法研究
神奇大脑信号翻译器 可将思想变语言
美国研制出大脑思维翻译器欲将思想变语言
谷歌翻译对比有道翻译东北话,高下立见!
谷歌翻译竟然预言世界末日?

谷歌翻译加入离线AI翻译功能,离线也能翻译而且更准确
DARPA专注于无需手术的神经技术研究,让身体健全的士兵拥有超能力技术
小扎邀请LeCun:FAIR诞生,与谷歌争人才
谷歌大脑开发人类翻译器 打破AI黑盒新方式
谷歌宣布Android Things转为专注于智能音箱的平台
谷歌希望为现实世界带来更多机器人 专注于更简单的自动化工作
手语识别、翻译及生成研究综述






 工商网监
工商网监
评论