 基于模型的学习vs无模型学习
基于模型的学习vs无模型学习
听到“强化学习”,你首先想到的是什么?最常见的反应是有太多数学知识、非常复杂。但是我认为这是一个非常迷人的研究领域,在今天的文章中,我会把其中的技术分解成多种易于理解的概念。
你一定听说过OpenAI和DeepMind,这两家机构在强化学习领域都作出了重要进步。OpenAI的强化学习智能体可以在Dota 2中击败人类对手。
你是否认为我们用动态编程可以打造一个像Dota 2一样复杂的机器人呢?
很不幸,答案是否定的。因为Dota 2中的状态有很多,要收集所有具体状态几乎不可能。所以我们开始采用强化学习或者更具体的无模型学习。
在这篇文章中,我们要试着理解蒙特卡罗学习的基本概念。当没有有关环境的先验信息时,所有的信息都从经验中获取,此时就要用到蒙特卡罗学习方法。在这一过程中,我们会用到OpenAI Gym工具包,并且用Python实现这一方法。
基于模型的学习 vs 无模型学习
我们知道,动态编程适用于解决已知环境基础模型的问题(更准确地说是基于模型的学习)。强化学习指的是从玩游戏的经验中学习,但是,我们却从未在动态编程中玩过游戏,或者体验环境。我们有关于环境的完全模型,其中包含了所有状态转换的可能。
但是,在大多数现实生活情境中,从一种状态转换到另一种状态的可能性是无法提前预知的。
假设我们想训练一个机器人学习下象棋,将棋盘环境的变化看作是马尔科夫决策过程(MDP)。
现在根据棋子的位置,环境可以有很多种状态(超过1050),另外还会有许多可能做出的动作。这种环境下的模型几乎无法设计出来。
一种可能的解决方法是重复地下棋,接收到可以获胜的积极奖励以及会输掉比赛的消极奖励。这就是从经验中学习的过程。
蒙特卡罗方法案例
通过生成合适的随机数,并观察数字遵循一定特征的,这种方法都可以看作是蒙特卡罗方法。
在下面的案例中,我们试着用笔和纸找到π的值。首先画一个正方形,然后以原点为圆心,正方形边长为半径画圆。现在我们用C3PO机器人在正方形内随机画点,一共有3000个点,结果如下:
所以,π的值用以下公式计算:
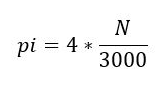
其中N是红点落入圆圈中的次数。可以看到,我们通过计算随机点的比例估算出了π的值。
蒙特卡罗强化学习
用于强化学习的蒙特卡罗方法是直接从经验中学习,没有先验知识。这里的随机因素就是返回结果或奖励。
需要注意的是,这种方法只能应用于偶尔发生的马尔科夫决策过程。原因是在计算任意返回之前,这一episode就要停止。我们并不在每次动作结束后就更新,而是在每个episode结束后更新。它的方法很简单,即取每个状态所有采样轨迹的平均回报。
和动态编程类似,这里有一种策略评估和策略改进方法,我们将在下面两个部分进行讲解。
蒙特卡罗方法评估
这里的目标是学习在策略pi的训练下得到的价值函数vpi(s)。返回的值是总体折扣奖励:
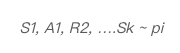
同时价值函数是预期回报:
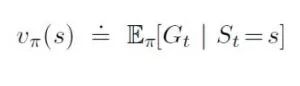
我们可以通过添加样本并除以总样本数来估计预期值:
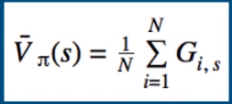
其中i表示episode指数,s表示状态指数。
问题时我们要如何得到这些样本的返回值?为了做到这一点,我们需要运行多个episode来生成它们。
对每次运行的episode,我们会有一系列状态和奖励。对于奖励,我们可以用定义计算返回值,是左右未来奖励的总和。
以下是算法每一步的内容:
对策略、价值函数进行初始化
根据当前策略生成一次episode并跟踪这一过程中遇到的状态
从上一步中选择一种状态。
当这一状态第一次出现时,将接收到的返回值添加到列表中
对所有返回值进行平均
计算平均值时设定状态的值
4. 重复步骤3
这里我们重点讲解步骤3.1,“添加收到的返回值到列表中”。
用一个简单例子理解这一概念,假设这里有一种环境,其中包含了两种状态A和B。以下是两次样本的episode:
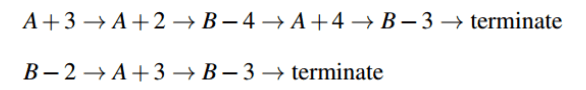
A+3=>A表示从状态A转移到状态A需要奖励+3.
蒙特卡罗控制
和动态编程类似,一旦我们有了随机策略中的价值函数,重要的任务就是用蒙特卡罗寻找优化策略。
用模型改进策略所需的公式如下:
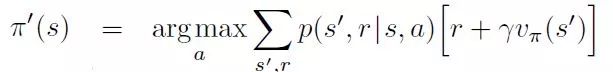
该公式通过寻找可以将奖励最大化的动作,对策略进行了优化。但是,这里的重点是用了迁移概率,这在无模型学习中是无法获取的。
因为我们不知道状态迁移概率p(s’,r/s,a),我们不能提前进行搜索。于是,所有信息都是通过玩游戏或环境探索得来的。
策略的改进是根据当前价值函数让策略变得贪婪,在这种情况下,我们有了一个动作-价值函数,所以在建立贪婪策略时不需要模型。
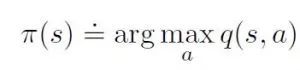
如果大多数动作并没有得到具体研究,一种贪婪策略只会支持一个特定动作。解决方法有两种:
Exploring starts
在这种算法中,所有状态的动作对是不可能成为起始对的,这就保证了每个episode都会带领智能体到新状态中,所以智能体会对环境有更多了解和探索。

epsilon-Soft
如果环境中只有一个起始点该怎么办(例如棋盘类游戏)?这个时候探索起始点就没有意义了,这里就要用到ϵ-贪婪方法。
想保证探索继续进行,最简单的方法就是以非零概率尝试所有动作。ϵ选择的动作可以将价值函数最大化,并且随机选择动作。

现在我们理解了基础的蒙特卡罗控制和预测,接下来就用Python实现这些算法吧。我们会导入OpenAI Gym中的冰冻湖环境进行演示。
用Python实现蒙特卡罗方法
智能体控制人物在网格中的移动,其中一些是可以移动的,另一些可能会让智能体掉入水中。另外,智能体的移动方向是不确定的,如果智能体找到正确的路就能获得奖励。
S:起始点,安全;F:冰冻湖面,安全;H:洞,危险;G:目标点
游戏的任务就是让智能体从起始点到达目标点,不要掉进洞里。这里附上OpenAI Gym的安装细节和文件:gym.openai.com/docs/,下面就开始用Python实现吧!
首先,我们要定义集中函数设置蒙特卡罗算法。
创建环境
import gym
import numpy as np
importoperator
fromIPython.display import clear_output
from time import sleep
import random
import itertools
import tqdm
tqdm.monitor_interval = 0
随机策略函数
def create_random_policy(env):
policy = {}
for key in range(0, env.observation_space.n):
current_end = 0
p = {}
for action in range(0, env.action_space.n):
p[action] = 1 / env.action_space.n
policy[key] = p
return policy
存储状态动作值的词典
def create_state_action_dictionary(env, policy):
Q = {}
for key in policy.keys():
Q[key] = {a: 0.0for a in range(0, env.action_space.n)}
return Q
运行episode的函数
def run_game(env, policy, display=True):
env.reset()
episode = []
finished = False
whilenot finished:
s = env.env.s
if display:
clear_output(True)
env.render()
sleep(1)
timestep = []
timestep.append(s)
n = random.uniform(0, sum(policy[s].values()))
top_range = 0
for prob in policy[s].items():
top_range += prob[1]
if n < top_range:
action = prob[0]
break
state, reward, finished, info = env.step(action)
timestep.append(action)
timestep.append(reward)
episode.append(timestep)
if display:
clear_output(True)
env.render()
sleep(1)
return episode
测试策略和计算获胜概率的函数
def test_policy(policy, env):
wins = 0
r = 100
for i in range(r):
w = run_game(env, policy, display=False)[-1][-1]
if w == 1:
wins += 1
return wins / r
首次蒙特卡罗预测和控制
def monte_carlo_e_soft(env, episodes=100, policy=None, epsilon=0.01):
ifnot policy:
policy = create_random_policy(env) # Create an empty dictionary to store state action values
Q = create_state_action_dictionary(env, policy) # Empty dictionary for storing rewards for each state-action pair
returns = {} # 3.
for _ in range(episodes): # Looping through episodes
G = 0# Store cumulative reward in G (initialized at 0)
episode = run_game(env=env, policy=policy, display=False) # Store state, action and value respectively
# for loop through reversed indices of episode array.
# The logic behind it being reversed is that the eventual reward would be at the end.
# So we have to go back from the last timestep to the first one propagating result from the future.
for i in reversed(range(0, len(episode))):
s_t, a_t, r_t = episode[i]
state_action = (s_t, a_t)
G += r_t# Increment total reward by reward on current timestep
ifnot state_action in [(x[0], x[1]) for x in episode[0:i]]: #
if returns.get(state_action):
returns[state_action].append(G)
else:
returns[state_action] = [G]
Q[s_t][a_t] = sum(returns[state_action]) / len(returns[state_action]) # Average reward across episodes
Q_list = list(map(lambda x: x[1], Q[s_t].items())) # Finding the action with maximum value
indices = [i for i, x in enumerate(Q_list) if x == max(Q_list)]
max_Q = random.choice(indices)
A_star = max_Q # 14.
for a in policy[s_t].items(): # Update action probability for s_t in policy
if a[0] == A_star:
policy[s_t][a[0]] = 1 - epsilon + (epsilon / abs(sum(policy[s_t].values())))
else:
policy[s_t][a[0]] = (epsilon / abs(sum(policy[s_t].values())))
return policy
完成后运行算法并检查奖励:
结语
蒙特卡罗学习到此并未结束,除此之外还有另一类称为“离线蒙特卡罗”的方法,这种方法用另一种策略生成的返回值学习优化策略。
本文提到的是在线方法,类似在做中学,而离线方法更强调的是看别人的示范从中学习。
-
智能体
+关注
关注
1文章
175浏览量
10638 -
强化学习
+关注
关注
4文章
268浏览量
11311
原文标题:用OpenAI Gym工具解释蒙特卡罗学习
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

【《大语言模型应用指南》阅读体验】+ 基础知识学习
深度学习模型是如何创建的?
随机块模型学习算法
BigBiGAN问世,“GAN父”都说酷的无监督表示学习模型有多优秀?
太秀了!DeepMind推出最强表示学习模型BigBiGAN
机器学习中的无模型强化学习算法及研究综述

模型化深度强化学习应用研究综述






 工商网监
工商网监
评论