 如何通过速度匹配将雷达添加到融合管道中
如何通过速度匹配将雷达添加到融合管道中
自动驾驶中的环境感知传统上采用传感器融合的方法,将安装在汽车上的各种传感器的目标检测组合成单一的环境表征。未经校准的传感器会导致环境模型中的伪像和像差,这使得像自由空间探测这样的任务更具挑战性。在本研究中,我们改进了Levinson和Thrun的LiDAR和相机融合方法。我们依靠强度不连续性以及边缘图像的侵蚀和膨胀来增强对阴影和视觉模式的鲁棒性,这是点云相关工作中反复出现的问题。此外,我们使用无梯度优化器而不是穷举网格搜索来寻找外部校准。因此,我们的融合管道重量轻,能够在车载计算机上实时运行。对于检测任务,我们修改了快速R - CNN架构,以适应混合LiDAR -摄像机数据,从而改进目标检测和分类。我们在KITTI数据集和本地收集的城市场景上测试我们的算法。
自动驾驶汽车依靠各种传感器来感知环境。为了建立他们周围世界的一致模型,并在其中安全地工作,需要融合不同传感器的数据[1]。每种类型的传感器都有自己的优点和缺点[ 2 ]。RGB摄像机能够感知来自周围世界的颜色和纹理信息,并能很好地完成目标分类任务,然而,它们的探测范围有限,在有限的光照或恶劣的天气条件下表现不佳。LiDARs提供精确的距离信息,其范围可以超过100米,并且能够探测到小物体。它们在夜间也能很好地工作,但不提供颜色信息,而且在大雨中它们的性能会下降[3][4]。雷达提供精确的距离和速度信息,在恶劣天气条件下工作良好,但分辨率较低[5]。
如今,高级融合( HLF )是一种非常流行的传感器融合方法,[ 1 ]。HLF分别用每个传感器检测对象,并随后组合这些检测。因此,对象检测是在可用信息有限的地方进行的,因为如果存在多个重叠对象和工件,则HLF会丢弃置信值较低的分类。相反,低级融合(LLF)在原始数据级别结合了来自不同传感器类型的数据,从而保留了所有信息,并潜在地提高了目标检测的准确性。
LLF本质上是复杂的,伴随着几个挑战,需要对传感器进行非常精确的外部校准,以正确融合传感器对环境的感知。此外,传感器记录需要时间同步并补偿自我运动。然后,多模态输入数据可以用于深度神经网络的目标检测。融合和检测算法都必须能够在公路驾驶场景中实时运行。近年来,LLF以其潜在的优势引起了人们的关注。例如,Chen等人。[6]发展了一种用于LiDAR和摄像机数据的融合方法,这种方法在Kitti数据集的三维定位和三维检测方面优于现有的方法[7]。
LevinsonandThrun[8]提出了一种用于LiDAR和摄像机外部标定的算法,但不使用融合的数据进行目标检测。Geiger等人提出了一种基于三维目标标定的方法。[9]在同一场景中使用多个棋盘,并使用带有距离传感器或Microsoft Kinect的三目相机。对于我们的LLF方法,我们改进了LevinsonandThrun[8]的外部LiDAR相机标定方法,我们将冲蚀和膨胀应用于反距离变换的图像边缘,发现这些形态平滑了目标函数,提高了对场景中阴影和其他视觉模式的鲁棒性。
定性的COM-Parison之间的方法和Kitti提供的外部SiC校准表明,我们的方法产生了一个更好的视觉拟合。此外,我们用无梯度优化算法代替了对变换参数的穷举网格搜索。我们将LiDAR点云投影到RGB图像上,对其进行采样,然后从中提取特征。我们采用了更快的R - CNN架构[10]来处理融合的输入数据。结果表明,使用融合的LiDAR和摄像机数据改善了Kitti数据集[ 7 ]上的目标检测结果。我们的传感器融合算法能够以10Hz的频率实时运行。此外,我们展望了激光雷达和雷达之间外部校准的新方法。
其余的工作安排如下。在第Ⅱ节中,我们概述了相关工作。在第III节中,我们推导了我们的算法。首先,我们讨论了LiDAR与摄像机的融合;随后,我们提出了我们对更快的R-CNN架构的修改,以利用融合的数据。在第Ⅳ节中,讨论了我们的结果,最后对今后的工作进行了总结和展望。
Ⅱ.相关工作
相机和LiDAR之间外部校准的计算通常依赖于预先定义的标记,如棋盘或AR标签,校准过程本身大多是离线的。Dhall等人的方法[ 11 ]使用特殊编码的ArOco标记[ 12 ]来获得LiDAR和相机之间的3D - 3D点对应关系。Velas等人的校准方法[ 13 ]也依赖于特定的3D标记。在[ 14 ] 中,Schneider等人提出了一种基于深度学习的端到端特征提取、特征匹配和全局回归的体系结构。他们的方法能够实时运行,并且可以针对在线错误校准误差进行调整。然而,从头开始训练系统需要大量数据。此外,每辆车都需要单独收集数据,因为传感器的排列和内部结构可能会有所不同。Castlerena等人的研究[ 15 ]基于使用反射率值的光学相机和LiDAR数据之间的边缘对齐,使用KITTI外部参数作为地面真实情况,他们实现了接近KITTI精度的无目标方法。Levinson和Thron [ 8 ]的无目标相机LiDAR校准方法适合图像和点云数据中的边缘,但使用了详尽的网格搜索。我们的外部校准方法建立在此基础上,但是在线工作,不需要对参数进行详尽的计算搜索。
III.方法
这一部分概述了当前与相机和LiDAR传感器数据融合相关的研究,包括内部传感器校准、传感器之间的外部校准和数据融合,以创建混合数据类型。传感器融合可分为三类:LLF、中层融合( MLF )和HLF。HLF是汽车原始设备制造商最流行的融合技术,主要是因为它使用了供应商提供的传感器对象列表,并将它们集成到环境模型[1]中。然而,由于传感器没有相互校准,这种方法会导致像差和重复物体。防止这些问题发生的一种方法是融合原始传感器数据( LLF )。MLF是位于LLF之上的一种抽象,从多个传感器数据中提取的特征被融合在一起。图1显示了我们车上的传感器设置,图2给出了整个融合管道的概述。以下各节将更详细地解释每个部分。
A.激光雷达和照相机的融合
在本节中,我们描述了LiDAR和相机的外部校准方法、LiDAR点云( PC )在图像上的投影、其采样和深度图中的特征提取。为了确保同时捕获PC和图像,我们通过软件触发两个传感器的记录,并使用Velodyne HDL - 64E S3作为我们的LiDAR传感器,它以10Hz的频率旋转。为了减少捕获的PC的失真,我们补偿了传感器记录期间车辆的自我运动。
图1.宝马测试车的传感器设置由LiDAR (红色箭头)、摄像机(蓝色箭头)和雷达(绿色箭头)组成。
外部传感器校准依赖于传感器的精确内部校准。3 * 4相机固有矩阵定义了从相机到图像坐标系的齐次坐标投影。我们遵循Datta等人的方法[ 16 ]并使用环形图案校准板(见图3 ),对参数进行迭代细化。与棋盘式照相机的标准校准方法相比,我们观察到平均再投影误差减少了70 %。本征LiDAR校准由制造商提供,该校准定义了从每个发射器到传感器基座坐标系的转换。
图2.我们的传感器融合和物体检测管道概述。左图显示了传感器之间的外部校准,并且仅在需要新校准时执行一次。右图显示了周期性运行的传感器融合和目标检测/定位的管道。
图3.用于摄像机校准的环形花纹板。按照[16]的内禀摄像机标定方法,与[17]的标准标定方法相比,平均再投影误差降低了70%。
图4.LiDAR和照相机外定标的问题说明。计算两个传感器之间的外定标是指估计它们的坐标系之间的旋转R和平移t。我们明确地计算从LiDAR到摄像机的距离,并且能够推断出另一个方向。
LiDAR和摄像机之间的外部校准对应于在它们的坐标系之间找到4*4变换矩阵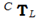 。
。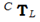 由旋转和平移组成,因此具有六个自由度( DoFs ) (见图4 )。为了找到LiDAR和摄像机之间的外部校准,我们通常遵循Levinson和Thron [ 8 ]的方法,但对其进行了一些调整,如下文所述。
由旋转和平移组成,因此具有六个自由度( DoFs ) (见图4 )。为了找到LiDAR和摄像机之间的外部校准,我们通常遵循Levinson和Thron [ 8 ]的方法,但对其进行了一些调整,如下文所述。
图5. 图5.由于没有对提取的边缘图像应用侵蚀和膨胀而导致的非最佳校准估计。顶部(底部)图像显示了提取的边缘图像( RGB图像),基于校准估计,该边缘图像没有被投影的PC覆盖。RGB图像中来自右侧汽车中心和下方树木的小阴影会产生边缘,PC数据中不存在相应的边缘。因此,优化方法将产生非最优校准估计,这可以在右侧的汽车轮胎上看到。ED能够减少这种小纹理的影响。
基本概念是找到定义的六个参数,使得相机图像中的边缘匹配点云测量中的不连续性。出于这个原因,我们定义了一个相似性函数S。我们对投影点云图像X的深度不连续性与边缘图像E进行元素乘法,并在所有像素i上返回该乘积的和。为了平滑目标函数并覆盖更多场景,我们使用N对点云和图像,并对它们的匹配分数求和。目标是找到最大化的变换:
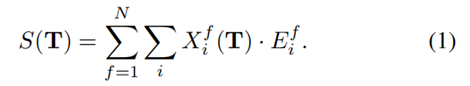
边缘图像E如下所示。我们将RGB图像转换成灰度,并用Sobel算子计算其边缘。为了奖励几乎匹配的PC和图像边缘,我们模糊了图像边缘。Levinson和Thron [ 8 ]为此目的使用了逆距离变换( IDT )。另一种可能是应用高斯滤波器。结果表明,IDT与侵蚀扩张(ED)联合应用效果最好。IDT ED提高了场景中阴影的鲁棒性,这在驾驶场景中非常常见。图5展示了IDT + ED的优势。在此图像中,ED尚未应用。图像右侧中央和汽车下方树木的小阴影会产生图像边缘,PC中不存在相应的边缘。然而,优化方法将试图匹配这些边缘,导致更差的校准估计。在这种情况下,缺少ED会产生校准误差,这可以在车辆右侧的轮胎上看到。ED能够减少图像中如此小的纹理差异的影响。如同在[ 8 ]中一样,我们提取PC P中的范围不连续性,产生不连续性P*的点云,具有
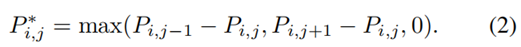
除了在[8]中,PI,j不仅可以表示深度,也可以表示i束Jth测量的强度。我们发现,利用强度值获得的标定结果更好,因为具有边缘和不同材料的平面表面不显示范围而是强度不连续。然后将新获得的PC用估计变换到摄像机坐标系,然后用摄像机内禀矩阵投影到图像平面上,得到投影点云图像X。
相似函数S是非凸的,不能解析求解。Levinson和Thrun [ 8 ]在六个参数上使用一个计算成本高昂的穷举网格搜索进行初始校准,然后在线逐步调整。由于我们如上所述对它们的方法进行了修改,我们能够从参数的初始猜测开始使用无梯度优化方法来找到最优的。我们使用BOBYQA [ 18 ],这是一种迭代算法,用于在优化变量的边界下找到黑体函数的最小值。BOBYQA依赖于具有信任区域的二次近似。我们能够从最初几厘米/度的猜测开始找到最佳参数。因此,我们的方法能够考虑制造公差。
图6.用匹配和不匹配的外部LiDAR相机校准比较与PC强度值重叠的图像。上图显示了LiDAR相机外部与未对齐的图像和PC边缘不匹配。在底部图像中,外部匹配良好,边缘对齐良好。
通过利用正确外部校准周围的局部凸性,有可能跟踪外部校准估计的正确性,如[ 8 ]所示。想法是分析当前的校准C是否导致S的局部最大Sc。理想情况下,如果给定的校准C是正确的,那么与C的任何小偏差都会降低相似性分数。我们在所有6个维度上执行以给定校准C为中心的单位半径网格搜索,得到36= 729个不同的相似度分数S。其中一个将是位于网格中心的Sc本身。FC是其他728个产生的S值低于SC的分数。如果外部校准C正确,这728个值中的大多数应该小于SC,导致FC接近1。图7显示了对于给定校准,相似性分数低于SC的校准百分比,从而得出了不同校准估计的一系列帧上的FC图。我们可以看到,正确的外部校准对应于比不正确校准更大的FC。
图7.给定校准估计值周围的校准百分比,其相似性分数低于不同帧上实际估计值的相似性分数。红色曲线对应于多个帧上正确校准的FC,而所有其他曲线对应于不正确校准。
PC用变换,随后用投影到RGB图像上,产生RGB图像,其中深度是稀疏的。图6显示了具有匹配和非匹配外部校准的RGBD图像的可视化。对于神经网络在融合数据上的训练和评估,我们需要标记数据。由于标签价格昂贵,我们希望利用来自预先培训的网络的权重。对于图像数据来说,这可以很容易地完成,因为大量标记数据是免费提供的。
然而,对于投影的LiDAR数据,情况并非如此。因此,我们的目标是以类似RGB图像特征的方式对稀疏深度图进行编码。这种编码方案允许我们也使用来自图像数据的预先训练的网络权重,用于网络中的深度通道。
我们通过首先使用Prebida等人提出的双边滤波器对稀疏深度图进行上采样来实现这种编码。[ 19 ]得到了一张密集的深度图。然后,我们可以从稠密的深度图中提取类似图像的特征。Etel等人提出的喷射着色产生了一组这样的特征[ 20 ]。通过将喷射颜色映射应用于标准化深度值,可以简单地获得三通道编码。此外,我们还提取了HHA(水平视差、离地高度、相对重力的角度)特征[21]。两组三通道特征显示出与RGB数据相似的结构。编码深度数据的尺寸与摄像机数据的尺寸相匹配。RGB与JET / HHA结合产生总共六个数据通道,代表我们的融合数据。
B.融合数据上的目标检测
LLF和MLF的基本思想是利用来自多感官融合数据的更明显和更有区别的特征集,这可以提高检测和分类的准确性。对于LLF,我们使用带有VGG16 [ 10 ]的标准快速R - CNN管道,并修改其输入层以容纳6通道输入数据。对于MLF,我们复制了快速R - CNN网络的前四个卷积层,并为每个摄像机和LiDAR数据处理使用一个单独的分支。我们将每个分支的第四卷积层之后的特征向量连接起来,并将其输入到标准快速R - CNN架构的上部。我们使用转移学习[ 22 ]并将权重从仅RGB网络初始化到每个子网络,用于基于MLF的检测。对于LLF,我们保持卷积滤波器的数量与最初的快速R - CNN网络相同。对于MLF,由于有两个分支,前四层中的参数数量增加了一倍。
对“汽车”和“行人”类别进行检测和分类。在我们的实验中,我们将三种更快的R - CNN网络架构用于仅RGB、RGB深度LLF和RGB深度MLF。RGB - only是标准的快速R - CNNN架构,仅使用相机数据作为输入。我们用融合数据训练RGB深度线性调频和RGB深度线性调频,并同时使用JET和HHA深度编码。RGB深度LLF的输入由六通道融合数据组成。RGB深度MLF的输入包括RGB和到各个网络分支的深度编码数据。
Ⅳ.结果
结果部分分为传感器校准以及LLF和MLF的目标检测和定位结果。我们的方法已经在Kitti [ 7 ]和当地收集的城市场景数据集上进行了评估。在这里,我们只给出公开的KITTI数据集的结果。
宝马测试车如图1所示,用于记录内部数据集,并在实践中评估传感器融合和检测管道。这辆车包含一台装有用于融合的英特尔至强处理器的计算机和一张运行神经网络的NVIDIA显卡。本研究中使用的传感器是Velodyne HDL - 64E S3、Point Gray Research公司的Grashhopper 2 GS2 - GE - 50S 5C - C摄像机和Axis通信P1214 - E网络摄像机。传感器融合以10Hz运行,与LiDAR同步。每个融合数据对的目标检测推断时间约为250毫秒。优化框架,如NVIDIA的TenSORT [ 23,可能会大大减少推理时间。
图8.我们的图像边缘提取方法的可视化。(上)显示RGB图像,(中)显示应用于图像边缘的IDT + DE结果,(下)显示图像边缘与PC的拟合。
A.校准结果
使用IDT + DE进行边缘提取和后续边缘模糊环的结果如图8所示。校准算法成功收敛,对初始猜测中的误差具有鲁棒性。IDT + DE处理成功平滑了边缘图像中的梯度,产生了更平滑的相似度函数,优化器可以找到全局最大值。或者,可以为此目的使用高斯平滑,这种平滑精度较低,但速度更快。更多细节在图5中已有说明。
由于Kitti用于网络训练,因此有必要进行正确的外部校准。数据集包括外部校准,该校准是根据来自PC和图像[ 24的手动选择的点对应关系计算的。我们使用KITTI校准作为我们的初始猜测,运行我们的外部校准方法。表I显示了我们计算的挤出物与提供的KITTI挤出物的偏差。一般来说,传感器之间的外部校准没有基础事实。因此,我们无法提供绝对错误。然而,目视检查(见图9 )显示,我们的样品比Kitti提供的样品更准确。

表一非本征激光雷达相机的绝对差异
KITTI的校准参数和我们的方法
V.结论和今后的工作
在本研究中,我们改进了Levinson和Thron [ 8 ]的现有校准方法,以提高物体的检测和定位精度。我们通过使用LiDAR、IDT + DE和无梯度优化器的强度不连续性来估计旋转和平移参数,从而在许多方面进行了改进。融合LiDAR和照相机的高级目标列表的流行方法缺乏适当的外部校准,因此在融合数据中产生像差和振铃。我们的外部校准方法产生的结果比KITTI数据集的校准更准确,我们的融合实时运行、重量轻。我们对投影点云进行上采样,并使用不同的深度编码( HHA / JET )。我们展示了相机LiDAR部分的中低层融合RGB和深度数据的检测和分类结果。
我们的工作可以通过将雷达集成到融合管道中来扩展。我们目前正在遵循一种基于速度跟踪的激光雷达和雷达之间的外部校准方法。在LiDAR和雷达数据中,属于单个对象的测量值被聚类,然后基于估计/测量的速度相互关联。然后,对应关系产生变换矩阵的估计。这种方法中的几个步骤,LiDAR数据的跟踪、聚类和轮廓保持需要自动化和改进。
此外,我们预计使用即将推出的Flash LiDArs会带来更好的效果。Flash LiDArs将有助于消除补偿PC中许多基于自我运动的异常,也有助于传感器之间更好的时间同步。
REFERENCES
[1] M. Aeberhard and N. Kaempchen,“High-level sensor data fusion architecture for vehicle surround environmentperception,” in Proc. 8th Int. Workshop Intell. Transp, 2011.
[2] J.-r. Xue, D. Wang, S.-y. Du, D.-x. Cui,Y. Huang, and N.-n. Zheng,“A vision-centered multi-sensor fusing approach to self-localization andobstacle perception for robotic cars,” Frontiers of Information Technology& Electronic Engineering, vol. 18, no. 1, pp. 122–138,2017.
[3] J. Lu, H. Sibai, E. Fabry, and D. A.Forsyth, “NO need to worry about adversarial examples in object detection inautonomous vehicles,” CoRR, vol. abs/1707.03501, 2017. [Online]. Available:http://arxiv.org/abs/1707.03501
[4]“Velodyne64,”http://velodynelidar.com/lidar/products/manual/HDL64E\%20S3\%20manual.pdf,[Online; accessed Nov 15, 2017].
[5] “Continental radar user manual,” https://www.continental
automotive.com/getattachment/bffa64c8-8207-4883-9b5c-85316165824a/Radar[1]PLC-Manual-EN.pdf.aspx,[Online; accessed Nov 15, 2017].
[6] X. Chen, H. Ma, J. Wan, B. Li, and T.Xia, “Multi-view 3d object detection network for autonomous driving,” in IEEECVPR, 2017.
[7] A. Geiger, P. Lenz, and R. Urtasun,“Are we ready for autonomous driving? the kitti vision benchmark suite,” inComputer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE,2012,pp. 3354–3361.
[8] J. Levinson and S. Thrun, “Automaticonline calibration of cameras and lasers.” in Robotics: Science and Systems,2013, pp. 24–28.
[9] A. Geiger, F. Moosmann, . Car, and B.Schuster, “Automatic camera and range sensor calibration using a single shot,”in 2012 IEEE International Conference on Robotics and Automation, May 2012, pp.3936–3943.
[10] S. Ren, K. He, R. Girshick, and J.Sun, “Faster r-cnn: Towards real[1]timeobject detection with region proposal networks,” in Advances in neuralinformation processing systems, 2015, pp. 91–99.
[11] A. Dhall, K. Chelani, V.Radhakrishnan, and K. M. Krishna,“Lidar-camera calibration using 3d-3d point correspondences,” CoRR, vol.abs/1705.09785, 2017. [Online]. Available: http://arxiv.org/abs/ 1705.09785
[12] S. Garrido-Jurado, R. M. noz Salinas,F. Madrid-Cuevas, and M. Mar´ın-Jimenez, “Automatic generation and detection ofhighly ´ reliable fiducial markers under occlusion,” Pattern Recognition, vol.47, no. 6, pp. 2280 – 2292, 2014. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0031320314000235
[13] M. Velas, M. Spanel, Z. Materna, andA. Herout, “Calibration of rgb camera with velodyne lidar,” in Comm. PapersProc. International Conference on Computer Graphics, Visualization and ComputerVision (WSCG), 2014, pp. 135–144.
[14] N. Schneider, F. Piewak, C. Stiller,and U. Franke, “Regnet: Multimodal sensor registration using deep neuralnetworks,” CoRR, vol. abs/1707.03167, 2017. [Online]. Available:http://arxiv.org/abs/ 1707.03167
[15] J. Castorena, U. S. Kamilov, and P. T.Boufounos, “Autocalibration of lidar and optical cameras via edge alignment,”in 2016 IEEE International Conference on Acoustics, Speech and SignalProcessing (ICASSP), March 2016, pp. 2862–2866.
[16] A. Datta, J.-S. Kim, and T. Kanade,“Accurate camera calibration using iterative refinement of control points,” inComputer Vision Workshops (ICCVWorkshops), 2009 IEEE 12th International Conference on. IEEE, 2009, pp.1201–1208.
[17] Z. Zhang, “A flexible new techniquefor camera calibration,” IEEE Transactions on pattern analysis and machineintelligence, vol. 22, no. 11, pp. 1330–1334, 2000.
[18] M. J. Powell, “The bobyqa algorithmfor bound constrained op[1]timizationwithout derivatives,” Cambridge NA Report NA2009/06, University of Cambridge,Cambridge, 2009.
[19] C. Premebida, J. Carreira, J. Batista,and U. Nunes, “Pedestrian detection combining rgb and dense lidar data,” inIntelligent Robots and Systems (IROS 2014), 2014 IEEE/RSJ InternationalConference on. IEEE, 2014, pp. 4112–4117.
[20] A. Eitel, J. T. Springenberg, L.Spinello, M. Riedmiller, and W. Bur[1]gard,“Multimodal deep learning for robust rgb-d object recognition,” in IntelligentRobots and Systems (IROS), 2015 IEEE/RSJ Interna[1]tionalConference on. IEEE, 2015, pp. 681–687.
[21] S. Gupta, R. Girshick, P. Arbelaez,and J. Malik, “Learning rich ´ features from rgb-d images for object detectionand segmentation,” in European Conference on Computer Vision. Springer, 2014,pp. 345–360.
[22] Y. Wei, Y. Zhang, and Q. Yang,“Learning to transfer,” CoRR, vol. abs/1708.05629, 2017. [Online]. Available:http://arxiv.org/abs/1708. 05629
[23] “Nvidia tensorrt,”https://developer.nvidia.com/tensorrt, [Online; ac[1]cessedNov 15, 2017].
[24] A. Geiger, P. Lenz, C. Stiller, and R.Urtasun, “Vision meets robotics: The kitti dataset,” International Journal ofRobotics Research (IJRR), 2013.
[25] M. Everingham, L. Van Gool, C. K. I.Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc)challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp.303–338,Jun 2010. [Online]. Available: https://doi.org/10.1007/s11263-009-0275-4
-
自动驾驶
+关注
关注
783文章
13674浏览量
166096 -
LIDAR
+关注
关注
10文章
322浏览量
29348
原文标题:自动驾驶中相机和LiDAR数据融合方法与目标检测
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何将AXI VIP添加到Vivado工程中
Mentor PADS将PCB封装直接添加到PCB的教程

如何使用vhdl将这种东西添加到TEMAC上?
将新库添加到Petalinux rootfs的最简单方法是什么
如何将TDM业务添加到WiMAX平台上
如何将Crosswalk添加到Cordova应用程序中
Verizon将达拉斯和奥马哈添加到其5G组合中
如何将WizFi360 EVB Mini添加到树莓派Pico Python






 工商网监
工商网监
评论