 AI领域的研究论文是否应该公开代码?
AI领域的研究论文是否应该公开代码?
九月底,一篇CVPR论文由于“无法复现一致的结果”引发质疑,被要求撤稿。论文一作是CMU博士、来自中国的徐觉非同学,今天,他发表了详细分析和回应,并谈及他对公开代码、开放研究的看法。
AI领域的研究论文是否应该公开代码?这是一个长期以来争议不休的话题。
多数人认为,科学研究应该可以让其他研究人员在相同的条件下重现其结果。
在AI领域,事情更加明显:如果我们想要信任AI,就必须能够复现它。
而对于机器学习的研究来说,由于各种超参数对结果影响很大,并且论文里不太可能把所有实现的细节都说清楚,公布代码就成了保证复现的重要途径。
但是,如果代码开源了,复现论文的时候却发现结果和论文差异太大,怎么办?
这里有一个教科书般的案例。如果你对是否应该为了复现实验结果而开源代码有争议,非常值得一读。
事情是这样的:
9月底,Reddit上一篇帖子对CVPR 2018的一篇题为“Perturbative Neural Networks”的论文提出了质疑。质疑者名为Michael Klachko(以下简称MK),Reddit ID为p1esk,他表示,自己试图按照论文中的模型和方法重现实验结果,结果并没有达到文中声称的准确率。MK认为,原文中的计算存在错误,并直截了当地表示,这篇文章也许应该被撤稿。
由于CVPR在AI研究领域的地位,此贴一发,顿时引发众多网友热议。
这篇论文来自CMU的Felix Juefei-Xu和Marios Savvides,以及密歇根州立大学的 Vishnu Naresh Boddeti三人。
其中,第一作者Felix Juefei-Xu(徐觉非)来自中国,本科毕业于上海交通大学电子工程专业,在CMU获得电子与计算机工程硕士和博士学位。在CMU读博期间,徐觉非师从Marios Savvides教授,在CMU CyLab生物特征识别中心研究模式识别、机器学习、计算机视觉和图像处理等领域,特别是这些领域在生物识别中的应用。
徐觉非的主页
徐觉非当时表示,他们将彻底分析问题,并且得到 100% 确定的结果之后再给出进一步的回复。 他说:“我们正在重新运行所有的实验。如果分析表明我们的结果确实跟提交 CVPR 的版本中相差很多,会撤回这篇论文。”
现在,结果来了。在介绍徐觉非的详细回复之前,让我们先简要看看这篇论文的主要内容和争议的焦点。
复现结果不一致,CVPR论文引撤稿争议
从这篇论文的内容来看,作者提出了一个简单有效的模块,名为“干扰层”(perturbation layer),作为卷积层的替代。干扰层不使用传统意义上的卷积,而是将其响应计算为一个线性加权和,由增加的噪音干扰输入的非线性激活组成。作者表明,由这些“干扰层”组成的干扰神经网络(PNN)的性能和CNN一样好。
而提出撤稿质疑的MK则表示,使用3X3卷积换成1X1再在输入中增加一些干扰,实际上并没有什么意义。他的测试结果是这样的:
在关于学术论文的讨论中,被人质疑是否应该撤稿,可以说是非常直接的指控了。此贴一经发出,立即引发了网友关于“是否应该撤稿”的讨论。
当时,网友的观点大致分为以下几类:
1、不用撤,既然作者都把代码公开了,显然是无心之过,只要将错误改过来就好了。
2、 撤!有错误当然撤,不仅如此,以后还应该规定所有论文提交时都必须公开代码,不仅论文要评审,连代码也要一并审核。
3、先把撤稿的事放在一边:双盲评审过程本身并不涉及代码的审核,就好像生物学领域的论文不会在审稿期间去重复实验,也无法做到一一核查代码,原本就是论文发表后,由其他同行来复现,由此判断其结论是否经得起科学论证。
时隔两个月,作者再发详细澄清帖,获网友一边倒支持
合理归合理,但说到底,此事终究悬而未决。近两个月过去,11月25日,此文第一作者Felix Juefei-Xu(ID:katanaxu)在Reddit上再次发帖更新情况,详细说明了质疑者MK的实现方法和原文中方法的差异,并表示,这些差异是造成精度下降的主要原因。
徐觉非表示,经比较,MK的实现方式与原论文中的实现方式并不一致,主要体现在六个方面,分别为:
优化方法、添加的噪音水平、学习率、学习率schedule、Conv-BN-ReLU module ordering、以及对Dropout的使用。
此次徐同学的回应要比9月份那次具体得多,并在自己的Github上贴出了详细的比较结果。与两个月前网友舆论基本势均力敌相比,此次网友基本对原作者表示了一边倒的支持。
比如,一位id为“nnatlab”在引用了作者的澄清内容后,对质疑者MK表示,在正式发表质疑言论之前,应该反复确认实现方式。作者列出的都是导致结果不一致的重要因素。这种情况下直接发出“应该撤稿”的质疑显然不够成熟,也不够专业。
也有网友认为,在事情还未定论的情况下就抛出“撤稿”这样刺眼的字眼显然不合适。科学研究需要时间和精力,对研究成果提出质疑,也应该给予研究者充分的回应时间。
绝大部分网友认为作者的此次回应有理有力,甚至有人表示,“可以祝贺原作者了”。
质疑者“MK”再现身:现在下结论仍为时尚早
凡事有来必有往。两个月前发出质疑帖子的MK在本帖现身回复,他在回复中对自己和作者的沟通情况作了简要说明,表示自己现在正忙着准备12月的另一篇论文,等忙完了将再次对PNN进行测试。在回复中,MK对自己的两个月前的质疑作出了四点澄清:
1.我在原贴中发布的PNN准确率下降了5%的结果,其资源来自作者给出的资源库,所有原始超参数都未经修改。我只改变了测试精度的量度。
2、我真的很愿意相信,原作者找到了神奇的解决办法,因为这样我就可以证明能够以这个方法进行硬件实现(并发表一篇论文)。但是:
3、在有人(我自己或第三方)成功运行新代码,并确认主要结果之前(即PNN可以获得与CNN相当的表现)之前,对原作者表示祝贺还为时尚早。我建议这个论坛的人自己去做这个比较。不必像我一样重新实现,只需验证一切都可以按照论文中的步骤顺利完成就行。
4、如果PNN确实像此文声称的那样强大,这可是件大事。目前,卷积神经网络(CNN)是深度学习的核心,如果我们真的不再需要使用sliding shared filters从输入中提取出模式,那么此文作者就发现了一些非常有趣的东西,并找到了处理信息的开创性的新方式。这个发现可能与Hinton的胶囊网络一样新颖和重要。
看得出,面对原作者的详细说明和网友的舆论压力,MK仍然在坚持自己的观点。
论文一作的详细回应
第1节:Michael Klachko的实现设置不一致
根据我们的分析,所谓的性能下降(~5%)主要是由于Michael Klachko(以下简称MK)在PNN的实现中存在各种不一致和次优的超参数选择。
在次优的设置和超参数选择下,MK的实现在CIFAR-10上的结果是~85-86%,性能下降了5%,如下面的repo快照所示。
将MK的实现与我们的进行比较,可以发现以下不一致之处:
优化方法不同:MK采用SGD,我们采用Adam。
附加噪声水平不同:MK使用0.5,我们使用0.1。
学习率不同:MK使用的学习率是1e-3,我们使用1e-4。
learning rate scheduling不同(见文末链接)。
Conv-BN-ReLU模块顺序不同见文末链接)。
dropout的使用不同:MK使用0.5,我们使用None。
如下图所示,存在诸多不一致。MK的实现是左边,我们的是右边。

基于我们有限的试验次数,我们发现在这些不一致性中,前两个(优化方法和噪声水平)对PNN的性能影响最大。优化方法的选择确实非常重要,在小规模的实验中,每一种优化方法(SGD、Adam、RMSProp等)的遍历方式都有很大的不同。添加噪声水平的选择也非常重要,我们将在第3节中再次讨论。
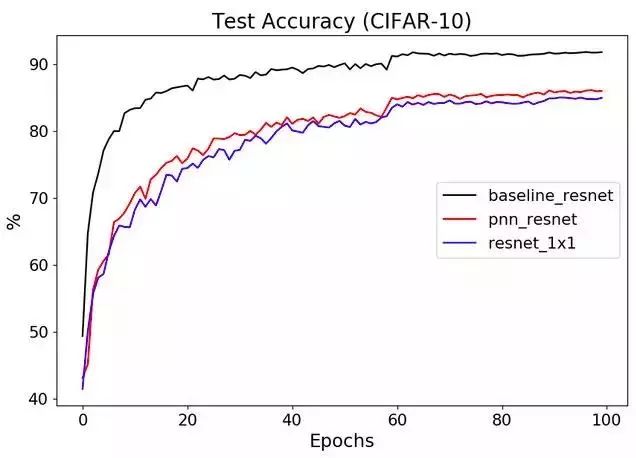
那么,让我们看看PNN在正确地设置超参数后是如何执行的。保持相同数量的噪声掩码(——nfilters 128),我们可以达到90.35%的准确率,而MK在他的repo中报告的准确率只有85-86%。
python main.py --net-type 'noiseresnet18' --dataset-test 'CIFAR10' --dataset-train 'CIFAR10' --nfilters 128 --batch-size 10 --learning-rate 1e-4 --first_filter_size 3 --level 0.1 --optim-method Adam --nepochs 450
第2节:关于CVPR论文结果
目前,对CVPR实验的重新评估已经基本完成。有一小部分实验受到平滑函数中错误的默认标志的影响。对于那些受影响的,性能会有小幅下降,可以通过增加网络参数来补偿。我们将在PNN论文的arxiv版本中更新结果。
第3节:所有层中的Uniform Additive Noise
接下来要讨论的内容,我们在CVPR论文中并没有涉及,而是打算在PNN的后续工作中进一步探讨。其中一个主题是在所有层应用扰动噪声(perturbative noise),包括第一层。
在CVPR论文中,我们在第一层使用3x3或7x7空间卷积作为特征提取,所有后续层使用扰动噪声模块。由于MK已经尝试并实现了PNN的all-layer perturbative noise版本,我们认为提供我们的见解也有帮助。
根据MK的repo(如下图所示),所有层(包括第一层)均匀噪声的PNN在CIFAR-10上的准确率为72.6%。在这里,我们提供了一个简单的解决方案(与MK的实现没有太大变化),可以达到~85-86%的准确率。不过,这仍然是许多正在进行的关于PNN的研究课题之一,我们将在后续的工作中进一步报告结果。
我们从class PerturbLayerFirst(n.module)中创建了一个名为class PerturbLayerFirst(n.module)的重复类,以便将第一层噪声模块与其他层的噪声模块区别开来。大部分修改发生在class PerturbLayerFirst(nn.Module)和class PerturbResNet(nn.Module)中。
修改的主要想法是:
我们需要更多noise masks。使用3个高度相关(RGB通道)的基本图像来创建128或256个噪声扰动响应映射是远远不够的。
噪声水平的选择是次优的,需要针对第一层进行放大。在MK的实现中,第一层输入和后续层的归一化是不同的,动态范围也有很大的不同。
因此,经过修改后,具有全层噪声扰动模块的PNN准确率可以达到85.92%,而MK在repo中报告的准确率为72.6%。
python main.py --net-type 'perturb_resnet18' --dataset-test 'CIFAR10' --dataset-train 'CIFAR10' --nfilters 256 --batch-size 20 --learning-rate 1e-4 --first_filter_size 0 --filter_size 0 --nmasks 1 --level 0.1 --optim-method Adam --nepochs 450
第4节:为什么PNN有意义?
在攻读博士学位的最后一年,我投入了一些探索深度学习新方法的研究工作,这些方法在统计学上是有效的,同时也具有稳健性。这一系列研究始于我们在CVPR 2017发表的Local Binary Convolutional Neural Networks (LBCNN)论文。在LBCNN论文中,我们试图回答这个问题:我们真的需要可学习的空间卷积吗?事实证明,并不需要。使用 binary或Gaussian filters + learnable channel pooling的Non-learnable随机卷积也可以。接着,下一个自然而来的问题是:我们真的需要空间卷积吗?也许另一种特征提取技术(例如additive noise)+ learnable channel pooling也能起到同样的作用?这就是PNN论文试图阐明的问题。
learnable channel pooling和non-learnable convolutional filters两者的混合让我们得以重新思考卷积滤波器在深度CNN模型中的作用。通过各种视觉分类任务,我发现了LBCNN和CNN之间具有可比性。
基于这些观察,一种自然而然的方法就是完全取代随机卷积运算。在每个local patch中,由于它是一个线性操作,涉及中心像素的邻域和一组通过点积创建标量输出的随机滤波器权重,该标量输出携带局部信息,即,将中心像素映射到响应图中相应的输出像素。那么,可以替代的最简单的线性操作就是添加随机噪声(additive random noise)。
这就是PNN的动机所在,我在其中介绍了一个非常简单但有效的模块,称为扰动层(perturbation layer),作为卷积层的替代。
我们在LBCNN工作中的经验表明,通过随机卷积的随机特征提取和深度神经网络中的learnable channel pooling结合,可以学习有效的图像特征。PNN中的加性随机噪声是一种最简单的随机特征提取方法。
第5节:结语
当我写完这篇文章时,我不禁回想起过去两个月的经历。我不得不承认,当MK决定在Reddit上公开质疑时,我有点震惊,尤其是我已经答应会调查这个问题了。一周之内,这篇文章引起了中国多家主流科技/人工智能媒体的关注。这个帖子在中国社交媒体上被分享,包括讨论这一问题的报道文章,点击量超过了100万。有些文章和评论很苛刻,但有些是合理和公正的。虽然我很坚强,但不能说我没有受到压力。
但我开始意识到一件事情:作为一名研究人员,面对公众的审视不是一种选择,而是一种责任。为此,我真的要感谢Michael,他不仅花费了时间和精力来重新创建和验证一个已发布的方法,更重要的是,在发现结果不匹配时说出来。我坚信,正是通过这些努力,我们整个研究社区才能取得真正的进展。
此外,我想对刚刚进入AI领域的年轻研究人员或即将进入AI领域的大学生(以及高中生!)说几句话。这样的事情确实会发生,但是你永远不应对开放源代码或进行开放研究感到气馁。这是AI领域发展如此迅速的核心原因。我在最近回国的旅途中,遇到了一位高三学生,他非常热情的和我讨论了Batch Normalization和Group Normalization的实施细节。我真的很惊讶。对于所有年轻的AI研究人员和从业人员,我真诚地鼓励你们打破常规思考,不要停留在教条上,探索尚未被探索的东西,走少有人走的路,最重要的是,做开放的研究,分享你们的代码和发现。这样,你就是在帮助社区向前发展,即使每次只前进一英寸。
所以,让我们继续探索、研究和分享。
-
AI
+关注
关注
87文章
30898浏览量
269130 -
代码
+关注
关注
30文章
4788浏览量
68625 -
机器学习
+关注
关注
66文章
8418浏览量
132655
原文标题:CVPR 18论文“无法重现”?中国作者再度澄清获网友一边倒支持
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
RISC-V在AI领域的发展前景怎么样?
AI大模型的最新研究进展

AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
生成式AI在学术领域的应用亟需高度重视
在NodeMCU上公开强制休眠API,无法让定时light_sleep工作怎么解决?
探讨AI编写代码技术,以及提高代码质量的关键:静态代码分析工具Perforce Helix QAC & Klocwork
助力科学发展,NVIDIA AI加速HPC研究






 工商网监
工商网监
评论