 基于部分可观察马尔可夫决策过程思考自然语言处理和强化学习问题的一些想法
基于部分可观察马尔可夫决策过程思考自然语言处理和强化学习问题的一些想法
【编者按】Microsoft Semantic Machines资深研究科学家、UC Berkeley计算机科学博士Jacob Andreas讨论了基于部分可观察马尔可夫决策过程思考自然语言处理和强化学习问题的一些想法。
AI研究应该操心话语含义的明确表示吗?我这里说的“含义的明确表示”指具备预定义的解释的结构化变量——语义学家关心的那类事情。长期以来,这样的含义表示一直是将语义与其他任务连接起来的成功努力的中心,这些任务涉及推理、感知、行动(从SHRDLU到现代语义解析器)。另外,长期以来,结构化的含义表示同时也是一些不成功的工作的中心,这些工作包括机器翻译、句法等。这种表示使用了许多不同的表示形式化系统——新戴维森逻辑形式(AZ13),组合子逻辑(LJK11),其他非逻辑结构(TK+11)——不过,从某种角度上来说,它们基本上都属于基于预测-论据结构实现的模型-理论语义,也许预言主体有几个自由变量。
这类方法看起来正在消失。现在所有一切都是端到端的,接受手工设计的逻辑语言的值,带有这样的显式潜变量的模型非常罕见。话语传入模型,模型产生行为,我们并不怎么操心中间进行的运算的结构。从某种标准上来说,这是一件好事:在更形式化的方法中,机器学习和表示的紧密耦合意味着,数据中出现新的语义现象导致模型突然变得无用的风险始终存在。足够一般的学习表示的机制(非逻辑)让这一风险不那么可怕了。当然,在旧模型中毫不费力就能得到的一些特定种类的概括和归纳偏置,我们尚未完全搞清楚如何重建。不过,结构化正则器(OS+17)和我们的NMN工作(AR+16)这样的混合方法的成功,暗示我们将逐渐达到这一步。
但是端到端世界的态度看起来是,既然我们不再进行逻辑推理,那么我们完全没有必要考虑含义。突然之间,所有人都喜欢称引维特根斯坦,主张我们应该以下游任务的成功来评估“语言理解”,而不是通过预测正确的逻辑形式(WLM16、GM16、LPB16)——这很棒!——但是这背后似乎有这么一种哲学:“含义即使用,所以如果我们能以很高的精确度预测使用,那么我们就已经理解了我们需要理解的关于含义的一切”。特别是考虑到我们实际上并没有解决“使用”,我认为机器学习在等式的含义这边有很多需要学、需要说的。而且我从不认为这是维特根斯坦《哲学研究》中的主张——就算使用(而不是指代)是我们应该尝试解释的主要内容,《哲学研究》则对依据哪种语言使用是可能的判断~~心智表示~~过程表示特别感兴趣。
本文的主张是,p(世界状态|话语)形式的信念状态的明确表示,适合作为“非结构”机器学习模型的含义表示。这类表示很自然地源于社区最近热衷的决策任务,但也和语言学的经典表示理论很像。这一综合暗示了同时训练和解释语言处理模型的道路。
信念状态和内涵
考虑这样一个问题,在部分观察的世界中,通过和人们交谈降低不确定性,决定如何行动。你应该如何选择应该采取的最佳行动?给定单一话语w,可能真实的世界状态x,就某风险函数R而言,最小化贝叶斯风险的行动为:
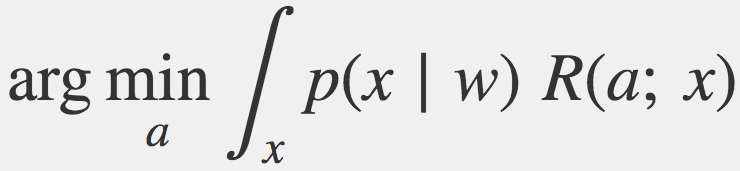
任何希望在这个世界成功的听话人需要至少成功地逼近这一优化问题的解,在实践中,听话人大概需要表示分布p(x|w),至少隐式地表示。在POMDP中,我们称p(x|w)为信念状态;对一给定w而言,这是一个映射可能世界x至变量可信度判断的函数——给定我们观察到某人说了w这一事实,x是真实世界的可能性有多大?
和蒙塔古语义学中的内涵概念对比一下:“映射可能世界和时刻至真值的函数”(J11)。大多数(模型-理论)语义程序使用逻辑表达式(而不是表格)表示内涵。但逻辑形式只不过是表达类型正确的函数的一种方式;在蒙塔古传统下,“含义的明确表示”正是内涵——类似p(x|w)的离散版。
信念状态是包含概率的内涵。含义的内涵表示很有用,不仅是因为它们有助于解决语言学问题,还因为它们逼近一个量,我们知道,这个量有助于语言使用者利用从语言中获取的信息进行有用之事。另一方面,POMDP告诉我们,我们需要在听到话语后进行的计算,差不多是语言学家至始自终告诉我们需要计算的东西。或者,几乎就是语言学习家已经告诉我们的东西——比起回答p(x|w)请求的黑箱,如果是带一点结构的东西就更好了,也许是某种分解表示,让我们可以通过检查所有可信世界共有的一组属性高效地找出MBR行动。也许是关于个体的断言、他们的性质、他们之间的关系……等的乘积。要是逻辑语义学不存在的话,我们将不得不发明它。
准确地说,作为“含义”的p(x|w)应该理解为听话人含义:已经计入格莱斯说话人含义类型效应(寓意)以及说话人也许不想让听话人进行的进一步推理(例如,w是谎言的概率)的精确信念状态。我们这里不在乎p(x|w)来自何处,所以也许可以通过RSA之类的技术计算(使用不同的内嵌句含义概念)(FG12)。
最后一项调整:现实世界听话人并不从白板开始:所有话语都基于现存信念状态p(x)的上下文进行解读,与其将句子的含义直接视作p(x|w),不如将其视作一个更新函数p(x) ↦ p(x∣w)。就“Pat loves Lou”这样的句子而言,我想这一更新基本上一直是连续的;即p(x) ↦ (1/Z)⋅p(x)⋅p(x∣w). 但要处理指示词和Quine问题中bachelor的含义(译者注:bachelor既可以指学士,也可以指单身汉),我们需要更新函数的一般版本。
实际影响
这些都很好,不过我们注意到明确指称含义表示(逻辑、概率或其他形式)并没有在实践中表现良好的那些模型中得到应用。所以这有什么可在意的?
语言理解系统要想工作良好,必定选择了类似最小贝叶斯风险的行动。奥妙在于:深度网络的后缀是一个通过固定回路转换输入表示至输出行动的函数;如果这个后缀可以为每个输入表示选择良好的行动,那么它实际上实现了类似MBR解码算法的东西(尽管也许只是逼近,同时在表示的经验分布上特化);呈现给这一部分网络的语言上下文表示必须足以解决优化问题,所以会是类似p(x|w)表示的东西。
这不是一个很好的论据:模型的“句子表示”和“优化”部分之间可能实际上没有明显的界限。但在实践中,我们确实看到了含义类的句子表示出现(特别是在句子表示独立于听话人具备的关于世界状态的初始信息计算的模型中(DP+18))。当在较大规模网络中使用专门化的优化模块时(TW+17、LFK18),我们可以很明确地看到两者的差别。
在任何情形下,我们模型的某种中间表示解码(或应该能解码)知识为世界状态分布,并为我们提供了两种工具:
可解释性:通过估计p(x|rep(w))可以测试表示是否捕捉了正确的语义(或者识别表示捕捉了什么奇异的不规则性),其中rep(w)是模型学习到的话语w的表示。判断这是否对应于w的真实(即人类听话人的)指称。我们发表的一些论文(ADK17、AK17)在这一技术上取得了一些进展。我们组的其他一些学生使用这一技术分析遵循指令的模型的预训练方案。不过,某种程度上,应用这一技术学习自然语言自身的表示要比应用于学习到的消息/抽象行动的空间更加自然。
辅助目标:指令遵循/QA问题的一般目标是p(行动|话语, 听话人观测)。不过,如果碰到了过拟合问题,在说话人观测可用的情况下,可以直接加上一项p(说话人观测, 听话人观测|话语)。对某些问题而言(例如GeoQuery类的语义解析),在“说话人观测”和“行动”之间不存在有意义的差别;对另一些问题而言,这看起来像是完全不同的学习问题。在指代表达任务中,指称辅助问题是“生成/获取图像对,在这一对对图像之间,这将是不同的描述”;在指令遵循模型中,它是“生成目标状态(但未必是能让我到达那里的行动)”。
结语
在语言任务中思考POMDP风格的解答,我们得到了疑似模型-理论语义学中的含义的描述。这一类比提供了解释学习到的模型的工具,并暗示了提升模型精确度的辅助目标。
-
强化学习
+关注
关注
4文章
266浏览量
11234 -
自然语言处理
+关注
关注
1文章
618浏览量
13541
原文标题:AI研究应该关注语含义的明确表示吗?
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤
ASR与自然语言处理的结合
自然语言处理与机器学习的区别
使用LLM进行自然语言处理的优缺点
【《大语言模型应用指南》阅读体验】+ 基础篇
图像识别技术包括自然语言处理吗
nlp自然语言处理模型有哪些
自然语言处理模式的优点
自然语言处理是什么技术的一种应用
自然语言处理包括哪些内容
什么是自然语言处理 (NLP)
自然语言处理技术的原理的应用
神经网络在自然语言处理中的应用
通过强化学习策略进行特征选择






 工商网监
工商网监
评论