 如何用机器学习解决数据库运维难题
如何用机器学习解决数据库运维难题
回顾整个运维的发展史,从最开始的系统管理到基础脚本运维,再到自动化运维,最后发展到了智能运维。经过这些年的发展,运维人员的工作内容发生了翻天覆地的变化:
十几年前,我们不知道故障会出现在哪,也不知道什么时候会出现故障,只有在故障出现的时候才能去查找根因并解决故障,这是一种很被动的方法。
到后来大规模的脚本引入,我们处理问题的方式变得更加科学了,速度也差强人意,但还是没有改变这一种被动解决问题的本质现象;有了先前的经验,很多公司引入了监控系统,发展了自己的自动化运维平台,旨在问题发生或者即将发生时能够自动地去解决问题,这种方式刚突破了之前所有的“被动运维”的本质,能够防患于未然,将故障扼杀在摇篮中。但与之而来的却是大量的告警及海量的监控数据,如何更加高效地解决故障成了我们现在必须解决的难题。
人工智能时代的来临恰好解决了上面我们所面临的问题,而AIOps就是希望基于已有的运维数据(日志、监控信息、应用信息等),并通过机器学习的方式来进一步解决自动化运维没办法解决的问题。
我们目前正在积极推动数据库运维从自动化到智能化的转变。众所周知,数据挖掘和机器学习离不开海量的数据作为基础,而平安科技通过这几年的自动化运维的应用,已经积累了海量多维的数据库性能数据、日志数据和主机数据。
利用这些数据,我们可以通过机器学习等方法在时间序列异常检测、根因分析、邮件告警收敛、容量预测等多个应用场景中获取我们想要的信息,从而进行故障的自动发现、自动诊断和自动解决。
一、时间序列异常检测
时序数据是AIOps的基础数据,有着规模大、种类多、需求多样的特点。在自动化运维阶段,我们所采用的大多是恒定阈值的方法。
这种方法简单易实现,但是缺点也显而易见:它不够灵活,发现故障也不够及时,无法满足现在的告警需求。如下图所示,传统的阈值告警会忽略掉两个波动的异常:
恒定阈值方法
动态阈值的方法在此时应运而生,传统的动态阈值的方法采用了基于同比和环比的统计方法,这种方法解释性强,易于实现,但是灵活性较差,受节假日影响较大(如下图中,9月24号为中秋节,流量和上周相比下降明显,此时环比和同比的方法不适用),发现问题也不够及时。
还有许多公司采用带权移动平均的方法来做动态阈值,他们认为在同一个维度下,某一个点的数值必然和它之前一段时间的数据有关,如以下公式所示:
9/18-9/25指标数据图
我们目前正将机器学习应用在时序数据异常检测中,和上述方法相比,机器学习的方法更为准确,成本也更大。
时间序列异常检测本质上也可以看做“正常”和“异常”的二分类问题,通过将历史的监控数据打上标签,再将有监督和无监督算法结合建立模型,可以判断当前的时间序列是否是正常的。
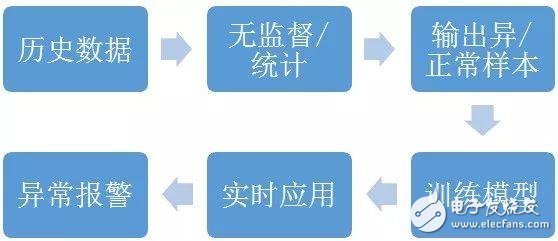
二、根因分析
大多数情况下,由于监控指标的相关联性,如果某个指标异常了,很多相关指标也会异常。如果同时对所有的告警指标进行分析和处理,会浪费许多人力。为了解决这个问题,我们需要进行根因分析来进行针对性处理。
通常我们可以通过下列3种方法对数据进行根因分析:
相关度指标获取,找到和异常指标在特定时间段内相似的指标。
在大量的样本中,找出经常一起出现的异常指标(该问题就转换成了频繁序列挖掘问题),实现方法有关联规则、APRIORI、FP_GROTH等。
利用决策树的强可解释性,对正负样本进行分类,然后通过异常指标的分类树途径,找到频繁的异常指标集。
第一种方法找出当前时间段内与DB_TIME指标有相似曲线的指标,并将最相似指标TOP N作为根因;
第二种方法则是在历史数据中,当DB_TIME异常时,把其他异常的指标组成若干个项集,再从这些项集里面利用关联规则找出强相关组合,则这些组合中的其他指标被视为根因;
第三种方法,则是在历史数据中根据DB_TIME是否异常,将历史数据分为正、负样本,训练决策树模型得到最终的根因。
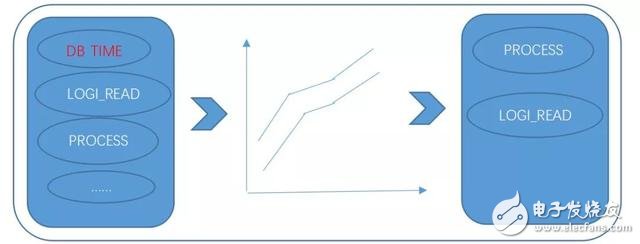
根因分析方法一
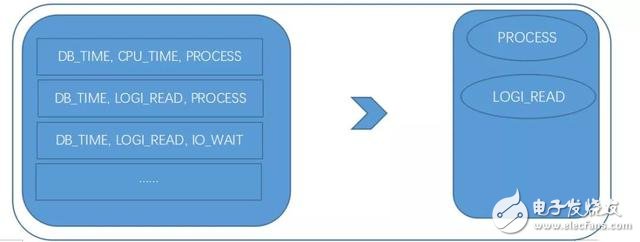
根因分析方法二
根因分析方法三
三、告警收敛
当监控业务发展到一定规模时,每日收到的告警邮件数会呈指数型增长,尤其是一些监控频率较高的监控项出现问题时,这种情况特别明显。
为了解决这一问题,在最开始,我们设定了告警频率,让同一种告警在一段时间内只出现一次。
这种方法确实会减少一部分告警,但是还有一些显而易见的告警可以通过制定规则的方法来实现进一步的告警收敛。比如同一个集群内的数据库都出现了ping不通的问题,又比如同一个网段内的所有IP流量突增,就可以将这些告警整合后再发送。
而在AIOps时代,告警收敛和根因分析往往是一起进行的。
和根因分析方法二类似,我们可以先获取告警项集数据,并提取频繁项。如果在频繁告警项集中,告警A和告警B经常一起出现并且在A出现的时间比B早,则在邮件告警中,我们可以忽略B告警,只将A告警推送给运维人员。
不同场景下的告警收敛有着不同的需求,和AIOps相比,传统的告警收敛方法更加简单和高效,基于规则的方法也具有很强的拓展性和解释性;而AIOps却能挖掘出我们利用常识和经验无法发现的关联项并进行告警收敛。
四、容量预测
容量预测在数据库运维中的很多地方都应用着,不同的应用场景有不同的特性,我们很难找到一个模型去适应所有的数据。
在容量预测上,我们的典型应用是数据库DB_SIZE容量预测,数据库容量具有总体上升、无规律、波动大的特点。对数据库容量进行合理的预测,短期可以提前发现可能的故障,进行主动预防和提前解决,无需在问题发生时被动处理;长期可以进行合理的容量规划和资源分配。
最开始,我们想到的是线性回归加上简单的数据预处理,但是结果十分不理想。由于业务规模的落差,不同数据库的容量有着很大的差别,并且在数据库进行导表,扩容等操作时,线性拟合或者非线性拟合的效果不尽人意。
显然,传统的线性回归方法虽然简单,但是预测效果较差,不能满足要求。为了解决这一问题,我们将容量数据进行了分类,分为周期型和突升突降型,分类的方法可以采用统计方法,也可以使用聚类或分类的方法。
对于周期型数据,我们可以认为其实线性可拟合的,因为在总体上升的趋势上,周期型的数据在周期内的增长值是线性递增的。对于这种类型的数据,我们可以采用线性回归的机器学习方法来对数据库容量进行预测。
周期型数据
而对于突增突降型的数据,线性拟合效果较差,这时我们使用环比增量求和的方法,求得历史数据中星期一到星期天的具体每天增量的加权平均值;再将这个增量应用到预测中。和单纯的线性拟合方法相比,这种方法的准确性提高了很多,平均预测数据的均方残差缩小了近一倍。
突升突降型数据
以上四个应用场景的技术开拓都是致力于通过AI让运维更加高效,让更多的故障可以被提前发现和解决。关于AIOps,我们还有很多东西可以去尝试和探索,如智能问答机器人、日志集中分析平台等,后续有相关成果再与大家分享。
-
数据库
+关注
关注
7文章
3782浏览量
64335 -
机器学习
+关注
关注
66文章
8397浏览量
132518 -
运维
+关注
关注
1文章
254浏览量
7558
发布评论请先 登录
相关推荐
请教如何用SQL语句来压缩ACCESS数据库
请问查询sql数据库的表格结果都是升序排列的,如何用降序排列?二维数组排列也只能升序?
学习Linux运维发展方向
跨平台嵌入式数据库EffiProz介绍
ADO 控件访问数据库的各种技巧探讨
数据库,数据库是什么意思
SQL Server数据库学习总结
MySQL数据库误删后的回复技巧

数据库学习教程之数据库的发展状况如何数据库有什么新发展





 工商网监
工商网监
评论