 如何使用显式核方法改进线性模型
如何使用显式核方法改进线性模型
本文使用tf.contrib.learn(TensorFlow 的高阶机器学习 API)Estimator 构建我们的机器学习模型。如果您不熟悉此 API,不妨通过Estimator 指南着手了解。我们将使用 MNIST 数据集。本文包含以下步骤:
加载和准备 MNIST 数据,以用于分类
构建一个简单的线性模型,训练该模型,并用评估数据对其进行评估
将线性模型替换为核化线性模型,重新训练它,并重新进行评估
加载和准备用于分类的 MNIST 数据
运行以下实用程序命令,以加载 MNIST 数据集:
data = tf.contrib.learn.datasets.mnist.load_mnist()
上述方法会加载整个 MNIST 数据集(包含 7 万个样本),然后将数据集拆分为训练数据(5.5 万)、验证数据(5 千)和测试数据(1 万)。拆分的每个数据集均包含一个图像 NumPy 数组(形状为 [sample_size, 784])以及一个标签 NumPy 数组(形状为 [sample_size, 1])。在本文中,我们仅分别使用训练数据和验证数据训练和评估模型。
要将数据馈送到tf.contrib.learn Estimator,将数据转换为张量会很有帮助。为此,我们将使用input function 将操作添加到 TensorFlow 图,该图在执行时会创建要在下游使用的小批次张量。有关输入函数的更多背景知识,请参阅输入函数这一部分(https://tensorflow.google.cn/guide/premade_estimators?hl=zh-CN#create_input_functions)。在本示例中,我们不仅会将 NumPy 数组转换为张量,还将使用tf.train.shuffle_batch操作指定 batch_size 以及是否在每次执行 input_fn 操作时都对输入进行随机化处理(在训练期间,随机化处理通常会加快收敛速度)。以下代码段是加载和准备数据的完整代码。在本示例中,我们使用大小为 256 的小批次数据集进行训练,并使用整个样本(5 千个条目)进行评估。您可以随意尝试不同的批次大小。
import numpy as npimport tensorflow as tfdef get_input_fn(dataset_split, batch_size, capacity=10000, min_after_dequeue=3000): def _input_fn(): images_batch, labels_batch = tf.train.shuffle_batch( tensors=[dataset_split.images, dataset_split.labels.astype(np.int32)], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue, enqueue_many=True, num_threads=4) features_map = {'images': images_batch} return features_map, labels_batch return _input_fndata = tf.contrib.learn.datasets.mnist.load_mnist()train_input_fn = get_input_fn(data.train, batch_size=256)eval_input_fn = get_input_fn(data.validation, batch_size=5000)
训练一个简单的线性模型
现在,我们可以使用 MNIST 数据集训练一个线性模型。我们将使用tf.contrib.learn.LinearClassifierEstimator,并用 10 个类别表示 10 个数字。输入特征会形成一个 784 维密集向量,指定方式如下:
image_column = tf.contrib.layers.real_valued_column('images', dimension=784)
用于构建、训练和评估 LinearClassifier Estimator 的完整代码如下所示:
import time# Specify the feature(s) to be used by the estimator.image_column = tf.contrib.layers.real_valued_column('images', dimension=784)estimator = tf.contrib.learn.LinearClassifier(feature_columns=[image_column], n_classes=10)# Train.start = time.time()estimator.fit(input_fn=train_input_fn, steps=2000)end = time.time()print('Elapsed time: {} seconds'.format(end - start))# Evaluate and report metrics.eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1)print(eval_metrics)
下表总结了使用评估数据评估的结果。

注意:指标会因各种因素而异。
除了调整(训练)批次大小和训练步数之外,您还可以微调一些其他参数。例如,您可以更改用于最小化损失的优化方法,只需明确从可用优化器集合中选择其他优化器即可。例如,以下代码构建的 LinearClassifier Estimator 使用了 Follow-The-Regularized-Leader (FTRL) 优化策略,并采用特定的学习速率和 L2 正则化。
optimizer = tf.train.FtrlOptimizer(learning_rate=5.0, l2_regularization_strength=1.0)estimator = tf.contrib.learn.LinearClassifier( feature_columns=[image_column], n_classes=10, optimizer=optimizer)
无论参数的值如何,线性模型可在此数据集上实现的准确率上限约为93%。
结合使用显式核映射和线性模型
线性模型在 MNIST 数据集上的错误率相对较高(约 7%)表明输入数据不是可线性分隔的。我们将使用显式核映射减少分类错误。
直觉:大概的原理是,使用非线性映射将输入空间转换为其他特征空间(可能是更高维度的空间,其中转换的特征几乎是可线性分隔的),然后对映射的特征应用线性模型。如下图所示:
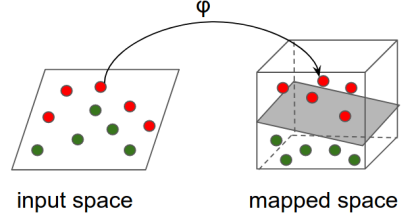
技术详情
在本示例中,我们将使用 Rahimi 和 Recht 所著的论文 “Random Features for Large-Scale Kernel Machines”(大型核机器的随机特征)中介绍的随机傅里叶特征来映射输入数据。随机傅里叶特征通过以下映射将向量x∈Rd 映射到x′∈RD
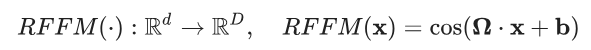
其中,Ω∈RD×d、x∈Rd,b∈RD和余弦值会应用到元素级别。
在本示例中,Ω和b条目是从分布中采样的,使映射符合以下特性:
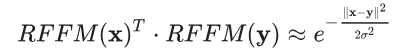
上述表达式右侧的量也称为 RBF(或高斯)核函数。此函数是机器学习中使用最广泛的核函数之一,可隐式衡量比原始空间维度高得多的其他空间中的相似性。要了解详情,请参阅径向基函数核(https://en.wikipedia.org/wiki/Radial_basis_function_kernel)。
核分类器
tf.contrib.kernel_methods.KernelLinearClassifier是预封装的tf.contrib.learnEstimator,集显式核映射和线性模型的强大功能于一身。其构造函数与 LinearClassifier Estimator 的构造函数几乎完全相同,但前者还可以指定要应用到分类器使用的每个特征的一系列显式核映射。以下代码段演示了如何将 LinearClassifier 替换为 KernelLinearClassifier。
# Specify the feature(s) to be used by the estimator. This is identical to the# code used for the LinearClassifier.image_column = tf.contrib.layers.real_valued_column('images', dimension=784)optimizer = tf.train.FtrlOptimizer( learning_rate=50.0, l2_regularization_strength=0.001)kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper( input_dim=784, output_dim=2000, stddev=5.0, name='rffm')kernel_mappers = {image_column: [kernel_mapper]}estimator = tf.contrib.kernel_methods.KernelLinearClassifier( n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers)# Train.start = time.time()estimator.fit(input_fn=train_input_fn, steps=2000)end = time.time()print('Elapsed time: {} seconds'.format(end - start))# Evaluate and report metrics.eval_metrics = estimator.evaluate(input_fn=eval_input_fn, steps=1)print(eval_metrics)
传递到KernelLinearClassifier的唯一额外参数是一个字典,表示从 feature_columns 到要应用到相应特征列的核映射列表的映射。以下行指示分类器先使用随机傅里叶特征将初始的 784 维图像映射到 2000 维向量,然后在转换的向量上应用线性模型:
kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper( input_dim=784, output_dim=2000, stddev=5.0, name='rffm')kernel_mappers = {image_column: [kernel_mapper]}estimator = tf.contrib.kernel_methods.KernelLinearClassifier( n_classes=10, optimizer=optimizer, kernel_mappers=kernel_mappers)
请注意stddev参数。它是近似 RBF 核的标准偏差 (σ),可以控制用于分类的相似性指标。stddev通常通过微调超参数确定。
下表总结了运行上述代码的结果。我们可以通过增加映射的输出维度以及微调标准偏差,进一步提高准确率。

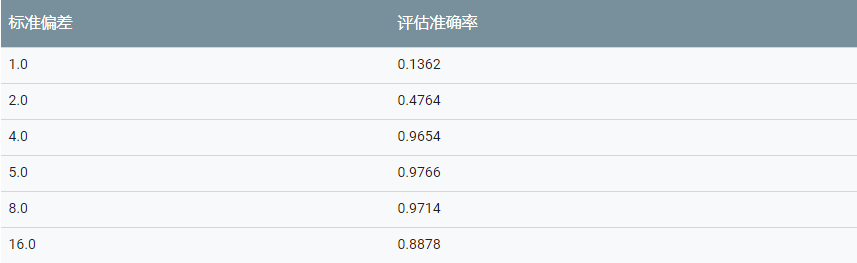
标准偏差
分类质量与标准偏差的值密切相关。下表显示了分类器在具有不同标准偏差值的评估数据上达到的准确率。最优值为标准偏差 = 5.0。注意标准偏差值过小或过大会如何显著降低分类的准确率。
输出维度
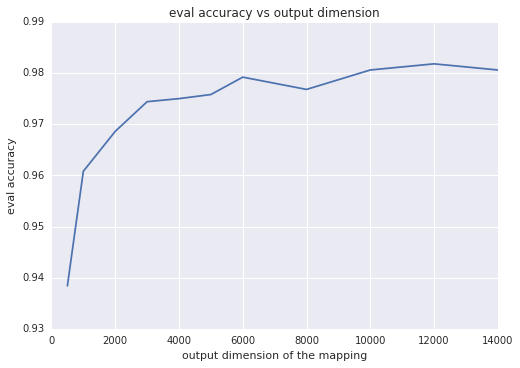
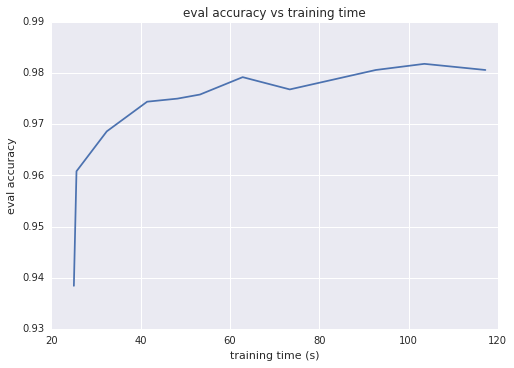
直观地来讲,映射的输出维度越大,两个映射向量的内积越逼近核,这通常意味着分类准确率越高。换一种思路就是,输出维度等于线性模型的权重数;此维度越大,模型的 “自由度” 就越高。不过,超过特定阈值后,输出维度的增加只能让准确率获得极少的提升,但却会导致训练时间更长。下面的两个图表展示了这一情况,分别显示了评估准确率与输出维度和训练时间之间的函数关系。
总结
显式核映射结合了非线性模型的预测能力和线性模型的可扩展性。与传统的双核方法不同,显式核方法可以扩展到数百万或数亿个样本。使用显式核映射时,请注意以下提示:
随机傅立叶特征对具有密集特征的数据集尤其有效
核映射的参数通常取决于数据。模型质量与这些参数密切相关。通过微调超参数可找到最优值
如果您有多个数值特征,不妨将它们合并成一个多维特征,然后向合并后的向量应用核映射
-
线性模型
+关注
关注
0文章
9浏览量
7824
原文标题:如何使用显式核方法改进线性模型
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
介绍支持向量机与决策树集成等模型的应用
八代酷睿核显的尴尬,核显遭遇研发瓶颈
一种改进的非线性亮度提升模型的逆光图像恢复手段


cpu带核显和不带核显的区别
基于显式反馈的改进协同过滤算法研究






 工商网监
工商网监
评论