 这款名为Seq2Seq-Vis的工具能将人工智能的翻译过程进行可视化
这款名为Seq2Seq-Vis的工具能将人工智能的翻译过程进行可视化
近年来随着深度学习和神经网络技术的发展,机器翻译也取得了长足的进步。神经网络结构越来越复杂,但我们始终无法解释内部发生了什么,“黑箱问题”一直困扰着我们。我们不清楚程序在翻译过程中如何进行决策,所以当翻译出错时也很难改正。随着深度学习在各行各业中的广泛应用,深度学习的不可解释性已经成为其面临的严峻挑战之一。
今年,在德国柏林举办的 IEEE VAST 可视化分析大会上,来自 IBM 和哈佛大学的研究人员展示了为解决翻译中的 AI 黑盒问题所开发的调试工具。这款名为 Seq2Seq-Vis 的工具能将人工智能的翻译过程进行可视化,方便开发人员对模型进行调试。
Seq2Seq-Vis 主要针对机器翻译中最常用的 Seq2Seq模型。这一模型能够将任意长度的序列,也就是原文的句子,映射到目标语言。除了机器翻译任务,在自动问答、文本摘要等任务中也都主要应用 Seq2Seq模型。
简单来说,Seq2Seq模型在机器翻译中的工作原理就是把源语言映射到目标语言,得到了目标语言的序列(也就是初步翻译完的句子)后再进行优化,保证语法和语义上的正确。虽然使用神经网路模型后,机器翻译的结果得到了很大的提升,但同时也非常复杂。
可视化机器翻译的过程
研究人员称研发 Seq2Seq-Vis 的初衷是想有一个类似于基于规则的传统翻译软件中的规则表,这样开发人员可以通过在规则表中对照得到错误信息就可以很简单地修改模型。
Seq2Seq-Vis.io 网站上给出了一个从德语到英语的演示程序。德语的“die längsten reisen fangen an , wenn es auf den straßen dunkel wird.”翻译成英语应该是“The longest journeys begin when it gets dark in the streets.”,但被机器翻译成了“the longest travel begins when it gets to the streets.”Seq2Seq-Vis 以可视化的方式呈现出了序列到序列模型翻译的每一步,这样用户就能像查找规则表一样来找出机器翻译翻译错误的原因。
Seq2Seq-Vis 另一个很有用的功能是它能找出与某个字词相关的训练集,这也是解决 AI 黑盒问题的一大难点。其实一个机器学习模型除了训练集一无所知,所以要解决机器翻译中的错误最终都要回到训练集中去。
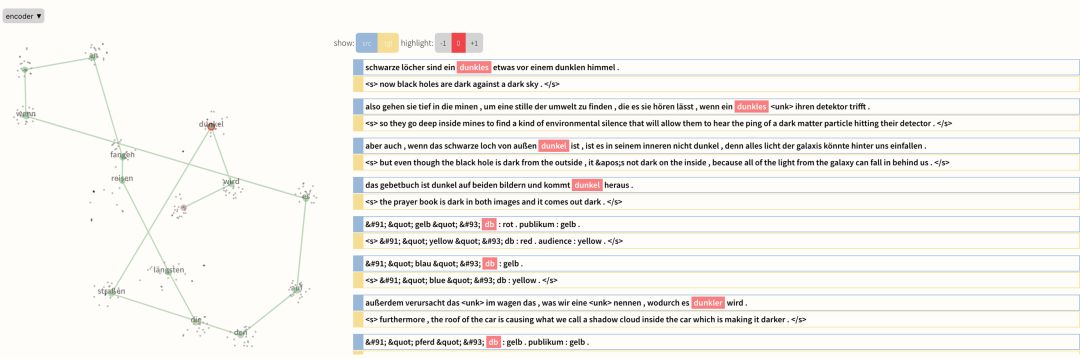
将机器翻译过程可视化,用户就能确定翻译出错到底是编码器解码器使用的训练样本出了错还是注意力模型的设置或者其他环节出错了。
更正序列到序列模型
Seq2Seq-Vis 并不是第一个试图解决 AI 黑盒问题的工具,之前有很多大公司和研究机构都有进行尝试,甚至 IBM 自己也在这上面下过功夫。事实上,很多类似的工具需要的信息比 Seq2Seq-Vis 更少,比如有的工具只需要神经网络的输出就可以,而 Seq2Seq-Vis 还需要训练集,整个模型的架构和设置。但 Seq2Seq-Vis 却是第一个既能可视化模型的决策过程也能让开发人员直接修改模型的工具。开发人员可以通过可视化的方式对模型的决策过程进行修改并观察反馈来实现探索式的调试,比如修改输出序列的单词或者对注意力模型的配置进行修改。
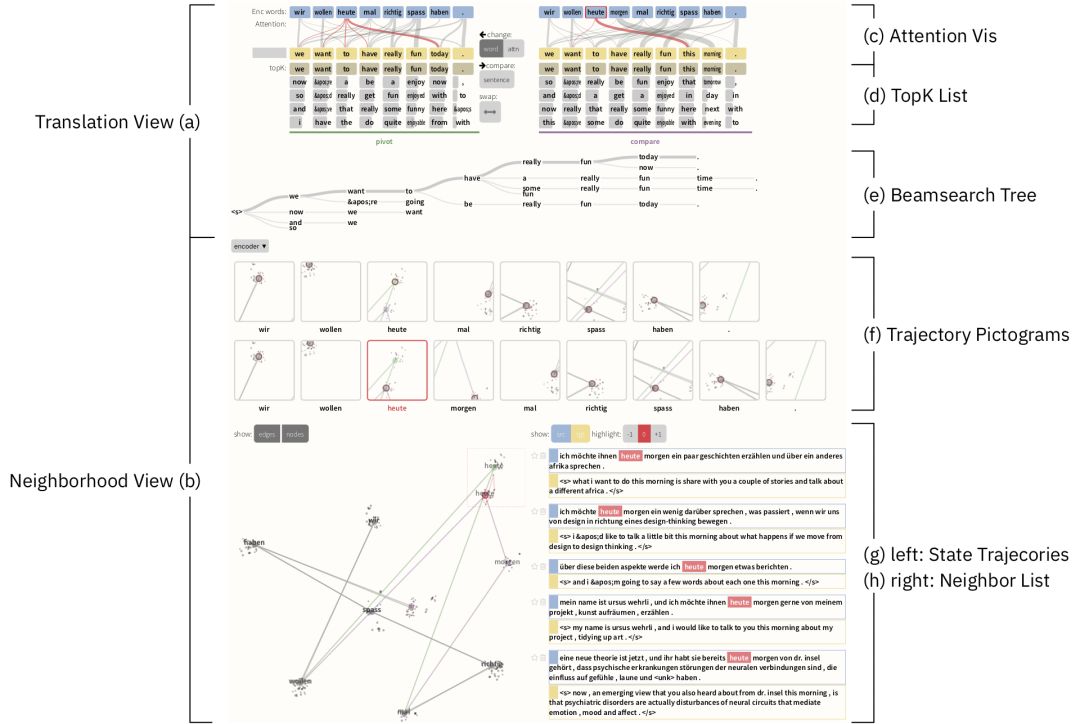
听起来是不是很酷,不过Seq2Seq-Vis 的目标群体是模型架构师或工程师而非机器翻译的终端用户。因为要让这一工具真正发挥作用需要用户对“序列到序列”模型有较为深入的了解。虽然目标这一工具还只是应用在IBM的内部项目中,但它是开源的,所以大家都可以来试试。
-
人工智能
+关注
关注
1791文章
47269浏览量
238442 -
机器学习
+关注
关注
66文章
8416浏览量
132621 -
机器翻译
+关注
关注
0文章
139浏览量
14881
原文标题:开源 | IBM、哈佛共同研发:Seq2Seq模型可视化工具
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
焊接过程可视化的应用前景有哪些

《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新
FPGA在人工智能中的应用有哪些?
大屏数据可视化 开源
如何实现园区大屏可视化?






 工商网监
工商网监
评论