 NeurIPS2018开幕,上海交通大学Acemap团队分析了NeurIPS2018的所有论文
NeurIPS2018开幕,上海交通大学Acemap团队分析了NeurIPS2018的所有论文
NeurIPS2018今天开幕,上海交通大学Acemap团队分析了NeurIPS2018的所有论文,发现前十名的几乎全是美国机构,清华、中科院、北大是发表NeurIPS论文最多的中国机构,邢波、张潼、周明远等排名前十。
NeurIPS2018来了!
神经信息处理系统大会(原名 Neural Information Processing Systems,NeurIPS)是人工智能和机器学习领域最重要的盛会,自 1987 年诞生起,这一学术会议已经走过了30余年的历史。
在中国计算机学会的国际学术会议排名中,NeurIPS为人工智能领域的A类会议。今年的大会在加拿大城市蒙特利尔举行,12月3日开幕。
上海交通大学Acemap团队分析了NeurIPS2018的所有论文1010篇,对2018年、近三年、近五年学者、机构和国家分别以第一作者身份以及合作者身份在该会议中发表论文情况进行了统计,有一些比较重要的发现:
今年会议发表论文的前10名中几乎都是美国机构,可见美国在该领域的绝对领先地位;
NeurIPS十年话题演变反映业界趋势;
Eric Xing(邢波)在NeurIPS2018会议中发表论文数量排名第二;
清华、中科院、北大是发表NeurIPS论文最多的中国机构。
机构统计:谷歌、MIT、斯坦福连续领跑前三强
NIPS2018 Affiliation Statistics统计了2018年、近三年、近五年各机构在NeurIPS会议中发表论文数量排名,下图展示了2018年排名前十的机构及论文发表数量(包含第一作者和非第一作者):
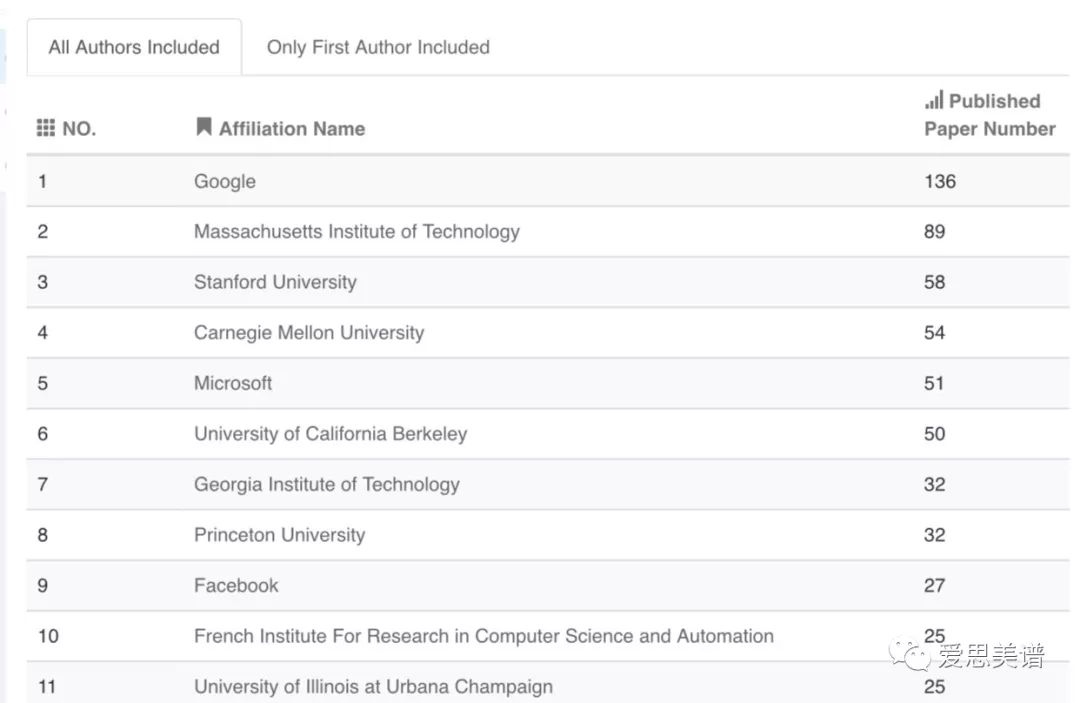
统计显示,前10名中有Google、Microsoft和Facebook三所来自工业界的机构,尤其是第一名Google发表了136篇论文之多。而且,微软作为第一作者发表的论文数量也有57篇之多(见Acemap官网)。可见Google在机器学习领域具有巨大的影响力。
同时,我们也看到前10名中几乎都是美国机构,可见美国在该领域的绝对领先地位。
时间线拉长到三年,前三名依旧是谷歌、MIT和斯坦福:
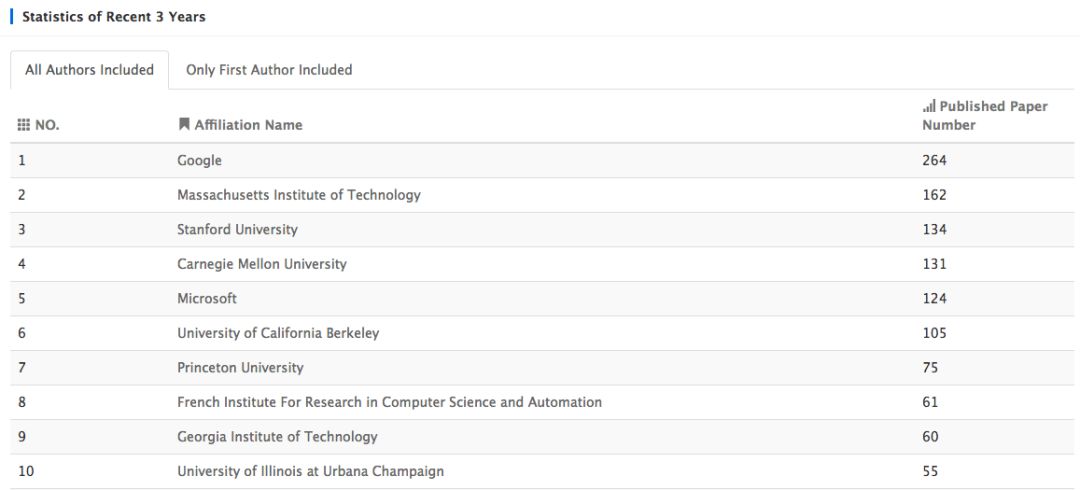
近五年内的前三名仍旧是这三位玩家,在此就不截图了,欲了解2018年、近三年、近五年仅包含第一作者/所有作者包含在内的机构统计,请至Acemap官网:
https://acemap.info/ConferenceStatistics/AuthorAffiliationRank?conf_name=NIPS&conf_year=2018&type_of_ranking=Affiliation
对于谷歌,Acemap团队也统计了该机构历年在NeurIPS论文发表情况,如下图所示:
其中,纵轴代表年份,横轴代表该机构发表的论文数。红色为第一作者身份发表的论文数。黑色位非第一作者身份发表的论文数。
同时,还统计了该机构内以第一作者身份/非第一作者身份发表的论文数最多的作者。
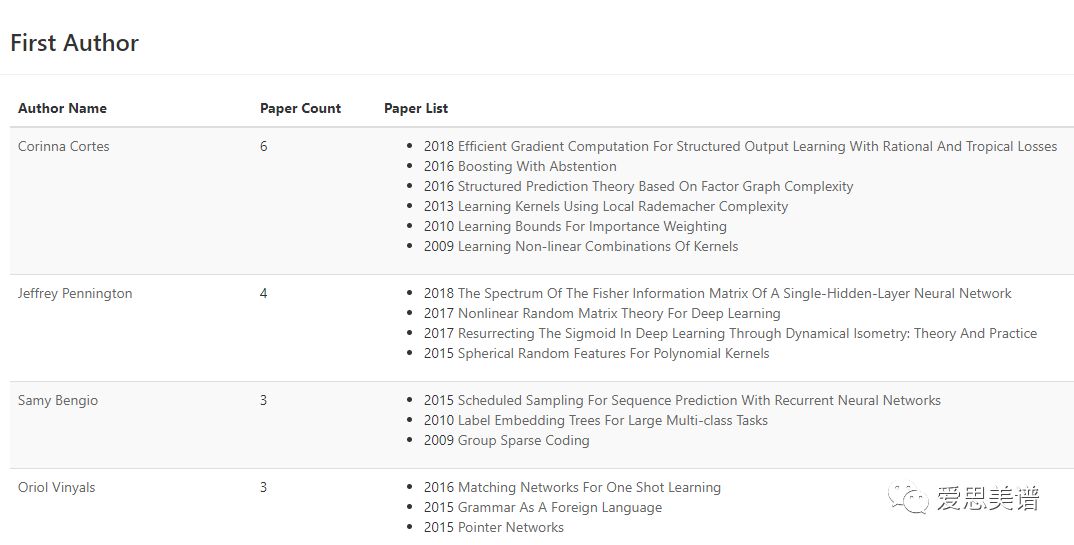
上图可以看到,谷歌公司以第一作者身份发表论文数最多的几个作者是:
Corinna Cortes
Jeffrey Pennington
Samy Bengio
Oriol Vinyals
作者统计:邢波、张潼、周明远等进入前十
NeurIPS2018 Author Statistics统计了2018年、近三年、近五年各作者在NeurIPS会议中发表论文数量排名(包含所有作者/仅包含第一作者),下图展示了2018年排名前十的作者及论文发表数量(包含所有作者):
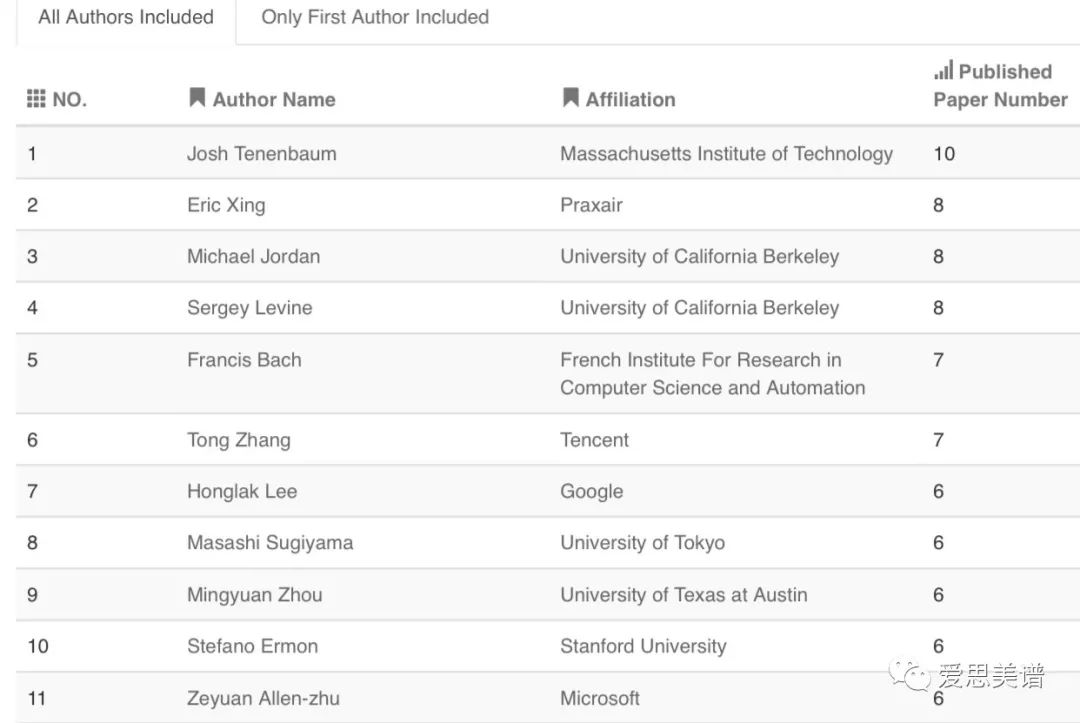
从上图可以看到,前三名分别是Josh Tenenbaum、Eric Xing(邢波)、Michael Jordan。
前十名中,华人学者有Eric Xing(邢波)、Tong Zhang(张潼)、Honglak Lee、Mingyuan Zhou(周明远)。
以上仅展示2018年排名前十的作者(包含所有作者),2018年、近三年、近五年详细排名(包含所有作者/仅包含第一作者)请浏览网址:
https://acemap.info/ConferenceStatistics/AuthorAffiliationRank?conf_name=NIPS&conf_year=2018&type_of_ranking=Author
另外,NeurIPS十年的接受率、投稿量、中稿量也进行了统计,如下图所示:
其中,绿色为投稿量,紫色为中稿量,曲线代表接受率。我们可以看到,2018年投稿量为4856,远大于2017年的3240和2016年的2403。
详细请查看:
https://acemap.info/ConferenceStatistics/acceptance_rate?conf_name=NIPS&conf_year=2018
我们提取了NeurIPS 2009-2018十年的摘要信息,利用word embedding算法将关键词映射到向量空间,然后进行聚类。对每一个聚类赋予相应的话题,总体上分为图中六大类。图中横轴代表年份,纵轴代表话题所占比例,从图中可以看到六大话题十年间的演变趋势。
我们从五个维度对每篇论文进行了相似论文推荐,形成论文推荐矩阵。这些维度包括最新、同会议、最相关、被引用数最多和导读类论文,这种多维度推荐能够满足不同用户的不同需求。AceMap针对NeurIPS 2018各篇论文的相似论文推荐页面如下如所示:
详细页面可通过点击阅读原文访问官方主页,并点击论文标题访问。
国家分布统计:中国第二;清华、中科院、北大排前三
NeurIPS 2018 Affiliation Distribution统计了2018年发表NeurIPS论文的机构所在国家的分布情况,目前只统计了发表论文数量前十位的国家,以及每个国家所发表论文的数量和比例分布情况。
前十名的国家:美国、中国、法国、英国、加拿大、瑞士、德国、韩国、澳大利亚、日本。
中国出现的机构排名:
清华、中科院、北大、南京大学、华为、北京邮电大学、天津大学、西安电子科技大学、浙江大学。
作者关系图
Acemap团队分别对2018年在NeurIPS发过论文的作者、以及所有在NeurIPS发过论文的作者画了关系图。2018年在NeurIPS发过论文的作者如下所示(截图部分)。其中,点的大小代表2018年在NeurIPS发的论文数多少。点之间的连线代表coauthor关系。
把图片放大了,可以看到Josh Tenenbaum的关系图:
此外,对NeurIPS 2018的每篇论文,Acemap团队都提供简短的内容解读。解读的方式是用机器阅读理解的方法自动提取出关键信息,包括提出什么方法解决了什么问题等,相比于一长段论文,这种导读能帮助读者在短时间内获取论文最关键的信息。
以下为解读示例:
Acemap团队对1010篇论文都做了解读。详细解读请浏览网址:
https://acemap.info/ConferenceStatistics/MainPage?conf_name=NIPS&conf_year=2018#authorstatistics
最后,Acemap对NeuIPS近年H-Index、Top30论文的平均引用量、所有论文的平均引用量进行了统计。会议H-index变化如下:
会议所有论文和Top30论文的citation变化如下:
一些大厂的NeurIPS 2018论文
前文提到2018年排名前十的机构及论文发表数量,目前,已经有一些大厂放出了NeuraIPS上的论文,新智元做了简单统计:
谷歌共计录取文章136篇。
其中第一作者来自谷歌的文章,共计57篇;谷歌参与,但并非第一作者的文章数量共计79篇。
Efficient Gradient Computation For Structured Output Learning With Rational And Tropical Losses
具有Rational、Tropical损失的结构化输出学习的有效梯度计算
Corinna Cortes,Vitaly Kuznetsov,Mehryar Mohri,Dmitry Storcheus,Scott Yang
The Spectrum Of The Fisher Information Matrix Of A Single-Hidden-Layer Neural Network
单隐层神经网络Fisher信息矩阵的谱
Jeffrey Pennington,Pratik Worah
Tangent: Automatic Differentiation Using Source-code Transformation For Dynamically Typed Array Programming
Tangent:使用源代码转换进行动态类型数组编程的自动微分
Bart van Merriënboer,Dan Moldovan,Alexander B Wiltschko
To Trust Or Not To Trust A Classifier
是否该信任一个分类器
Heinrich Jiang,Been Kim,Melody Y. Guan,Maya Gupta
Relational Recurrent Neural Networks
关系递归神经网络
Adam Santoro,Ryan Faulkner,David Raposo,Jack Rae,Mike Chrzanowski,Théophane Weber,Daan Wierstra,Oriol Vinyals,Razvan Pascanu,Timothy Lillicrap
Adversarial Examples That Fool Both Computer Vision And Time-Limited Humans
愚弄计算机视觉以及人类的对抗性的例子
Gamaleldin F. Elsayed,Shreya Shankar,Brian Cheung,Nicolas Papernot,Alex Kurakin,Ian Goodfellow,Jascha Sohl-Dickstein
Large Margin Deep Networks For Classification
用于分类的Large Margin深度网络
Gamaleldin F. Elsayed,Dilip Krishnan,Hossein Mobahi,Kevin Regan,Samy Bengio
Data-Efficient Hierarchical Reinforcement Learning
数据高效的分层强化学习
Ofir Nachum,Shixiang Gu,Honglak Lee,Sergey Levine
TopRank: A Practical Algorithm For Online Stochastic Ranking
TopRank:在线随机排名的实用算法
Tor Lattimore,Branislav Kveton,Shuai Li,Csaba Szepesvari
Meta-Gradient Reinforcement Learning
元梯度强化学习
Zhongwen Xu,Hado van Hasselt,David Silver
Trading Robust Representations For Sample Complexity Through Self-supervised Visual Experience
通过自我监督的视觉体验,用鲁棒的表现形式换取样本的复杂性
Andrea Tacchetti
Re-evaluating Evaluation
Re-evaluating评估
David Balduzzi,Karl Tuyls,Julien Perolat,Thore Graepel
A Lyapunov-based Approach To Safe Reinforcement Learning
基于Lyapunov的安全强化学习方法
Yinlam Chow,Ofir Nachum,Edgar Duenez-Guzman,Mohammad Ghavamzadeh
Assessing The Scalability Of Biologically-Motivated Deep Learning Algorithms And Architectures
评估生物激励的深度学习算法和体系结构的可扩展性
Sergey Bartunov,Adam Santoro,Blake A. Richards,Luke Marris,Geoffrey E. Hinton,Timothy Lillicrap
Provable Variational Inference For Constrained Log-Submodular Models
约束Log-Submodular模型的可证变分推理
Josip Djolonga,Stefanie Jegelka,Andreas Krause
Playing Hard Exploration Games By Watching YouTube
通过观看YouTube玩硬探索游戏
Yusuf Aytar,Tobias Pfaff,David Budden,Tom Le Paine,Ziyu Wang,Nando de Freitas
Transfer Learning From Speaker Verification To Multispeaker Text-To-Speech Synthesis
从说话人验证迁移学习到多语言文本、语音合成
Ye Jia,Yu Zhang,Ron J. Weiss,Quan Wang,Jonathan Shen,Fei Ren,Zhifeng Chen,Patrick Nguyen,Ruoming Pang,Ignacio Lopez Moreno,Yonghui Wu
更多与谷歌相关录取文章可点击下方链接查看:
https://acemap.info/ConferenceStatistics/affiliationpage?affID=4CF99586&conf_name=NIPS&conf_year=2018
Facebook(未包含workshop):
A^2-Nets: Double Attention Networks
A^2-Nets: 双重注意网络
Yunpeng Chen,Yannis Kalantidis, Jianshu Li, Shuicheng Yan and Jiashi Feng
学习捕捉长期关系是图像/视频识别的基础。现有的CNN模型一般依赖于增加深度来模拟这种关系,效率非常低。在这项工作中,我们提出“double attention block”,这是一个新的构建块,能够汇集并传播来自输入图像/视频的整个时空空间的全局信息特征,使后续的卷积层能够有效地访问来自整个空间的特征。
A Block Coordinate Ascent Algorithm for Mean-Variance Optimization
均值 - 方差优化的块坐标上升算法
Tengyang Xie,Bo Liu, Yangyang Xu,Mohammad Ghavamzadeh, Yinlam Chow, Daoming Lyu and Daesub Yoon
均值-方差函数是风险管理中应用最广泛的目标函数之一,具有简单易行、易于解释等优点。现有的均值-方差优化算法是基于多时间尺度随机逼近的,其学习速率表往往难以优化,且只有渐近收敛证明。在这篇论文中,我们提出一种无模型均值方差优化策略搜索框架,基于有限样本误差约束分析。我们在几个基准域上证明了它们的适用性。
A Lyapunov-based Approach to Safe Reinforcement Learning基于Lyapunov的安全强化学习方法
Yinlam Chow, Ofir Nachum, Edgar Duenez-Guzman andMohammad Ghavamzadeh
在许多现实世界的强化学习(RL)问题中,除了优化主要目标函数外,智能体还必须同时避免违反各种约束。特别是,除了优化性能外,在训练和部署过程中,保证agent的“安全性”也是至关重要的。为了将安全性纳入RL,我们在约束马尔可夫决策过程(CMDPs)的框架下推导算法。结果表明,该方法在平衡约束满意度和性能方面明显优于现有基线。
The Description Length of Deep Learning Models深度学习模型的描述长度
Léonard Blier andYann Ollivier
Solomonoff的一般推理理论和最小描述长度原则是奥卡姆剃刀形式化的结果,并认为良好的数据模型必须是擅长无损压缩数据的模型。考虑到要编码的大量参数,深度神经网络似乎违背了这一原则。我们通过实验证明了深度神经网络即使在考虑参数编码时也能够压缩训练数据。
Fast Approximate Natural Gradient Descent in a Kronecker Factored Eigenbasis
Kronecker Factored Eigenbasis的快速近似自然梯度下降
Thomas George, César Laurent, Xavier Bouthillier,Nicolas BallasandPascal Vincent
Fighting Boredom in Recommender Systems with Linear Reinforcement Learning在线性强化学习的推荐系统中对抗无聊
Romain Warlop,Alessandro Lazaricand Jérémie Mary
Forward Modeling for Partial Observation Strategy Games – A StarCraft Defogger部分观察战略游戏的正向建模 - 星际争霸Defogger
Gabriel Synnaeve,Zeming Lin,Jonas Gehring, Dan Gant,Vegard Mella,Vasil Khalidov,Nicolas CarionandNicolas Usunier
GLoMo: Unsupervisedly Learned Relational tGraphs as Transferable RepresentationsGLoMo:非监督学习关系tGraphs作为可转移的表示
Zhilin Yang,Jake Zhao, Bhuwan Dhingra,Kaiming He, William Cohen, Ruslan Salakhutdinov andYann LeCun
Near Optimal Exploration-Exploitation in Non-Communicating Markov Decision Processes非传播马尔可夫决策过程的近似最优探索-开发
Ronan Fruit,Matteo PirottaandAlessandro Lazaric
Non-Adversarial Mapping with VAEs使用VAE进行非对抗性映射
Yedid Hoshen
One-Shot Unsupervised Cross Domain TranslationOne-Shot无监督跨域翻译
Sagie Benaim andLior Wolf
SING: Symbol-to-Instrument Neural GeneratorSING:从音符到乐器的神经生成器
Alexandre Defossez,Neil Zeghidour,Nicolas Usunier,Leon Bottouand Francis Bach
Temporal Regularization for Markov Decision Process
马尔可夫决策过程的时间正则化
Pierre Thodoroff, Audrey Durand, Joelle Pineau and Doina Precup
一波三折的NeurIPS 2018
NeurIPS只是最近才被官方用到的名称,通常被称为NIPS,但就是这个四字缩写让今年的会议一波三折。
“NIPS”因为带有性暗示,已经在今年引起了许多争议,几次公众呼吁改名之后,NIPS 组委会在今年 4 月份宣布,他们正在考虑改名,并很快就此事向社区征询意见。
不过大家的回应好坏参半。有人支持,有人反对,谷歌大脑研究员 David Ha(Twitter@hardmaru)个人统计结果,结果 50% 投票者认为保留原来的名字更好。
后来,NIPS官网默默地开始使用 NeurIPS 作为会议的缩写,也增加了新的网址neurips.cc.,这才让改名风波告一段落。
但是,改名事情刚消停,又被曝出有十几名研究人员签证被拒的情况。像NeurIPS这样的顶级会议往往在欧美国家召开,但其实这对其他非发达国家的研究人员是不公平的,一旦出现外部因素影响(例如签证),就会给这些非发达国家的研究人员带来极大不便。
现在,已经有学者呼吁顶会要照顾非发达国家,Yoshua Bengio在最近的一次采访时表示,另一个机器学习顶会ICLR,将在2020年移师非洲,做出了表率。
最后,对AI从业者来说,最重要是能参会。但是NeurIPS2018的门票比霉霉的演唱会门票还难抢,主办方于 9 月 4 日 8 点开放注册,但仅用了11分钟38秒主会议门票就售罄,半小时后,tutorial和workshop的票也全部显示Sold Out。
今年的NeurIPS2018,你是选择看直播还是亲临现场?
-
微软
+关注
关注
4文章
6574浏览量
103972 -
谷歌
+关注
关注
27文章
6142浏览量
105157 -
论文
+关注
关注
1文章
103浏览量
14955
原文标题:NeurIPS 2018开锣,中国论文数全球第二!清华、中科院、北大排前三
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
上海交大团队发表MEMS视触觉融合多模态人机交互新进展

蚂蚁数科与浙大团队荣获NeurIPS竞赛冠军
上海交通大学:基于4D心脏波束成形的MIMO毫米波生物雷达生命体征监测系统

赛昉科技与上海交通大学国家集成电路人才培养基地达成课程合作,推动高校RISC-V人才培育

阿尔泰科技与西安交通大学陕西省某技术重点实验室共谋未来!

打造原生创新人才新高地 上海交通大学携手华为成立鲲鹏昇腾科教创新卓越中心

雷曼光电与上海交通大学安泰经济与管理学院发展战略合作
达实久信中标上海交通大学医学院附属第九人民医院祝桥院区项目
上海交通大学集成电路学院揭牌成立
西安交大耿莉教授团队在国际固态电路会议展示最新芯片研究成果
转载:FCS Perspective | 上海交通大学陈海波教授团队——元OS:面向万物智联时代的操作系统

NeurIPS23|视觉 「读脑术」:从大脑活动中重建你眼中的世界






 工商网监
工商网监
评论