 一年一度的NeurIPS又开始啦!寒冷的蒙特利尔将开启AI模式
一年一度的NeurIPS又开始啦!寒冷的蒙特利尔将开启AI模式

一年一度的NeurIPS又开始啦!寒冷的蒙特利尔这一周将开启AI模式,来自世界各地的研究人员、相关企业和学者将齐聚这里探讨AI的最新进展和未来发展。
为期七天的会议将带来一系列丰富的主题演讲、论文口头报告、海报展示、demo展示等内容。我们为各位小伙伴带来了今天即将举行教程部分的内容概览,以及即将到来的Oral口头报告的精彩内容预告。
Tutorials 新理论新方法新技术
Adversarial Robustness: Theory and Practice
来自CMU和MIT的研究人员将对于如何实现真正可靠和鲁棒的机器学习系统进行讲解。这一教程首先对这一领域存在的关键挑战进行了综述,并集中在对抗鲁棒性这一问题上进行深入细致的分析。将从理论和实践角度讨论这一问题的各个方面,并将展示近年来一些经过验证的有效做法。
Scalable Bayesian Inference
来自杜克大学的研究人员将带来利用贝叶斯统计方法应用于大规模数据集分析的前沿方法。教程将集中与两个方面,首先是应用于大规模数据的算法,其次是处理超高维度数据的手段。教程首先将回顾经典的大样本近似后验分布方法(拉普拉斯方法和贝叶斯中心极限定理),随后转向利用马尔科夫蒙特卡洛算法那的概念与实践方法。主要的注意力将放在如何在保证精度的情况下,快速的获取大规模数据集的后验。
Visualization for Machine Learning
对于机器学习来说,可视化是帮助我们理解算法和数据的有效手段。这一教程将概览目前的机器学习可视化方法,如何在研究的不同阶段使用合适的可视化方法:分析训练数据、理解模型、测试模型分析等。同时还将探索可视化在教育以及非技术领域的应用价值。
Unsupervised Deep Learning
非监督学习在深度学习领域起到越来越重要的作用,其最主要的挑战在于如何确定目标函数。这一教程将提供一种概率模型的方法,它将对数据进行尽可能的压缩。同时教程还将提供包括非归一化的基于能量的方法、自监督算法以及生成模型等方法。
Automatic Machine Learning
机器学习的成功最开始依赖于人类的经验,需要经验丰富的研究人员构建复杂的特征工程和选择合适的机器学习方法、架构并详细的调节各种超参数。但自动机器学习的出现将逐渐改变这一状况,通过机器学习和优化方法来提供一种无须专业知识就可以使用的模型。这一领域十分广泛,包含了超参数优化、神经网络搜索、元学习和迁移学习等方向。这一教程将概述目前前沿的方法和技术。
Statistical Learning Theory: a Hitchhiker's Guide
这一教程将展示统计学习如何评估和实现学习系统,通过强调算法如何从结果中获得反馈来提升性能,并理解其极限。这一教程主要为希望进一步了解统计学习的研究人员准备。
此外还有以下教程等待着各位热爱学习的小伙伴们:
Common Pitfalls for Studying the Human Side of Machine Learning
Negative Dependence, Stable Polynomials, and All That
Oral 报告前沿进展
Oral部分的演讲往往会带来很多优秀的研究成果。下面让我们一起来看看有哪些有趣的报告吧!
Learning to Reconstruct Shapes from Unseen Classes
从单张图片重建未知物体。来自MIT的研究人员设计了一种称为Generalizable Reconstraction(GenRe)的算法,来从训练数据中抽取更多一般的与类别无关的形状信息。通过结合了可见表面的2.5D表示、可见和不可见表面的球形表示以及三位体素表示来探索了3D形状如何得到2D图片的过程,并成功的利用训练的网络从单张图片中恢复出训练集中不存在物体的三维形状。
文章中提出的模型有三部分构成:首先是一个从深度估计器;随后是一个球面图像补全网络,最后是一个体素精炼网络。最后通过体素和深度图的叠加来实现3D形状输出。
下图是网络的预测,网络仅仅在汽车、飞机和椅子的数据上进行了训练,这表明模型已经学习到了形状的通用表示。
Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning
泰国科技学院和谷歌的研究人员提出了利用端到端的几何推理方法发现潜在的3D关键点。这篇文章中,研究人员提出了KeyPointNet几何推理框架来学习优化每一类特定的3D关键点及其检测器。这一框架在3D位姿估计任务中可以搜寻到一组最优的关键点集来重建某个物体在两个视角下的相对位姿。
同时它可以从不同视角的图像中发现几何和语义上一致的关键点,并在位姿估计任务中超越了全监督学习的网络表现。训练过程和推理过程如下,其中两个视角下的刚体变换作为监督信号,网络优化得到了一组在两个视角下都一致的关键点。
网络得到的关键点如上图所示
Isolating Sources of Disentanglement in VAEs
多伦多大学向量学院的研究人员研究了隐变量间整体相关性,发现了解构的变分下界可以用于解释β-VAE用于学习解耦隐变量的能力,它鼓励模型寻找统计上相互独立的因素。随后提出了一种称为β-TCVAE(total correlation VAE)的算法用于代替β-VAE来学习解耦的隐变量。最后研究人员还提出了一个与类别无关的解耦计量指标MIG(mutual information gap)。基于这一算法训练的模型显示了解耦和整体相关性间的强烈关系。
上图显示了利用这种算法对于隐空间变量结构的学习和效果
Policy Optimization via Importance Sampling
来自米兰理工的研究人员们提出了一种基于重要性采样的策略优化方法。这篇文章中提出了一种新颖的不基于模型测策略搜索算法POIS(Policy Optimization via Importance Sampling),可以用于基于行为或者基于参数的方式。在这一研究中,研究人员首先得到高置信度的重要性采样估计,随后定义了代理目标函数来进行线下优化,最终在一系列连续控制任务中进行了线性和深度策略的测试。
Neuronal Capacity
来自加州大学欧文分校的研究人员认为,学习机器的能力可以被定义为它可以执行函数数量的对数。在这一工作中,研究人员回顾了已有的工作并推导出了新的结果,同时对多种神经模型的容量进行了计算:包括线性和多项式阈值门、线性和多项式受限阈值门以及ReLU神经元,同时还推导了一些网络的容量。
上图是不同布尔函数在N个变量下的分级容量图。
Dendritic cortical microcircuits approximate the backpropagation algorithm
来自伯尔尼、蒙特利尔大学的研究人员提出了利用树突皮质微电(回)路来近似反向传播的方法。在这篇文章中研究人员们基于简化的输入间隔引入了一种多层神经网络模型,它可以基于误差驱动突触可塑性适应网络的全局输出。与先前方法不同的是,这种模型不需要分成几个部分,突触学习是通过局域树突的连续误差信号驱动的。这一误差信号来自于预测信号和实际信号不匹配的时候,通过简单地使用树突间隔,这一模型可以表示神经元的误差和正常活动。研究人员还将其用于回归和分类任务中,并发现它可以近似误差反向计算的BP算法。
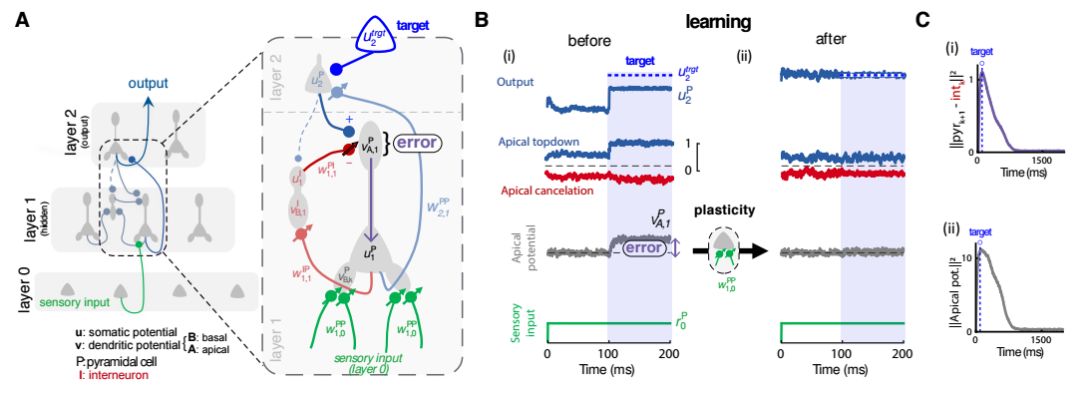
图中显示了树突皮质近似bp算法的原理。
A Retrieve-and-Edit Framework for Predicting Structured Outputs
斯坦福的研究人员实现了可以预测结构化输出的检索-编辑框架。对于生成源代码这样复杂的结构化输出任务来说,通过对已有的代码进行编辑比从零开始生成容易的多。基于这样的想法,研究人员提出了一种新的框架:首先根据输入检索出训练样本,随后对其进行编辑得到期望的输出结果。这种方法无需复杂的手工度量或与编辑器进行联调,计算高效适应性强。作者表示这一框架可以用于任何基础框架之上,并在Github Python代码和Hearthstone card上取得了优异的结果。
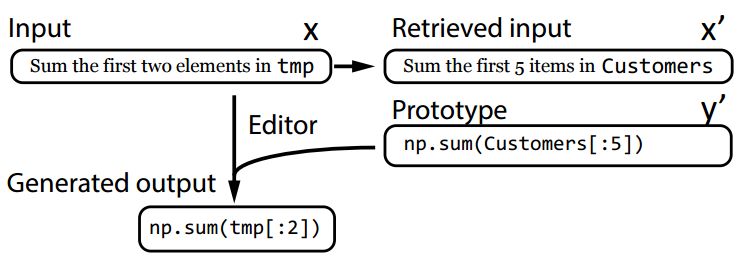
框架如上图所示

显示一些基于检索-编辑框架生成的源码。
Model-Agnostic Private Learning
牛津大学的研究人员在神经科学的启发下研究了如何实现知识泛化(一般化)的能力,在本文中提出为了一般化结构化的知识、表示世界结构的知识(例如世界中的实体间的相互关系)需要与实体自身的表示进行分离。研究表明,在这一观点的指导下、利用层级和记忆实现的神经网络可以学到记忆的统计信息并泛化结构化知识,同时空间认知能力是更一般化组织原则的实例。
结构化与传感信息的独立表示在衔接编码中结合。右图显示了模型需要从不同的域中抽取出一般化的统计信息。
除此之外,还有包括学习理论、优化过程、强化学习、采样、近似和各个领域详尽的理论分析。感兴趣的小伙伴可以在这里找到更多的Oral报告:https://neurips.cc/Conferences/2018/Schedule?type=Oral
-
机器学习
+关注
关注
67文章
8570浏览量
137381 -
数据集
+关注
关注
4文章
1242浏览量
26282
原文标题:寒冷冬日NeurIPS热力来袭,Tutorials、Oral内容一览
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
EtherNet/IP转Modbus RTU网关如何让罗克韦尔PLC“听懂”编码器的每一度角

安富利携手TE Connectivity与您相约Sensor Shenzhen 2026

益登科技原厂Supermicro和江波龙参展MWC 2026
汇川技术董事长朱兴明2026年度演讲实录
2026年,思尔芯将持续深耕RISC - V与AI

安富利荣获歌尔集团2025年度最佳协同奖
Verosoft发布mobiMentor AI

活动邀请 | 相约2025 GOTC全球开源技术峰会,与M5Stack共探AI驱动造物新未来

年增19%!中美欧等法规出手,这颗传感器迎来全球爆发潮



评论