 基于FFmpeg的运动视频分析技术架构,以及英特尔视频分析的软硬件解决方案
基于FFmpeg的运动视频分析技术架构,以及英特尔视频分析的软硬件解决方案

本文来自英特尔资深软件工程师李忠,张华在LiveVideoStackCon 2018大会上的分享,由LiveVideoStack整理而成。分享中两位老师重点介绍了基于FFmpeg的运动视频分析技术架构,以及英特尔视频分析的软硬件解决方案。
大家好,我是来自英特尔开源技术中心的李忠,致力于对FFmpeg硬件加速的研究开发。今天我将与来自英特尔Data Center Group的张华老师一起,与大家分享我们对基于FFmpeg的运动视频分析解决方案的技术实践与探索。
首先我会为大家介绍视频分析的市场前景与基于FFmpeg的运动视频分析解决方案的主体架构。而张华老师会为大家分享英特尔运动视频分析的典型案例,希望可以为大家带来帮助。
1.视频分析的市场前景
可以说,视频分析是一片潜力巨大的新兴市场,目前全球视频分析市场规模已超过145亿美元,资本对视频内容的总投入逐年增加并会在未来保持继续增长的态势。目前的网络带宽中视频流占总体数据流的80%,如果我们能够在这样一个规模庞大的市场借助视频分析的力量为用户带来更优秀的产品体验,无疑是对整个音视频行业的一次有利的促进。
2.视频行业的技术趋势
从技术趋势上看,视频分析与当下多种高新技术紧密结合。根据专业咨询公司给出的2018年技术趋势报告,视频分析与AI Foundation(可提供多种能够帮助用户进行视频分析的AI基础组件如Framework、Analyse等)、智能APP与智能分析(完善的智能分析解决方案)、沉浸式体验(VR、AR、MR等)。我们希望视频分析技术能够在市场中大放异彩,为客户带来理想的收益与价值。
3.基于FFmpeg的运动视频分析
3.1 视频分析流程
那么落实到技术当中,接下来我将介绍视频分析的详细流程。视频分析不单单包括对视频数据的计算,而是由多个协同工作的组建构建起的一套完整架构并集成在一条符合逻辑的处理流程当中。上图展示的是比较典型的视频分析流程。首先,传输进来的视频源数据会被解码、缩放与视频颜色空间转换从而便于后续的分析;而后视频数据会被具体分析如人脸检测、入侵检测、视频特征提取、车辆识别与检测等;完成分析后传输的结果可能是从视频中提取的目标信息,也可能是经过转码生成的视频流;整套视频分析流程需要强大的服务器支撑如Video Storage Server、Video Streaming Server与Video Application Server等服务器;最底层则是HW Platform,用户可根据自身需求通过HW Platform调用CPU、GPU等硬件。
3.2 视频分析架构
我们需要一个能够完美支持上述视频分析流程的优秀架构,也就是将FFmpeg的架构与视频分析流程紧密结合。上图展示的是一个完整的FFmpeg架构,有着对Streaming、Decoding、Encoding、Mux、Demux等功能的良好支持,且能够将经过Demux/Splitter处理的数据流分解成Video流与Audio流以便于后续进行对音视频的分析处理如传统的去抖动、颜色空间转换、FRC等操作。(FFmpeg有两个典型输出:输出Video Renderer与或再进行一次编码后与音视频流复合输出,通过流媒体传输上载到端设备处。)
大家可以看到FFmpeg的架构和视频分析的流程非常相似,FFmpeg的优势之一是对流媒体、编解码、Mux/Demux等功能的良好支持,其次FFmpeg也支持多种视频Filter如Scaling、CSC、Denoise、Tone-Mapping等。至于硬件解决方案,FFmpeg同样支持Hardware Upload/Download等Filter,用于CPU和GPU存储之间的数据交换。当然,FFmpeg对英特尔硬件加速转码的Filter如DXVA、VA-API、QSV、OpenCL等的支持同样优异。虽然FFmpeg擅长处理视频相关复杂任务,但其对AI相关功能的支持还停留在较为原始的阶段,仅能胜任一些简单AI处理任务如超分辨率等。除此之外,擅长视频转码的FFmpeg并不擅长视频分析,如果我们需要将其用于视频分析则需要把FFmpeg与一些CV Libaries或AI Libaries相结合。
3.3 FFmpeg 英特尔硬件加速解决方案
我们知道,对一条视频流进行分析需经过编码、解码、处理、分析等流程,其背后的计算过程之复杂,数据量之大超乎想象,如何保证性能的持续高效输出便成了摆在我们面前的关键性命题。如果仅基于CPU实现这样一套计算量巨大流程复杂的实时处理效果显然是不现实的,单纯地堆砌CPU也会为企业带来巨大的成本压力。那么我们能否选择现有的硬件加速解决方案来优化处理流程使其实现硬件的充分利用?
在转码领域,FFmpeg已对英特尔硬件加速有了较为优异的支持。在Linux环境下,FFmpeg包含三个plugins:VA-API Plugins、QSV Plugins、Compute Plugins。VA-API Plugins可直接调度LibVA的Interface并通过Intel Video Driver实现硬件加速;QSV Plugins则需要调用MSDK,再通过MSDK调用LibVA从而通过Intel Video Driver实现硬件加速;而Compute Plugins则主要通过调用OpenCL或即将被支持的Vulkan来进行计算,利用GPU强大的通用计算能力提供更多的扩展功能。
英特尔GPU支持的Codec范围十分广泛,除了HEVC,还有H.264、VP8、VP9、MPEG2等;基于VAAPI的Filter有dnoise、color space convertion,以及scaling等,而基于QSV的Filter功能上也是很类似的。无论是VAAPI还是Media SDK都对Intel Video Driver、Intel HW Fix Function有良好支持。有时我们需要一种更为灵活的方案,那么可以用到Compute Pugins,主要包括OpenCL与Vulkan。开发者可通过此Filter利用英特尔GPU的通用计算能力实现强大功能,并且目前Compute Plugins对Overlay /ToneMapping等都有良好支持。也许有人会提出疑问:为什么需要三个Plugins?从平台限制角度来看,Compute Plugins可以不局限于Fix funtion而提供更为灵活的解决方案。而VA-API Plugins则是FFmpeg的一条更为本地化(Native)的pipeline,并不依赖Media SDK;但VA-API Plugins的局限在于仅支持Linux而不支持Windows,而QSV Plugins 流程下的Media SDK却可提供跨平台支持,比如Media SDK可在Windows上进行Encode的原因;其次VAAPI更多是基于FFmpeg实现诸多功能,这对熟悉FFmpeg的开发者而言上手难度较低,方便基于VAAPI实现二次开发,而Media SDK更多由英特尔主导。另外,一些针对英特尔硬件平台做的高复杂度所做的功能或优化,并不适合在FFmpeg这层实现,比较适合由MSDK处理,比如MFE等。
对转码流程而言最重要的三项Encoder指标:质量、性能表现、配置灵活度。为了提升Encoder质量,我们加入了look ahead码率控制、动态GOP判断、自适应(IPB)划分等为Encoder质量带来显著提升。
为了提升性能表现,我们针对以下两种转码场景进行了优化调整——一对一转码和一对多转码。我们在一对一转码中引入了异步机制,较为复杂的视频图像任务交给GPU硬件加速完成,而音频编解码处理、Mux/Demux等工程量较小的任务则交给CPU完成。科学分配CPU与GPU所要承担的任务并通过异步机制使二者默契配合。统流程中,当CPU完成给定任务后产生的等待间隙会对性能造成损失;而引入异步操作后,当CPU完成给定工作后会将这部分工作直接传递至GPU中而自己去处理其他一些亟待完成的任务,接下来GPU再将处理完的任务传回CPU,这种异步操作可极大改善转码的性能表现。而针对一对多或多对多转码,我们使用一种被称为MFE (multiple frame encoding)的方式优化转码流程。视频编码可被简单理解为对一帧帧单独编码,而英特尔对转码的性能利用率要求很高,如果单纯地一帧帧转码就会出现GPU利用率不高的问题,造成利用率不高问题的主要原因之一是流水并行的启动和终止。我们知道,视频编码流程可看作是基于宏块(macroblock)的流水线作业,流水线的并行需要启动与终止时间;对于那些小分辨率视频来说流水线的启动与终止时间较长,整条线程还未完全排布满工程这一帧就已结束,导致流水并行度的不足,硬件性能利用率不高;除此之外,还有像GPU hardware context switch问题也能造成GPU性能使用效率较低的情况。如何提高一对多或多对多转码的性能表现?MFE可以将多帧进行整合从而让GPU编码并输出使得转码效率获得显著提升。
配置灵活性是除了编码质量外影响GPU使用的另一重要因素,可使用Filter的数量与配置Encode的灵活便捷程度直接影响我们开发相关功能的成本。如X264包括许多非常方便的配置,并且也提供了很多Preset。我们希望尽可能简化开发流程降低开发门槛,精简用户需要确定的输入参数并提供一些简单的Preset。这样对于一般用户而言不需要在运动搜索多少帧与范围上花太多精力,只需设置好Preset就可在硬件加速的质量与性能表现二者之间取得平衡。
上图展示的三条pipeline各有其优势,且适用场景也不尽相同。在FFmpeg中我们可以灵活的选择,如单纯使用VAAPI进行转码、Scaling或CSC;或者通过QSV的Transcoding pipeline进行视频编解码和视频处理;除此之外,还支持两者间的混合使用,以达到优势互补的效果。如选择VAAPI decode + QSV encode的方式,构建成的pipeline适用性更强,可以极大程度上拓展用户开发相关功能的范围。
3.4 Intel AI Portfolio
尽管FFmpeg对AI的支持较为欠缺,但英特尔对AI Portfolio的支持可以说是相当完整,提供了一套从底层到中间层覆盖完善的成熟AI工具集,无论是灵活性还是选择范围都非常优秀,开发者可根据具体应用场景来选择使用什么样的硬件与架构。
接下来有关英特尔运动视频分析案例的解析部分,由来自英特尔DCG的张华老师为大家分享。
4.英特尔运动视频分析案例解析
大家好,紧接着李老师的分享,我将会为大家介绍英特尔借助FFmpeg硬件加速实现运动视频分析的典型案例,我们主要会将此功能用于大型体育赛事的回放与模拟,涉及在线视频编解码,对球和球员的识别,3D场景重建等功能从而实现沉浸式观看体验。
4.1 基于5G FlexRAN的2.5k体育直播画面的虚拟分析
例如图中展示的5G网络下的足球比赛场景分析,包含多路视频输出。每路视频都会进行球员的识别和跟踪,球的识别和跟踪,最终借助得到信息和视频还原的整个球场的状态。体育场上方会布置12台不同角度用于图像捕捉的摄像头,由这些摄像头捕捉并处理完成的数据首先会被以2.5k AVC@30fps的格式参数传输至集成了VCA卡的视频处理服务器,视频处理服务器处理完成后的视频数据会被转码压缩并传输至5G FlexRAN——这是英特尔一个基于5G网络搭建的数据处理平台,其功能类似于CDN,将处理完成的视频数据传输分发至每一位场外观众的移动终端上。需要强调的是,这些摄像头的位置都需要进行预先设置和标定,并且每路视频会被独立处理。
4.2 解决方案详述

如果想达到符合要求的重建效果,我们需要什么条件?除了刚才介绍到的12个负责采集、转码、视频分析、三维重建的摄像机位,还需要可靠的网络传输也就是5G FlexRAN;在功能上,我们需要将视频以12x AVC 2.5k@30fps的编码形式在整条流程上传输,而视频分析、编解码等操作都是在边缘服务器上完成。为了满足这样的编解码与视频分析需求,我们需要24张VCA卡(每路视频两张)用于分析球与球员的运动情况,包括球与球员的监测与跟踪、融合、分析结束后的转码等等。我们会根据终端的支持情况调整视频输出的格式参数。
4.3 关键特性

对于运动场景的视频分析,关键在于球和球员的detection与tracking,结合球与球员运动轨迹分析二者精准位置与运动情况。这里需要强调的是,我们采取不同的流程处理球与球员。主要是因为对于2.5K分辨率的视频进行监测与分析,球在画面中只是一个很小的元素,单纯的扫描无法准确判断球的运动轨迹,所以系统只能将2.5k的视频源画面分割成若干个分辨率为160×160的小画面并且使得画面与画面之间一定存在重合,这样每帧原始视频需要在计算大约两百幅画面后才能完成detection;而球员相对球而言在画面中要更佳明显,这样需要计算的小画面数量就会降低,如此庞大的数据量需要强大的计算能力;但球或球员的运动是有连续渐变的,这就使得我们不需要对每帧视频进行detection;通过对球员的跟踪大致预测球员的前进轨迹从而推测出下一帧球出现的位置,从而通过tracking加速分析过程。在此基础上,一些功能就可以实现:“Freeze Moment”的功能,也就是定格比赛并以三维场景呈现赛场瞬间定格; “精彩瞬间”的功能,主要也是通过三维场景重建还原比赛的精彩瞬间。但三维重建等流程还未达到实时处理的要求,后续还需在算法上进一步优化。
4.4 处理流程
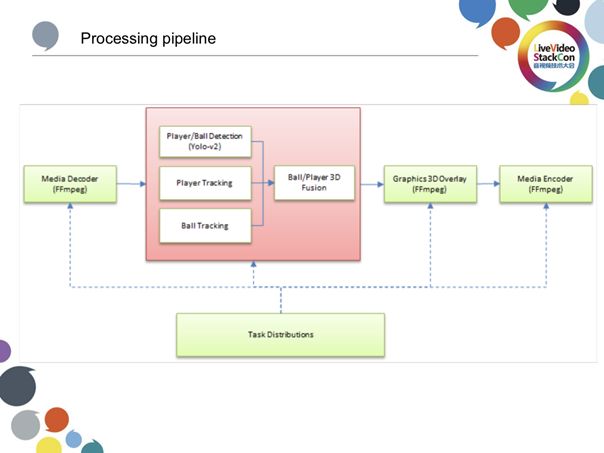
上图展示的是每一路视频的处理流程。此流程基于FFmpeg 充分利用Intel GPU的硬件pipeline,达到处理的最高效率,AI部分的处理工作是由GPU完成,数据也是在GPU的显存中存储,中间的主要处理流程包括球与球员的监测与跟踪;detection是fine-tune后的Yolo-v2算法,tracking的算法是MDP。随后系统会融合球与球员,也就是将摄像机坐标映射至球场坐标,根据物体的特点不同,融合的方法一不一样,球是3D融合,球员是2D融合。12个机位代表有12路上述处理流程与数据,每一个机位之间都是联动关系,这就需要一套可靠的任务分发机制保证每个机位的正常工作。
4.5 FFmpeg 英特尔硬件加速解决方案的实践

英特尔硬件加速解决方案包括以下四个部分:FFmpeg Decoder Plugins 支持纯硬件的视频解码,可充分利用英特尔GPU相关功能;FFmpeg Video Processing Plugins负责借助硬件加速优化YUV和ARGB 间的转换等视频处理;FFmpeg + OpenGL 3D Overlay用于整合解码视频与媒体分析这两种输出;FFmpeg Encoder plugin则利用英特尔GPU对由多路视频分析输出组成并以三维图形呈现的帧进行编码。
4.6 强调:并行计算
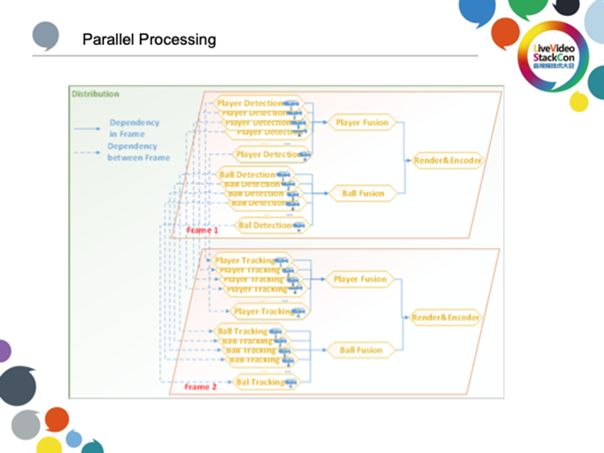
为什么采用并行策略?一场体育比赛需要的12个机位且机位之间是相互依赖的,系统只有等待12路数据全部处理完之后才能得出整个球场的实时动态。如果考虑时间轴上每一帧球场的动态变化则更为复杂,整套系统必须有一个高效的任务调度过程来处理多路视频,实现同步。
-
英特尔
+关注
关注
61文章
10321浏览量
181084 -
视频
+关注
关注
6文章
2013浏览量
75191 -
ffmpeg
+关注
关注
0文章
53浏览量
8026
原文标题:基于FFmpeg的运动视频分析
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论