 如何借鉴人类听觉系统,基于自编码器学习音频嵌入表示
如何借鉴人类听觉系统,基于自编码器学习音频嵌入表示

编者按:Kanda机器学习工程师Daniel Rothmann讲解了如何借鉴人类听觉系统,基于自编码器学习音频嵌入表示。
图片来源:Jonathan Gross
AI技术的显著突破都是通过建模人类系统达成的。尽管人工神经网络这一数学模型不过是从人类神经元运作的方式中获得了最初的启发,它们在解决复杂而含混的真实世界问题上的应用有目共睹。此外,建模人脑神经网络的架构深度为学习数据更多有意义表示开启了广泛的可能性。
在图像识别和处理领域,借鉴复杂而更具有空间不变性的视觉系统细胞的CNN大大改进了我们的技术。如果你有兴趣在音频频谱上应用图像识别技术,可以看下本系列的第二篇文章。
只要人类的感知能力超过机器,我们就能持续通过理解人类学习的原理而取得进展。人类非常擅长感知任务,特别是机器听觉这一领域,当前AI的表现与人类的差距明显。有鉴于视觉处理依靠借鉴人类系统得到的收获,我认为用于机器听觉的神经网络能够持续基于类似的过程得到改进。
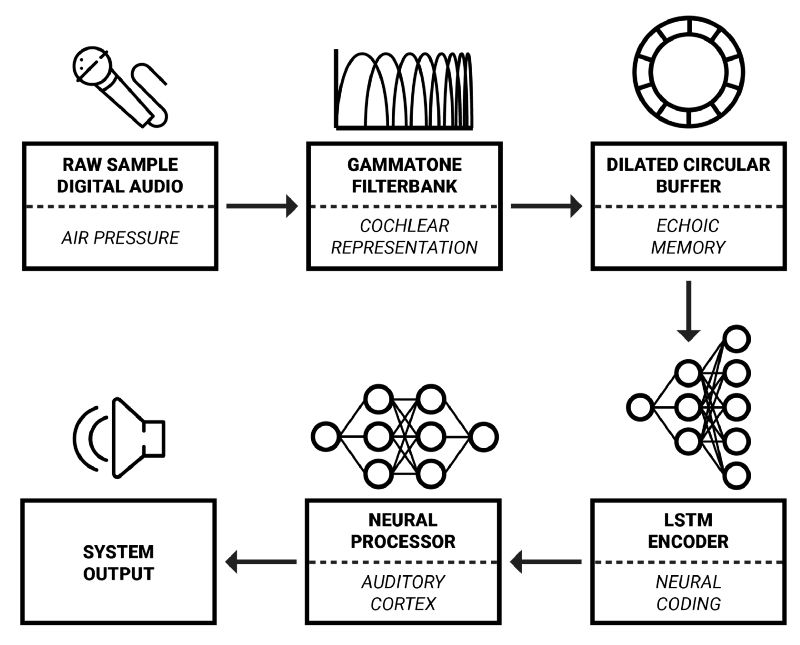
框架概览
在这一系列文章中,我将详细介绍奥胡斯大学和智能扬声器生产商Dynaudio A/S合作开发的实时音频信号处理框架。该框架的灵感主要来自于认知科学——试图结合生物学、神经科学、心理学、哲学以更好地理解我们的认知能力的科学。
认知声音性质
也许声音最抽象的一方面就是人类是如何感知它的。尽管信号处理问题的解答方案需要在低层操作强度、空间、时间性质的参数,但最终的目标常常是认知上的:以特定方式变换信号,调整声音的感知。
例如,如果有人想要通过编程的方式将说话录音的性别修改一下,那么在定义其低层属性之前,有必要先以更有意义的形式描述这一问题。说话人的性别可以被视作一个由多种因素决定的认知性质:嗓音的音高、音色,发音的不同,措辞的不同,以及通常人们如何理解这些性质和性别的关系。
这些参数可以通过强度、空间、时间性质之类的低层特征描述,但通过更复杂的组合它们才形成了高层表示。这形成了音频特性的层次结构,从中可以导出声音的“含义”。表示人类嗓音的认知性质可以看成声音的强度、空间、统计学性质的时域发展的组合模式。
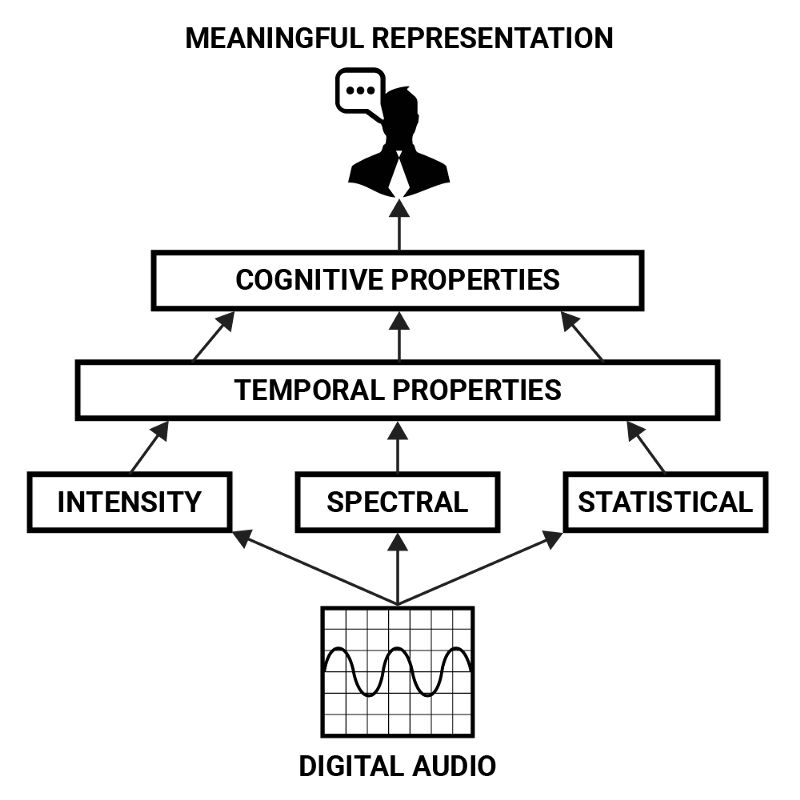
神经网络非常擅长提取数据的抽象表示,因此很适合检测声音的认知性质这一任务。为了构建达成这一目的的系统,让我们首先检视下人类听觉器官是如何表示声音的,供神经网络处理的声音表示可以从中得到借鉴。
耳蜗表示
人类的听觉始于外耳的耳廓。耳廓起到空间预处理的作用,取决于传入声音和听话人的相对方向,耳廓修改了传入的声音。接着,声音从耳廓的开口传入耳道。耳道通过共鸣进一步修改传入声音的空间特性,共鸣将放大1-6kHz中的频率1。
声波到达耳道尽头后刺激附着在鼓膜上的听小骨(人体内最小的骨头)。这些听小骨将耳道的压力传输到内耳中充满液体的耳蜗1。神经网络的声音表示对借鉴耳蜗很有兴趣,因为耳蜗正是人类负责将听觉振动转换为神经活动的器官。
耳蜗是由赖斯纳氏膜和基底膜分隔的盘管。耳蜗中有大约3500个内毛细胞1。随着压力传入耳蜗,耳蜗中的两道膜被下压。基底膜底部窄而硬,顶部宽而松,这样,特定频率上的回应自顶部至底部递增。
简单地说,基底膜可以被看成一组连续的带通滤波器,沿着基底膜区分出声音的频谱成分。
这就是人类转换声音压力至神经活动的主要机制。因此,我们有理由假设声音的空间表示对使用AI建模声音感知会有帮助。由于基底膜的频率响应呈指数变化2,对数频率表示可能是最高效的。我们可以使用gammatone滤波器组得到这样的表示。这些滤波器常用于建模听觉系统的空间过滤,因为它们近似revor函数。通过测量听觉神经纤维对白噪声刺激的响应,我们可以导出人类听觉过滤器的冲动响应函数,该函数被称为revor函数3。
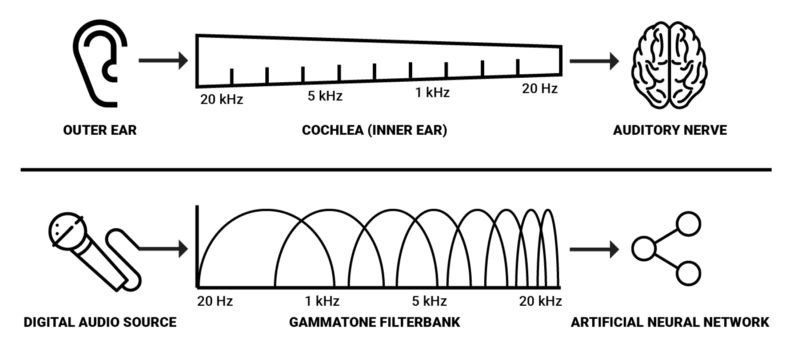
由于耳蜗具备大约3500个内毛细胞,而人类能够检测到约2-5毫秒的声音空隙1,空间解析度为3500的gammatone滤波器组搭配2毫秒的窗口看上去是在机器上达到类似人类的空间表示的最佳参数。然而,在实际场合,我觉得可以假定更低的解析度仍能在大多数分析和处理任务中取得所需效果,而且从算力的角度来说这样更可行。
网上有一些用于听觉分析的软件库。值得注意的一个例子是Jason Heeris的Gammatone Filterbank Toolkit。它提供了可供调整的滤波器,以及使用gammatone滤波器对音频信号进行频谱类分析的工具。
神经编码
在神经活动从耳蜗到听觉神经,沿着听觉通路传递的过程中,在达到听觉皮层之前,脑干核团对其进行了一系列处理。
这些处理形成了表示刺激和感知之间的接口的神经编码4。关于这些核团的特定内部工作机制的很多知识都是基于推测的,或者未知的,所以我将仅仅介绍核团的高层功能。
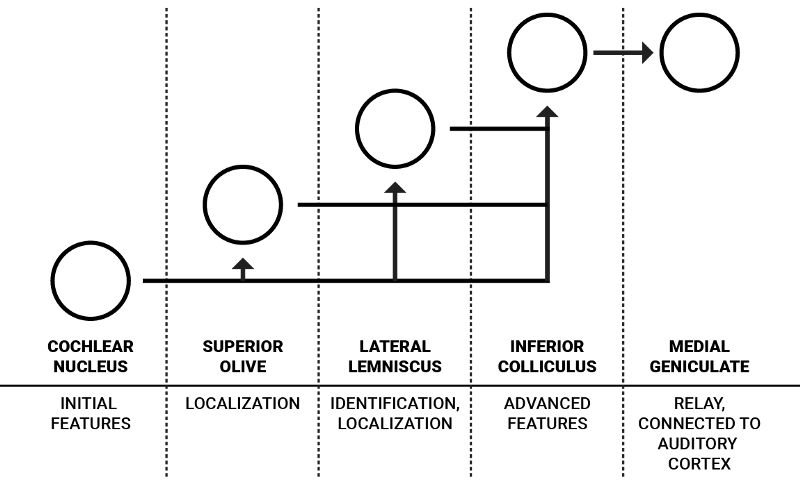
单耳听觉通路的简化示意图
人类每只耳朵都有一组核团,这些核团相互连接。不过,出于简单性,上图只画了单耳的流程。耳蜗核是来自听觉神经的神经信号的第一个编码步骤。它包含性质不同的各种神经元,对声音的特征进行初步处理,其中部分传向负责定位声音的上橄榄体,剩余部分传向和更高级特征相关的外侧丘系和下丘1。
J. J. Eggermont在“Between sound and perception: reviewing the search for a neural code”(声音和感知之间:神经编码研究回顾)一文中详细描述了耳蜗核中的信息流:“腹侧耳蜗核(VCN)提取并增强在听觉神经纤维的激活模式中多路传播的频率和时间信息,并将结果分配到两个通路:声音定位通路和声音识别通路。VCN的前部(AVCN)主要负责声音定位,它的两种多毛细胞为上橄榄复合体(SOC)提供输入,SOC在每个频率上分别映射双耳时间差(ITD)和强度差(ILD)。”4
声音识别通路传输的信息可以表示元音之类复杂的频谱。这一表示主要由腹侧耳蜗核中特殊类型的单元(梳齿型神经元)创建4。这些听觉编码的细节难以明确,但它们启发我们传入频率频谱的“编码”形式可能改善对低层声音特征的理解,也让神经网络处理声象不那么昂贵。
频谱声音编码
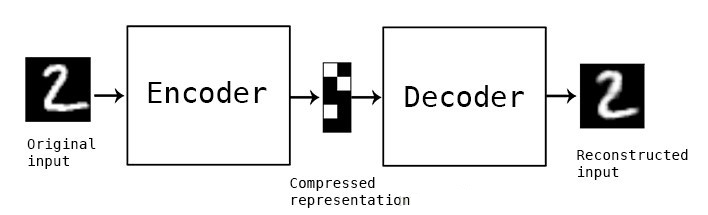
我们可以应用无监督自编码器神经网络架构来学习复杂频谱的常见性质。类似词嵌入,我们有可能找到频率频谱中的共性,这些共性表示声音的选定特征(或者高度压缩的含义)。
训练自编码器编码输入为压缩表示,该表示可以重建和输入高度相似的表示。这意味着自编码器的目标输出是输入自身5。如果输入可以在损失不大的情况下重建,那就说明网络学习到了所需编码方式,这一方式编码的内部压缩表示中包含足够多的有意义信息。我们将这一内部表示称为嵌入。自编码器的编码部分可以和解码器解耦,为其他应用生成嵌入。
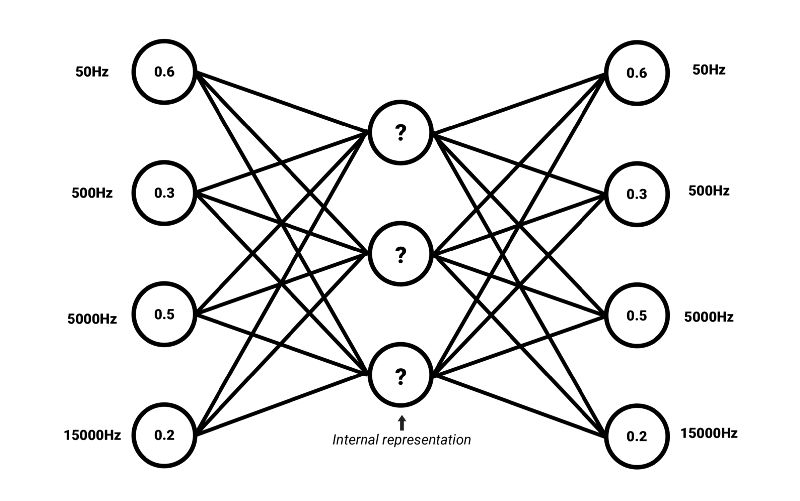
嵌入还有一个优势,嵌入常常比原始数据的维度要低。例如,自编码器可以将共有3500个值的频率频谱压缩为长度为500的向量。简单来说,这样的向量的每个值可以描述频谱的高层特征,例如元音、刺耳、谐波——这些只是举例,因为自编码器推导出的统计学共同因素的含义常常难以用简单的语言标记。
-
神经网络
+关注
关注
42文章
4840浏览量
108147 -
视觉系统
+关注
关注
3文章
384浏览量
31873 -
ai技术
+关注
关注
1文章
1314浏览量
25801
原文标题:机器听觉:三、基于自编码器学习声音嵌入表示
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于变分自编码器的异常小区检测
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

自编码器介绍
稀疏自编码器及TensorFlow实现详解
基于稀疏自编码器的属性网络嵌入算法SAANE
自编码器基础理论与实现方法、应用综述
一种多通道自编码器深度学习的入侵检测方法

基于变分自编码器的网络表示学习方法
基于自编码特征的语音声学综合特征提取
结合深度学习的自编码器端到端物理层优化方案
自编码器神经网络应用及实验综述
堆叠降噪自动编码器(SDAE)
自编码器 AE(AutoEncoder)程序




评论