 AlphaZero如何快速学习每个游戏,如何从随机对弈开始训练
AlphaZero如何快速学习每个游戏,如何从随机对弈开始训练
不仅会下围棋,还自学成才横扫国际象棋和日本将棋的DeepMind AlphaZero,登上了最新一期《科学》杂志封面。
同时,这也是经过完整同行审议的AlphaZero论文,首次公开发表。
论文描述了AlphaZero如何快速学习每个游戏,如何从随机对弈开始训练,在没有先验知识、只知道基本规则的情况下,成为史上最强大的棋类人工智能。
《科学》杂志评价称,能够解决多个复杂问题的单一算法,是创建通用机器学习系统,解决实际问题的重要一步。
DeepMind说,现在AlphaZero已经学会了三种不同的复杂棋类游戏,并且可能学会任何一种完美信息博弈的游戏,这“让我们对创建通用学习系统的使命充满信心”。
AlphaZero到底有多厉害?再总结一下。
在国际象棋中,AlphaZero训练4小时就超越了世界冠军程序Stockfish;
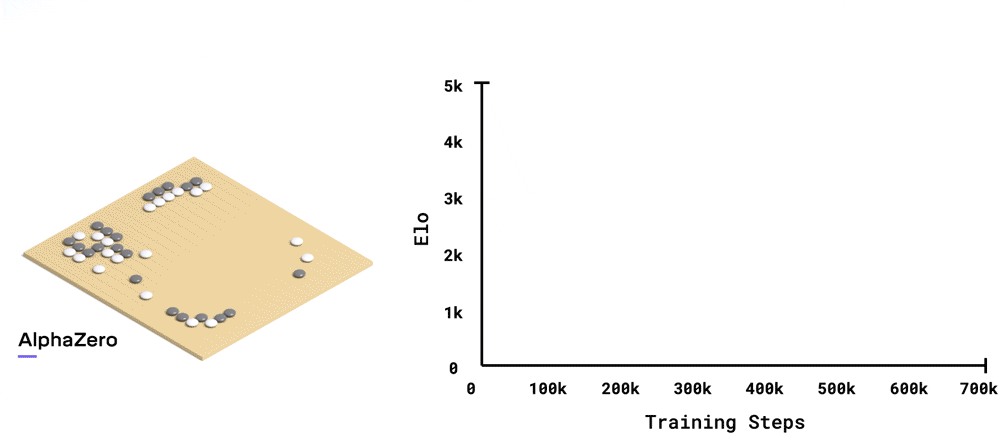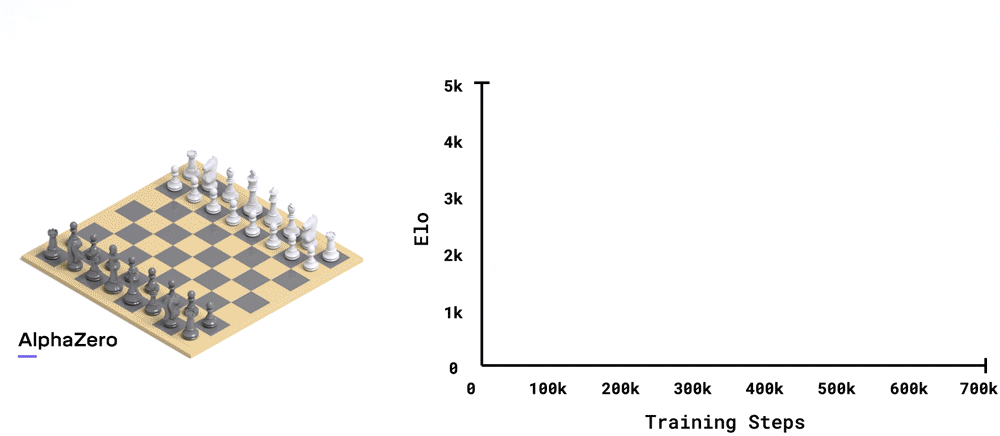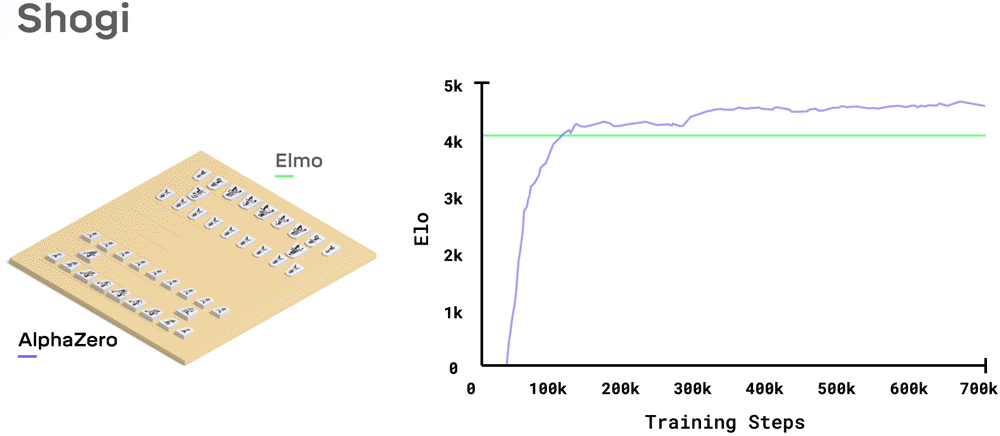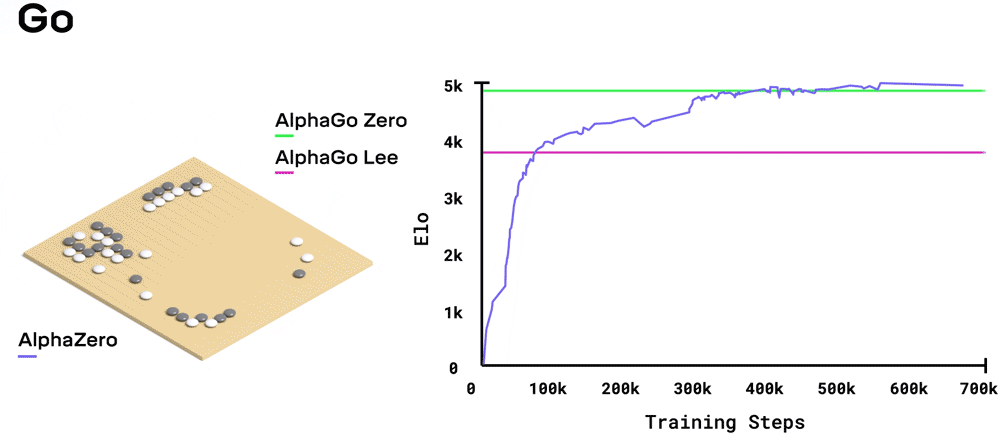
在日本将棋中,AlphaZero训练2小时就超越了世界冠军程序Elmo。
在围棋中,AlphaZero训练30小时就超越了与李世石对战的AlphaGo。
AlphaZero有什么不同
国际象棋有什么难的?
实际上,国际象棋是计算机科学家很早就开始研究的领域。1997年,深蓝击败了人类国际象棋冠军卡斯帕罗夫,这是一个人工智能的里程碑。此后20年,国际象棋的算法在超越人类后,一直还在不断地进步。
这些算法都是由强大的人类棋手和程序员构建,基于手工制作的功能和精心调整的权重来评估位置,并且结合了高性能的alpha-beta搜索。
而提到游戏树的复杂性,日本将棋比国际象棋还难。日本将棋程序,使用了类似国际象棋的算法,例如高度优化的alpha-beta搜索,以及许多有针对性的设置。
AlphaZero则完全不同,它依靠的是深度神经网络、通用强化学习算法和通用树搜索算法。除了基本规则之外,它对这些棋类游戏一无所知。
其中,深度神经网络取代了手工写就的评估函数和下法排序启发算法,蒙特卡洛树搜索(MCTS)算法取代了alpha-beta搜索。
AlphaZero深度神经网络的参数,通过自我博弈的强化学习来训练,从随机初始化的参数开始。
随着时间推移,系统渐渐从输、赢以及平局里面,学会调整参数,让自己更懂得选择那些有利于赢下比赛的走法。
那么,围棋和国际象棋、将棋有什么不同?
围棋的对弈结局只有输赢两种,而国际象棋和日本将棋都有平局。其中,国际象棋的最优结果被认为是平局。
此外,围棋的落子规则相对简单、平移不变,而国际象棋和日本将棋的规则是不对称的,不同的棋子有不同的下法,例如士兵通常只能向前移动一步,而皇后可以四面八方无限制的移动。而且这些棋子的移动规则,还跟位置密切相关。
尽管存在这些差异,但AlphaZero与下围棋的AlphaGo Zero使用了相同架构的卷积网络。
AlphaGo Zero的超参数通过贝叶斯优化进行调整。而在AlphaZero中,这些超参数、算法设置和网络架构都得到了继承。
除了探索噪声和学习率之外,AlphaZero没有为不同的游戏做特别的调整。
5000个TPU练出最强全能棋手
系统需要多长时间去训练,取决于每个游戏有多难:国际象棋大约9小时,将棋大约12小时,围棋大约13天。
只是这个训练速度很难复现,DeepMind在这个环节,投入了5000个一代TPU来生成自我对弈游戏,16个二代TPU来训练神经网络。
训练好的神经网络,用来指引一个搜索算法,就是蒙特卡洛树搜索 (MCTS) ,为每一步棋选出最有利的落子位置。
每下一步之前,AlphaZero不是搜索所有可能的排布,只是搜索其中一小部分。
比如,在国际象棋里,它每秒搜索6万种排布。对比一下,Stockfish每秒要搜索6千万种排布,千倍之差。
△每下一步,需要做多少搜索?
AlphaZero下棋时搜索的位置更少,靠的是让神经网络的选择更集中在最有希望的选择上。DeepMind在论文中举了个例子来展示。
上图展示的是在AlphaZero执白、Stockfish执黑的一局国际象棋里,经过100次、1000次……直到100万次模拟之后,AlphaZero蒙特卡洛树的内部状态。每个树状图解都展示了10个最常访问的状态。
经过全面训练的系统,就和各个领域里的最强AI比一比:国际象棋的Stockfish,将棋的Elmo,以及围棋的前辈AlphaGo Zero。
每位参赛选手都是用它最初设计中针对的硬件来跑的:
Stockfish和Elmo都是用44个CPU核;AlphaZero和AlphaGo Zero用的都是一台搭载4枚初代TPU和44个CPU核的机器。
(一枚初代TPU的推理速度,大约相当于一个英伟达Titan V GPU。)
另外,每场比赛的时长控制在3小时以内,每一步棋不得超过15秒。
比赛结果是,无论国际象棋、将棋还是围棋,AlphaGo都击败了对手:
国际象棋,大比分击败2016 TCEC冠军Stockfish,千场只输155场。
将棋,大比分击败2017 CSA世界冠军Elmo,胜率91.2%。
围棋,击败自学成才的前辈AlphaGo Zero,胜率61%。
不按套路落子
因为AlphaZero自己学习了每种棋类,于是,它并不受人类现有套路的影响,产生了独特的、非传统的、但具有创造力和动态的棋路。
在国际象棋里,它还发展出自己的直觉和策略,增加了一系列令人兴奋的新想法,改变了几个世纪以来对国际象棋战略的思考。
国际象棋世界冠军卡斯帕罗夫也在《科学》上撰文表示,AlphaZero具备动态、开放的风格,“就像我一样”。他指出通常国际象棋程序会追求平局,但AlphaZero看起来更喜欢风险、更具侵略性。卡斯帕罗夫表示,AlphaZero的棋风可能更接近本源。
卡斯帕罗夫说,AlphaZero以一种深刻而有用的方式超越了人类。
国际象棋大师马修·萨德勒(Matthew Sadler)和女性国际大师娜塔莎·里根(Natasha Regan)即将于2019年1月出版新书《棋类变革者(Game Changer)》,在这本书中,他们分析了数以千计的AlphaZero棋谱,认为AlphaZero的棋路不像任何传统的国际象棋引擎,马修·萨德勒评价它为“就像以前翻看一些厉害棋手的秘密笔记本。”
棋手们觉得,AlphaZero玩这些游戏的风格最迷人。
国际象棋特级大师马修·萨德勒说:“它的棋子带着目的和控制力包围对手的王的方式”,最大限度地提高了自身棋子的活动性和移动性,同时最大限度地减少了对手棋子的活动和移动性。
与直觉相反,AlphaZero似乎对“材料”的重视程度较低,这一想法是现代游戏的基础,每一个棋子都具有价值,如果玩家在棋盘上的某个棋子价值高于另一个,那么它就具有物质优势。AlphaZero愿意在游戏早期牺牲棋子,以获得长期收益。
“令人印象深刻的是,它设法将自己的风格强加于各种各样的位置和空缺,”马修说他也观察到,AlphaZero以非常刻意的方式发挥作用,一开始就以“非常人性化的坚定目标”开始。
“传统引擎非常强大,几乎不会出现明显错误,但在面对没有具体和可计算解决方案的位置时,会发生偏差,”他说。 “正是在这样的位置,AlphaZero才能体现出‘感觉’,‘洞察’或‘直觉’。”
这种独特的能力,在其他传统的国际象棋程序中看不到,并且已经给最近举办的世界国际象棋锦标赛提供了新的见解和评论。
“看看AlphaZero的分析与顶级国际象棋引擎甚至顶级大师级棋手的分析有何不同,这真是令人着迷,”女棋手娜塔莎·里根说。 “AlphaZero可以成为整个国际象棋圈强大的教学工具。”
AlphaZero的教育意义,早在2016年AlphaGo对战李世石时就已经看到。
在比赛期间,AlphaGo发挥出了许多极具创造性的胜利步法,包括在第二场比赛中的37步,这推翻了之前数百年的思考。这种下法以及其他许多下法,已经被包括李世石本人在内的所有级别的棋手研究过。
他对第37步这样评价:“我曾认为AlphaGo是基于概率计算的,它只是一台机器。但当我看到这一举动时,我改变了想法。当然AlphaGo是有创造性的。“
不仅仅是棋手
DeepMind在博客中说AlphaZero不仅仅是国际象棋、将棋或围棋。它是为了创建能够解决各种现实问题的智能系统,它需要灵活适应新的状况。
这正是AI研究中的一项重大挑战:系统能够以非常高的标准掌握特定技能,但在略微修改任务后往往会失败。
AlphaZero现在能够掌握三种不同的复杂游戏,并可能掌握任何完美信息游戏,解决了以上问题中重要的一步。
他们认为,AlphaZero的创造性见解,加上DeepMind在AlphaFold等其他项目中看到的令人鼓舞的结果,带来了创建通用学习系统的信心,有助于找到一些新的解决方案,去解决最重要和最复杂的科学问题。
DeepMind的Alpha家族从最初的围棋算法AlphaGo,几经进化,形成了一个家族。
刚提到的AlphaFold,最近可以说关注度爆表。
它能根据基因序列来预测蛋白质的3D结构,还在有“蛋白质结构预测奥运会”之称的CASP比赛中夺冠,力压其他97个参赛者。这是“证明人工智能研究驱动、加速科学进展重要里程碑”,DeepMInd CEO哈萨比斯形容为“灯塔”。
从2016年AlphaGo论文发表在《自然》上,到今天AlphaZero登上《科学》,Alpha家族除了最新出炉的AlphaFold之外,AlphaGo、AlphaGo Zero和AlphaZero已经全部在顶级期刊Nature和Science上亮相。
期待轰动科研界的AlphaFold论文早日露面。
AlphaZero论文
这篇刊载在《科学》上的论文,题为:
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
作者包括:David Silver、Thomas Hubert、Julian Schrittwieser、Ioannis Antonoglou、Matthew Lai、Arthur Guez、Marc Lanctot、Laurent Sifre、Dharshan Kumaran、Thore Graepel、Timothy Lillicrap、Karen Simonyan、Demis Hassabis。
《科学》刊载的论文在此:http://science.sciencemag.org/content/362/6419/1140
棋局可以在此下载:https://deepmind.com/research/alphago/alphazero-resources/
DeepMind还特别写了一个博客,传送门:https://deepmind.com/blog/alphazero-shedding-new-light-grand-games-chess-shogi-and-go/
-
神经网络
+关注
关注
42文章
4771浏览量
100701 -
人工智能
+关注
关注
1791文章
47182浏览量
238179 -
机器学习
+关注
关注
66文章
8406浏览量
132549
原文标题:AlphaZero登上《科学》封面:一个算法“通杀”三大棋,完整论文首次发布
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何才能高效地进行深度学习模型训练?
AlphaGo为何精通围棋?围棋论文曝光【中文翻译】-原来它是这样深度学习和思考的,难怪老赢!
如何在基于Arm的设备上运行游戏AI呢
谷歌发布新版AlphaGo,对弈自我学习,已击败柯洁系统
随机块模型学习算法
史上最强棋类AI降临!也是迄今最强的棋类AI——AlphaZero
Python随机数模块的随机函数使用

基于预训练模型和长短期记忆网络的深度学习模型






 工商网监
工商网监
评论