 数据科学高效工具:feature-selector,帮你快速完成特征选择
数据科学高效工具:feature-selector,帮你快速完成特征选择
▍前言
本篇主要介绍一个基础的特征选择工具feature-selector,feature-selector是由Feature Labs的一名数据科学家williamkoehrsen写的特征选择库。feature-selector主要对以下类型的特征进行选择:
具有高missing-values百分比的特征
具有高相关性的特征
对模型预测结果无贡献的特征(即zero importance)
对模型预测结果只有很小贡献的特征(即low importance)
具有单个值的特征(即数据集中该特征取值的集合只有一个元素)
从上面可以看出feature-selector确实是非常基础的特征选择工具,正因为非常的基础,所以才非常的常用(这也是为什么williamkoehrsen要写这个特征选择库的原因),在拿到一个数据集的时候,往往都需要将上述类型的特征从数据集中剔除掉。针对上面五种类型的特征,feature-selector分别提供以下五个函数来对此处理:
identify_missing(*)
identify_collinear(*)
identify_zero_importance(*)
identify_low_importance(*)
identify_single_unique(*)
▍数据集选择
在这里使用kaggle上的训练数据集。原训练数据集稍微有点大,30+万行(150+MB),pandas导入数据都花了一点时间,为此我从原数据集中采样了1万+行数据作为此次练习的数据集。数据集采样代码如下:
https://www.kaggle.com/c/home-credit-default-risk/data
importpandasaspddata=pd.read_csv('./appliation_train.csv')#从原数据中采样5%的数据sample=data.sample(frac=0.05)#重新创建索引sample.reset_index(drop=True)#将采样数据存到'application_train_sample.csv'文件中sample.to_csv('./application_train_sample.csv')
▍feature-selector用法
导入数据并创建feaure-selector实例
importpandasaspd#注意:#作者并没有把feature-selector发布到pypi上,所以不能使用pip和conda进行安装,只能手动#从github下载下来,然后把feature_selector.py文件放到当前工作目录,然后再进行import操作。fromfeature_selectorimportFeatureSelectordata=pd.read_csv('./application_train_sample.csv',index_col=0)#数据集中TARGET字段为对应样本的labeltrain_labels=data.TARGET#获取allfeaturestrain_features=data.drop(columns='TARGET')#创建feature-selector实例,并传入features和labelsfs=FeatureSelector(data=train_features,lables=train_labels)1
特征选取方法
(1)identify_missing
该方法用于选择missing value 百分比大于指定值(通过missing_threshold指定百分比)的feature。该方法能应用于监督学习和非监督学习的特征选择。
#选择出missingvalue百分比大于60%的特征fs.identify_missing(missing_threshold=0.6)#查看选择出的特征fs.ops['missing']#绘制所有特征missingvalue百分比的直方图fs.plot_missing()
图1. 所有特征missing value百分比的直方图
该方法内部使用pandas 统计数据集中所有feature的missing value 的百分比,然后选择出百分比大于阈值的特征,详见feature-selector.py的114-136行。
https://github.com/WillKoehrsen/feature-selector/blob/master/feature_selector/feature_selector.py#L114-L136
(2) identify_collinear
该方法用于选择相关性大于指定值(通过correlation_threshold指定值)的feature。该方法同样适用于监督学习和非监督学习。
#不对feature进行one-hotencoding(默认为False),然后选择出相关性大于98%的feature,fs.identify_collinear(correlation_threshold=0.98,one_hot=False)#查看选择的featurefs.ops['collinear']#绘制选择的特征的相关性heatmapfs.plot_collinear()#绘制所有特征的相关性heatmap
图2. 选择的特征的相关矩阵图
图3. 所有特征相关矩阵图
该方法内部主要执行步骤如下:
1.根据参数'one_hot'对数据集特征进行one-hot encoding(调用pd.get_dummies方法)。如果'one_hot=True'则对特征将进行one-hot encoding,并将编码的特征与原数据集整合起来组成新的数据集,如果'one_hot=False'则什么不做,进入下一步;
2.计算步骤1得出数据集的相关矩阵C(通过DataFrame.corr(),注意 C也为一个DateFrame),并取相关矩阵的上三角部分得到 C_upper;
3.遍历C_upper的每一列(即每一个特征),如果该列的任何一个相关值大于correlation_threshold,则取出该列,并放到一个列表中(该列表中的feature,即具有high 相关性的特征,之后会从数据集去除);
4.到这一步,做什么呢?回到源码看一波就知道了;
具体请见feature-selector.py的157-227行。
(3) identify_zero_importance
该方法用于选择对模型预测结果毫无贡献的feature(即zero importance,从数据集中去除或者保留该feature对模型的结果不会有任何影响)。
该方法以及之后的identify_low_importance都只适用于监督学习(即需要label,这也是为什么实例化feature-selector时需要传入labels参数的原因)。feature-selector通过用数据集训练一个梯度提升机(Gradient Boosting machine, GBM),然后由GBM得到每一个feature的重要性分数,对所有特征的重要性分数进行归一化处理,选择出重要性分数等于零的feature。
为了使计算得到的feature重要性分数具有很小的方差,identify_zero_importance内部会对GBM训练多次,取多次训练的平均值,得到最终的feature重要性分数。同时为了防止过拟合,identify_zero_importance内部从数据集中抽取一部分作为验证集,在训练GBM的时候,计算GBM在验证集上的某一metric,当metric满足一定条件时,停止GBM的训练。
#选择zeroimportance的feature,##参数说明:#task:'classification'/'regression',如果数据的模型是分类模型选择'classificaiton',#否则选择'regression'#eval_metric:判断提前停止的metric.forexample,'auc'forclassification,and'l2'forregressionproblem#n_iteration:训练的次数#early_stopping:True/False,是否需要提前停止fs.identify_zero_importance(task='classification',eval_metric='auc',n_iteration=10,early_stopping=True)#查看选择出的zeroimportancefeaturefs.ops['zero_importance']#绘制featureimportance关系图#参数说明:#plot_n:指定绘制前plot_n个最重要的feature的归一化importance条形图,如图4所示#threshold:指定importance分数累积和的阈值,用于指定图4中的蓝色虚线.#蓝色虚线指定了importance累积和达到threshold时,所需要的feature个数。#注意:在计算importance累积和之前,对feature列表安装featureimportance的大小#进行了降序排序fs.plot_feature_importances(threshold=0.99,plot_n=12)
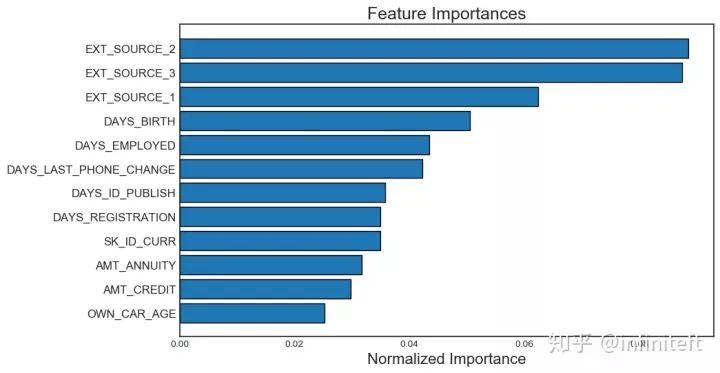
图4. 前12个最重要的feature归一化后的importance分数的条形图
图5. feature 个数与feature importance累积和的关系图
需要注意GBM训练过程是随机的,所以每次运行identify_zero_importance得到feature importance分数都会发生变化,但按照importance排序之后,至少前几个最重要的feature顺序不会变化。
该方法内部主要执行了以下步骤:
1.对各个feature进行one-hot encoding,然后将one-hot encoding的feature和原数据集合并成新的数据集(使用pd.get_dummies完成);
2.根据参数 task 的取值,实例化lightgbm.LGBMClassifier, 或者实例化 lightgbm.LGBMRegressor model;
3.根据early_stopping的取值选择是否需要提前停止训练,并向model.fit传入相应的参数,然后开始训练model;
4.根据model得到该次训练的feature importance;
5.执行n_iterations次步骤1-4;
6.取多次训练的feature importance的平均值,得到最终的feature importance;
7.选择出feature importance等于0的feature;
8.到这一步,主要步骤完成了,其他部分请查看源码。
具体请见feature-selector.py的229-342行。
(4) identify_low_importance
该方法是使用identify_zero_importance计算的结果,选择出对importance累积和达到指定阈值没有贡献的feature(这样说有点拗口),即图5中蓝色虚线之后的feature。该方法只适用于监督学习。identify_low_importance有点类似于PCA中留下主要分量去除不重要的分量。
#选择出对importance累积和达到99%没有贡献的featurefs.identify_low_importance(cumulative_importance=0.99)#查看选择出的featurefs.ops['low_importance']
该方法选择出的feature其实包含了zero importance的feature。内部实现没什么可说的,具体请见feature-selector.py的344-378行。
(5) identify_single_unique
该方法用于选择只有单个取值的feature,单个值的feature的方差为0,对于模型的训练不会有任何作用(从信息熵的角度看,该feature的熵为0)。该方法可应用于监督学习和非监督学习。
#选择出只有单个值的featurefs.identify_single_unique()#查看选择出的featurefs.ops['single_unique']#绘制所有featureuniquevalue的直方图fs.plot_unique()
图6. 所有feature unique value的直方图
该方法内部的内部实现很简单,只是通过DataFrame.nunique方法统计了每个feature取值的个数,然后选择出nunique==1等于1的feature。具体请见feature-selector.py的138-155行。
从数据集去除选择的特征
上面介绍了feature-selector提供的特征选择方法,这些方法从数据集中识别了feature,但并没有从数据集中将这些feature去除。feature-selector中提供了remove方法将选择的特征从数据集中去除,并返回去除特征之后的数据集。
#去除所有类型的特征#参数说明:#methods:#desc:需要去除哪些类型的特征#type:string/list-likeobject#values:'all'或者是['missing','single_unique','collinear','zero_importance','low_importance']#中多个方法名的组合#keep_one_hot:#desc:是否需要保留one-hotencoding的特征#type:boolean#values:True/False#default:Truetrain_removed=fs.remove(methods='all',keep_one_hot=False)
注意:调用remove函数的时候,必须先调用特征选择函数,即identify_*函数。
该方法的实现代码在feature-selector.py的430-510行。
一次性选择所有类型的特征
feature-selector除了能每次运行一个identify_*函数来选择一种类型特征外,还可以使用identify_all函数一次性选择5种类型的特征选。
#注意:#少了下面任何一个参数都会报错,raiseValueErrorfs.identify_all(selection_params= {'missing_threshold':0.6,'correlation_threshold':0.98,'task':'classification','eval_metric':'auc','cumulative_importance':0.99})
▍总结
feature-selector属于非常基础的特征选择工具,它提供了五种特征的选择函数,每个函数负责选择一种类型的特征。一般情况下,在对某一数据集构建模型之前,都需要考虑从数据集中去除这五种类型的特征,所以feature-selector帮你省去data-science生活中一部分重复性的代码工作。
如果有兴趣和充足的时间,建议阅读一下feature-selector的代码,代码量很少,七百多行,相信看了之后对feature-selector各个函数的实现思路以及相应代码实现有一定认识,有心者还可以贡献一下自己的代码。
-
函数
+关注
关注
3文章
4333浏览量
62708 -
数据集
+关注
关注
4文章
1208浏览量
24726
原文标题:一款非常棒的特征选择工具:feature-selector
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
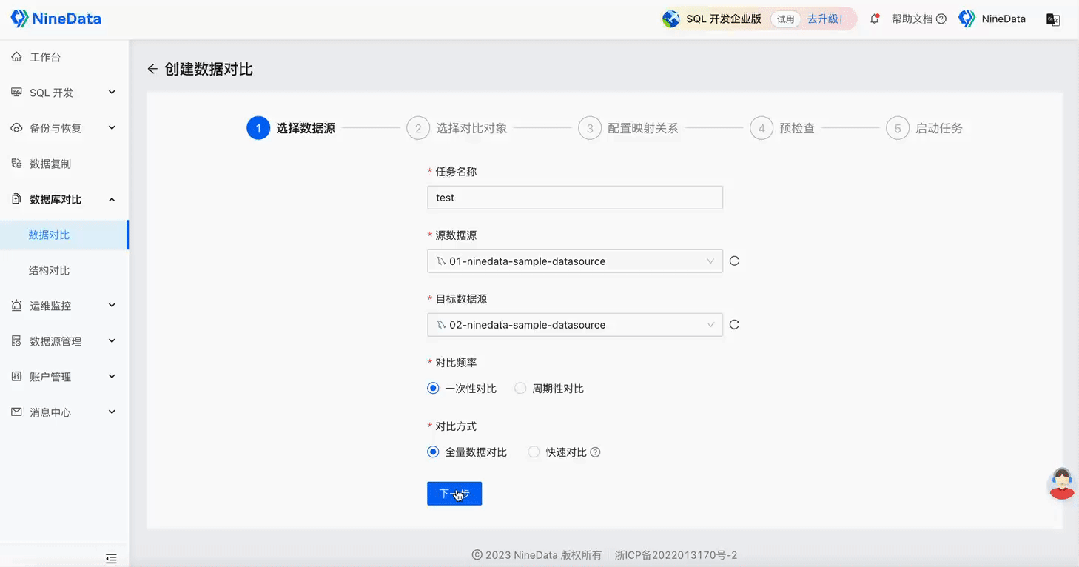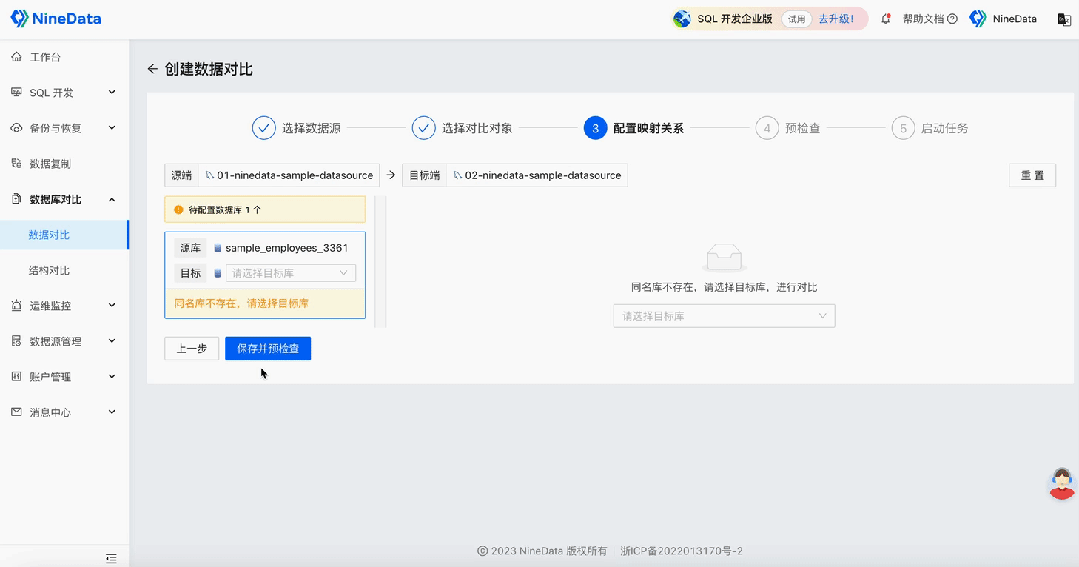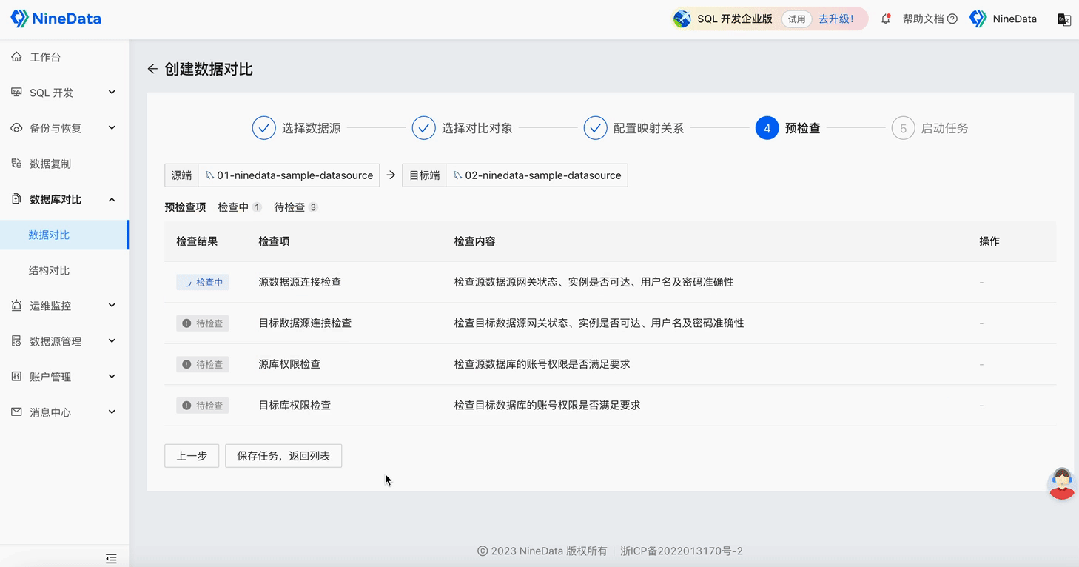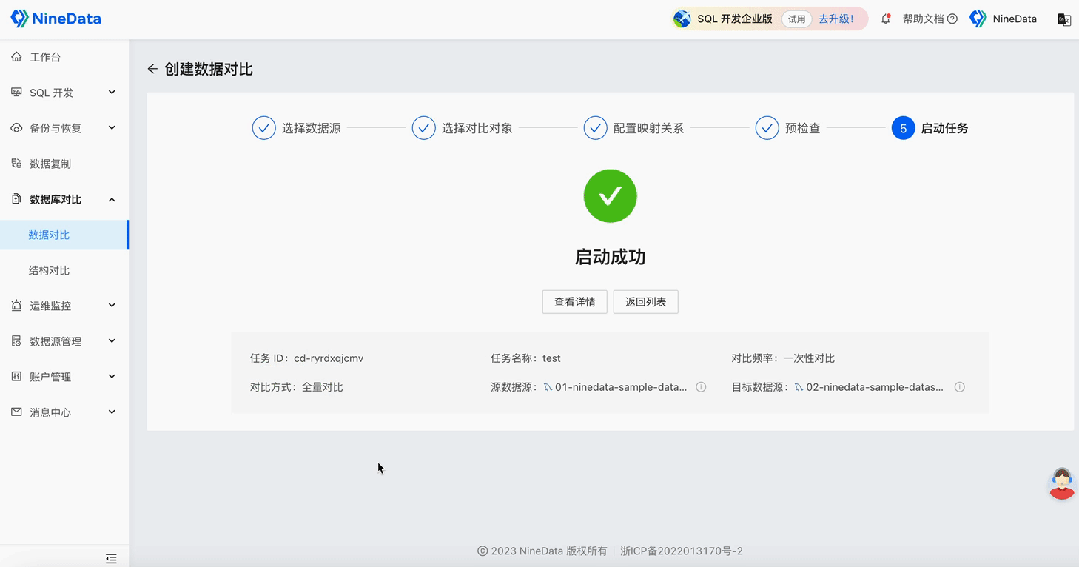
使用NineData快速完成MySQL数据的差异对比!
机器视觉的Gabor Feature特征表达

十大机器学习工具及数据科学工具
数据科学的工具数不胜数——你应该选择哪一个?
机器学习之特征提取 VS 特征选择


合泰半导体全新发布MCU Selector App选型工具

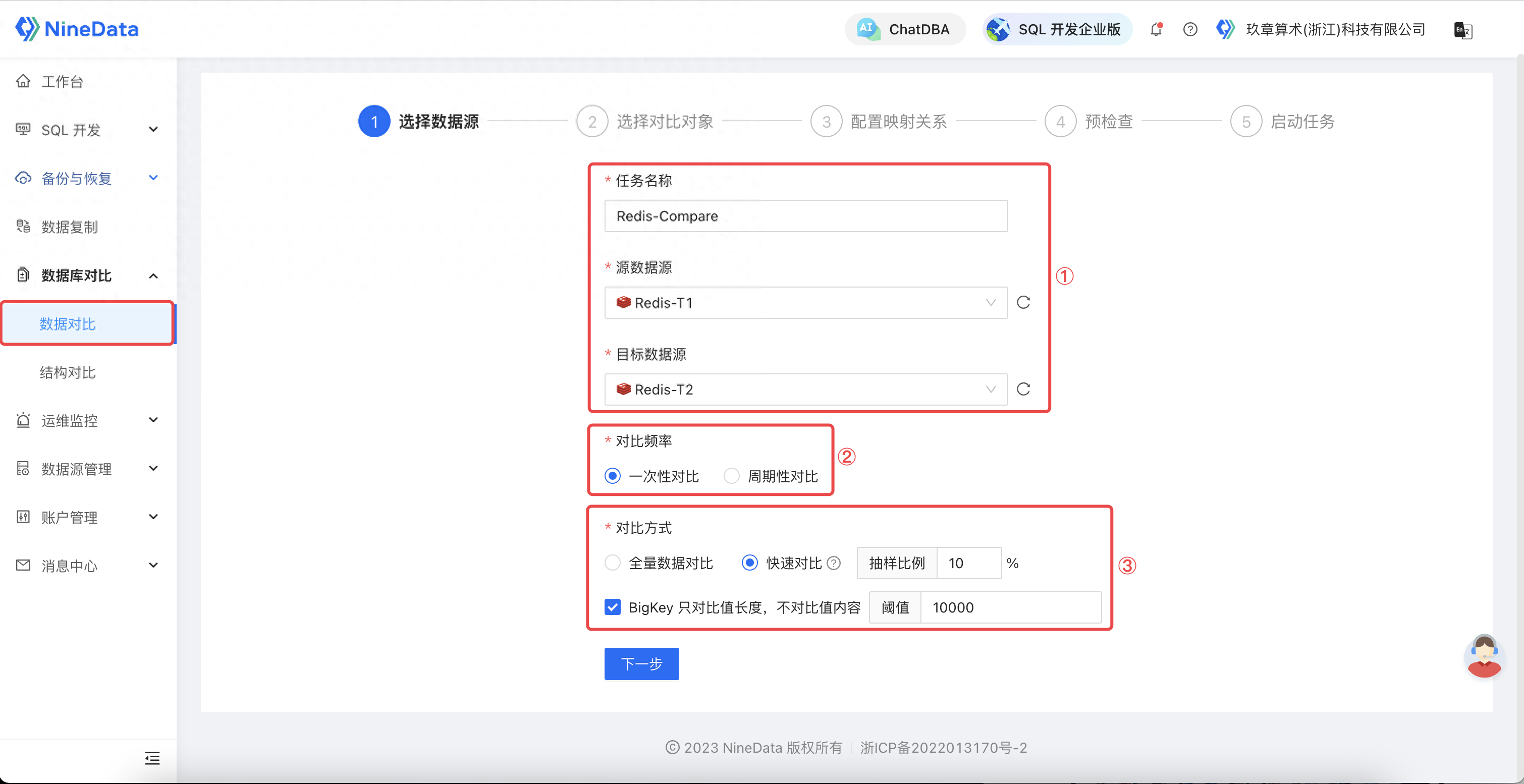
使用NineData快速、高效完成Redis差异数据对比!





 工商网监
工商网监
评论