 探析自然语言处理中的深度迁移学习
探析自然语言处理中的深度迁移学习
如何让文本也像图片一样经过预训练?这是一份通用句子编码器的神秘指南。
简介
迁移学习是一个令人兴奋的概念,我们试图利用先验知识从一个领域和任务到另一个领域和任务。灵感来自我们人类本身,我们有一种与生俱来的能力,即不从零开始学习所有东西。我们从过去学到的知识中转移和利用我们的知识来处理各种各样的任务。有了计算机视觉,我们就有了优秀的大型数据集,比如ImageNet,在它之上我们可以获得一套世界级的、最先进的预训练模型来利用迁移学习。但是自然语言处理呢?考虑到文本数据是如此的多样化、充斥着噪音以及非结构化的特点,这是一个严峻的挑战。我们最近在文本嵌入方面取得了一些成功,包括Word2vec、GloVe 和 FastText 等方法,我在关于“文本数据的特征工程”[1]的文章中介绍了所有这些方法。
在这篇文章中,我们将展示几种最先进的通用句子嵌入编码器,特别是在迁移学习任务的少量数据上与 Word embedding 模型相比的情况下,它们往往会给出令人惊讶的良好性能。
我们将尝试涵盖基本概念,并展示一些利用python和TensorFlow的手工操作示例,在文本分类问题中侧重于情感分析的案例。
为什么我们对嵌入(embedding)如此疯狂?
嵌入是一个固定长度的向量,通常用于编码和表示一个实体(文档、句子、单词、图形)
我在前一篇文章[2]中谈到了在文本数据和NLP上下文中嵌入的必要性。但为了方便起见,我将在这里简短地重复一下。在语音或图像识别系统方面,我们已经以丰富的密集特征向量的形式获得信息,这些特征向量嵌入在高维数据集中,如音频谱图和图像像素强度。然而,当涉及到原始文本数据时,特别是基于计数的模型,比如词袋模型(Bag of words),我们处理的是单个单词,它们可能有自己的标识符,并且不捕获单词之间的语义关系。这就导致了文本数据的大量稀疏词向量,因此如果我们没有足够的数据,我们可能会因为维度诅咒而得到很糟糕的模型,甚至过拟合数据。
对比图片、音频、文本的特征表示
预测方法(predictive methods),比如基于神经网络的语言模型,试图从其相邻的单词中预测单词,观察语料库中的单词序列,在学习分布式表示的过程中,给我们提供稠密的单词嵌入表示。
现在你可能在想,我们从文本中得到了一堆向量,现在怎么办?如果我们有一个很好的文本数据的数字表示,它甚至捕捉到上下文和语义,我们可以将它用于各种各样的下游现实世界任务,比如情感分析、文本分类、聚类、摘要、翻译等等。事实上,机器学习或深度学习模型能在这些数字和嵌入表示上运行,是编码这些模型使用的文本数据的关键。
文本嵌入
这里的一个大趋势是找出所谓的“通用嵌入(universal embeddings)”,它基本上是通过在一个庞大的语料库上训练深度学习模型而获得的预训练的嵌入表示。这使我们能够在各种各样的任务中使用这些经过预训练的(一般的)嵌入表示,包括缺乏足够数据等约束的场景。这是迁移学习的一个完美例子,利用预训练嵌入表示的先验知识来解决一个全新的任务!下图显示了通用词嵌入(word embedding)和句子嵌入(sentence embedding)的一些最新趋势。
最近在通用词&句子嵌入的趋势
来源:https://medium.com/huggingface/universal-word-sentence-embeddings-ce48ddc8fc3a)
上图中有一些有趣的趋势,包括谷歌的通用句子编码器,我们将在本文中详细探讨。现在,让我们在深入研究通用句子编码器之前,简要介绍单词和句子嵌入模型的趋势和发展。
词嵌入模型的发展趋势
词嵌入模型(Word Embedding Models)是一些比较成熟的模型,这些模型是从2013年的Word2vec开始发展的。基于语义和上下文相似性的连续向量空间嵌入词向量的三种最常见的利用深度学习(无监督方法)的模型是:
Word2Vec
GloVe
FastText
这些模型是基于分布语义学领域中的分布假设原理而建立的,它告诉我们,在相同的语境中发生和使用的词在语义上是相似的,具有相似的意义。
最近发展起来的这一领域的另一个有趣的模型是由Allen人工智能研究所(Allen Institute for Artificial Intelligence)开发的ELMo(Embeddings from Language Models)模型。
基本上,ELMo给我们提供了从深度双向语言模型(biLM)中学习的单词嵌入,该模型通常是在大型文本语料库上进行预训练,从而使迁移学习和这些嵌入能够跨不同的NLP任务使用。Allen AI告诉我们,ELMo表示是上下文感知的、深度的和基于字符的,它使用形态学线索来形成表示,甚至对于OOV(out-of-vocabulary)标记也是如此。
通用句子嵌入模型的发展趋势
句子嵌入(Sentence Embedding)的概念并不是一个非常新的概念,因为在构建词嵌入时,最简单的方法之一就是用平均法构建baseline句子嵌入模型。
一个baseline句子嵌入模型可以通过平均每个句子的单个词嵌入(有点类似于我们失去了句子中固有的语境和单词序列的bag of words)来建立。下图显示了实现此功能的方法。

当然,还有一些更复杂的方法,比如对句子中的词嵌入表示进行线性加权组合。
Doc2Vec也是 mikolov 等人提出的一种非常流行的方法。他们提出了段落向量,这是一种无监督的算法,它从可变长度的文本 (如句子、段落和文档) 中学习固定长度的特征嵌入。
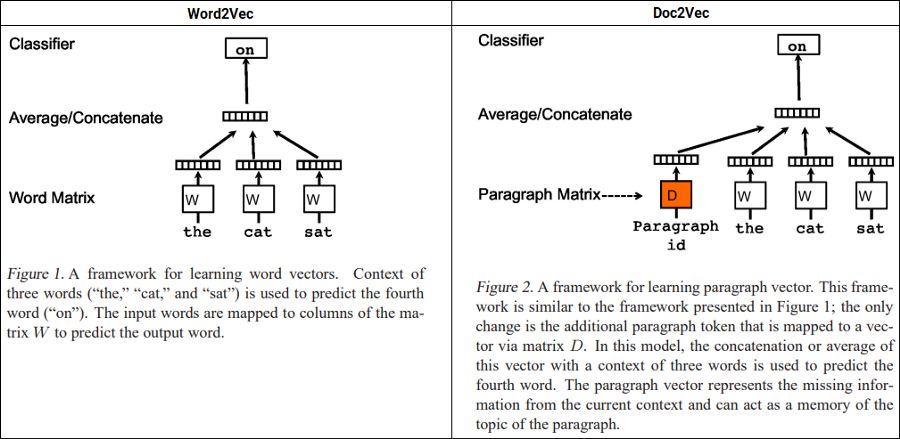
Word2Vec vs. Doc2Vec (Source:https://arxiv.org/abs/1405.4053)
在上述描述的基础上,该模型用一个稠密向量表示每个文档,该向量训练用于预测文档中的单词,唯一的区别是使用段落或文档id与常规单词tokens一起构建嵌入表示。这样的设计使这种模型克服了词袋模型的缺点。
神经网络语言模型(NNLM)是 Bengio 等人在2003年提出的。他们讨论学习单词的分布式表示,允许每个训练句子向模型提供关于语义相邻句子的信息。该模型同时学习每个单词的分布式表示,同时学习词序列的概率函数,并以这些形式表示出来。泛化是因为一个以前从未见过的单词序列,如果它是由类似于构成一个已经出现过的句子的单词构成的词构成的,那么它就具有很高的概率。
Google已经建立了一个通用的句子嵌入模型nnlm-en-dim128[3],这是一种基于标记的文本嵌入,使用三层前馈神经网络语言模型在英语google新闻200B语料库上进行训练。该模型将任意文本映射为128维嵌入。我们很快就会在接下来演示中用到这个。
Skip-Thought Vectors也是基于非监督学习的句子编码器领域中最早的模型之一。在他们提议的论文中,利用文本的连续性,他们训练了一个编码器-解码器模型,试图重建编码段落的周围句子。共享语义和句法属性的句子被映射到类似的向量表示。
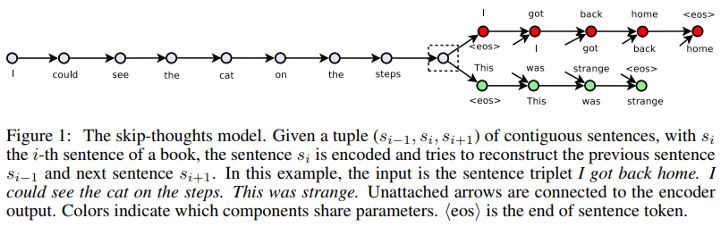
Skip-Thought Vectors (Source:https://arxiv.org/abs/1506.06726)
这就像skip-gram模型,但是是针对于句子而言的,即我们试图预测给定源句子的周围句子。
Quick Thought Vectors是最近用来学习句子表达的一种较新的方法。原论文中详细介绍了学习句子表示的有效框架。有趣的是,他们通过在常规的编解码结构中用分类器替换解码器,把预测句子出现的上下文的问题重新定义为分类问题。
Quick Thought Vectors (Source:https://openreview.net/forum?id=rJvJXZb0W)
因此,给定一个句子及其出现的上下文,分类器根据它们的嵌入表示来区分上下文句子和其他对比句子。给定一个输入语句,它首先使用某种函数进行编码,但是模型没有生成目标句子,而是从一组候选句子中选择正确的目标句子。将生成看作是从所有可能的句子中选择一个句子,这可以看作是对生成问题的一种判别近似。
InferSet是一种基于自然语言推理数据学习通用句子嵌入的有监督学习方法。这是硬核监督迁移学习,就像我们在ImageNet数据集上接受计算机视觉训练一样,他们使用斯坦福自然语言推理数据集的监督数据来训练通用句子表示。该模型使用的数据集是由570 k人工生成的英语句子对组成的SNLI数据集,它捕捉到了理解句子语义的自然语言推理。
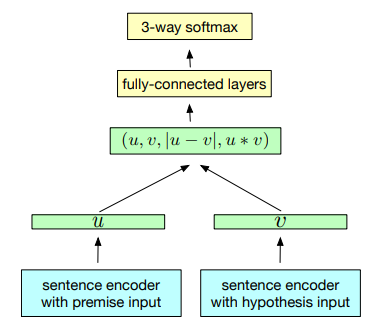
InferSent training scheme (Source:https://arxiv.org/abs/1705.02364)
基于上图所描述的体系结构,我们可以看到,它使用了一个共享语句编码器,它为前提u和假设V输出一个表示。一旦生成句子向量,就可以使用3种匹配方法来提取u和v之间的关系:
Concatenation (u, v)
Element-wise product u ∗ v
Absolute element-wise difference |u − v|
生成的向量随后被输入由多个全连接的层组成的三分类器。
Google的通用句子编码器Universal Sentence Encoder是最新的、最好的通用句子嵌入模型之一,于2018年初发布。通用句子编码器将任意文本编码成512维嵌入,可用于各种NLP任务,包括文本分类、语义相似性和聚类。它针对各种数据源和各种任务进行训练,目的是动态地容纳各种各样的自然语言理解任务,这些任务需要对单词序列的含义进行建模,而不仅仅是单个单词。他们的主要发现是,使用句子嵌入的迁移学习往往优于词嵌入级别的迁移学习。
理解我们的文本分类问题
现在是时候把这些通用的句子编码器付诸行动了,接下来我们进行演示。我们今天演示集中于一个非常流行的NLP任务,即在情感分析的背景下对文本进行分类。下文演示中所用的数据集可以在[4]或[5]中下载。
这个数据集共有50000部电影评论,其中25k有正面情绪,25k有负面情绪。我们将在总共30000次评论上训练我们的模型,在5000个评论上进行交叉验证,并使用15000次评论作为我们的测试数据集。主要目的是正确预测每一次评价的积极或消极情绪。
通用句子嵌入in action
现在我们已经明确了我们的主要目标,让我们把通用的句子编码器付诸行动!我的设置是一个8CPU,30 GB,250 GB的SSD和一个Nvidia Quadro P4000。
加载包
我们从安装tensorflow-hub开始,它使我们能够轻松地使用这些句子编码器。

Ok,接下来加载本教程要用到的模块:
importtensorflowastfimporttensorflow_hubashubimportnumpyasnpimportpandasaspd
下面的命令帮助你检查TensorFlow是否将使用GPU(如果您已经设置了一个GPU):
In [12]: tf.test.is_gpu_available()Out[12]: TrueIn [13]: tf.test.gpu_device_name()Out[13]: '/device:GPU:0'
加载和查看数据集
我们现在可以加载数据集并使用pandas查看它。


我们将情感表示的列编码为1和0。


我们的电影评论数据集
构建训练、验证和测试数据集
在开始建模之前,我们将创建训练、验证和测试数据集。我们将使用30000条评论用于训练,5000条用于验证,15000条用于测试。你可以使用train_test_split() from scikit-learn。我只是很懒,用简单的列表切片对数据集进行了细分。

((30000,), (5000,), (15000,))
基本文本处理
我们有一些基本的文本预处理需要做,以从我们的文本消除一些噪音,如不必要的特殊字符,html标签的清除等。

下面的代码帮助我们构建一个简单而有效的文本系统。
现在让我们使用上面实现的函数对数据集进行预处理。

构建数据摄取函数
由于我们将使用tf.estimator API在TensorFlow中实现我们的模型,因此我们需要定义一些函数来构建数据和特性工程pipline,以便在训练期间将数据输入到我们的模型中。我们利用numpy_put_fn(),这有助于将大量的numpy数组输入到模型中。

我们现在已经准备好建立我们的模型了!
用通用句子编码器建立深度学习模型
在建立模型之前,首先要定义利用通用句子编码器的语句嵌入特征。我们可以使用下面的代码来实现这一点。

INFO:tensorflow:Using /tmp/tfhub_modules tocache modules.
我们将建立一个简单只有两个隐层的前馈DNN,现在只是一个标准的模型,没有太复杂,因为我们想看看这些嵌入在一个简单的模型上执行得有多好。在这里,我们正在利用预训练嵌入形式的迁移学习方法。
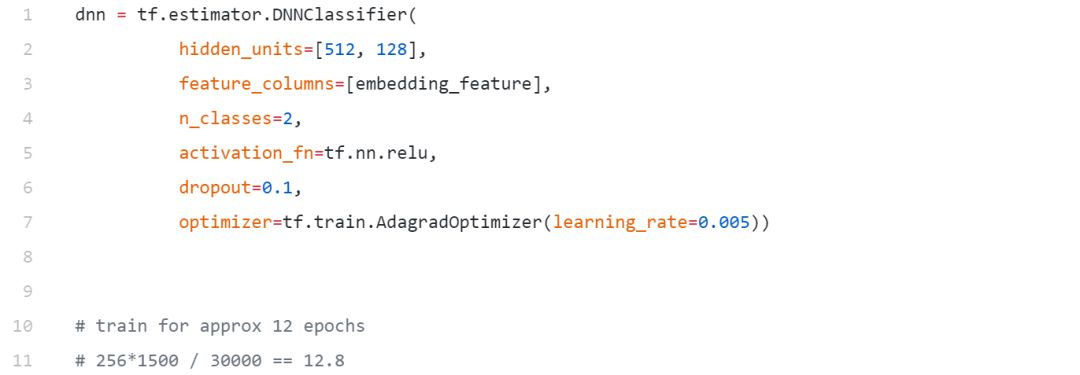
模型训练
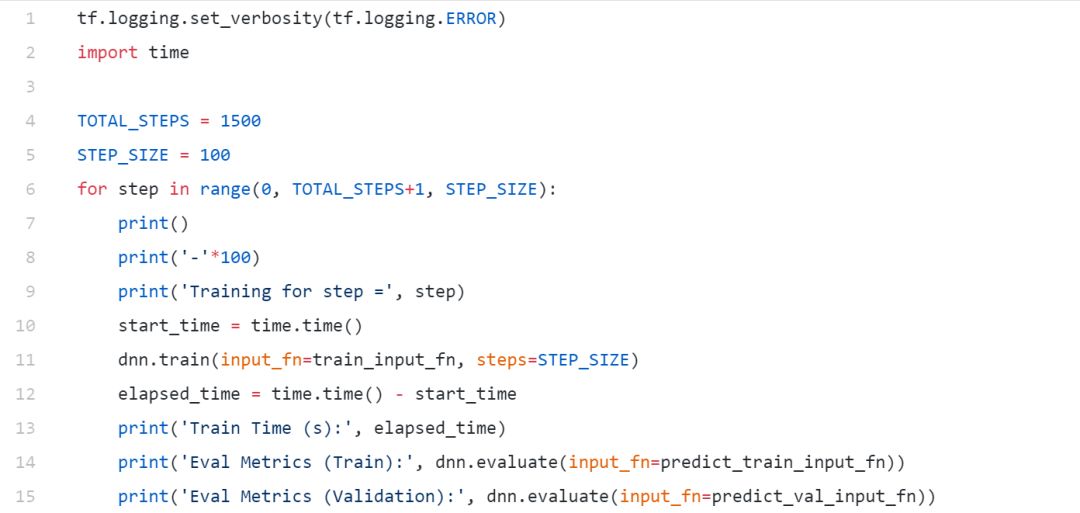




在我们的验证数据集上,我们获得了接近87%的总体精度,在这样一个简单的模型上,AUC达到了94%,这是相当好的!
模型评估
现在,让我们评估我们的模型在训练和测试数据集上的总体性能。
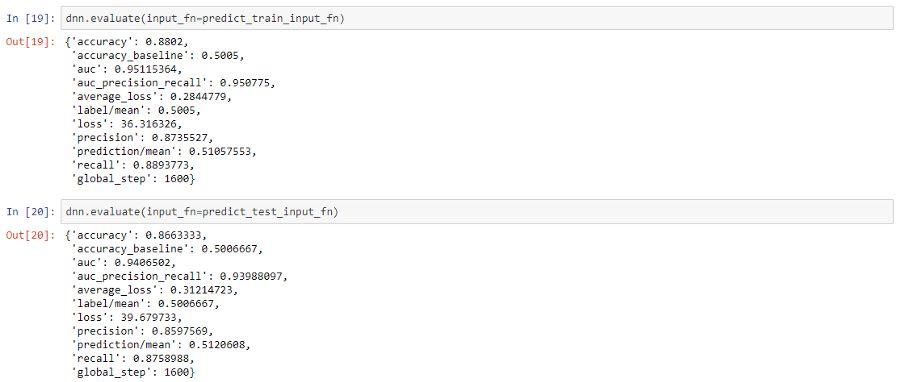
我们在测试数据上获得了接近87%的总体准确率,与我们之前在验证数据集上观察到的结果一致。因此,这应该让你了解利用经过预训练的通用语句嵌入是多么容易,而不必担心特征工程或复杂建模的麻烦。
奖励:不同通用句子嵌入的迁移学习
现在让我们尝试根据不同的句子嵌入构建不同的深度学习分类器。我们将尝试以下几点:
NNLM-128
USE-512
我们还将在这里讨论两种最突出的迁移学习方法:
使用freezed预训练语句嵌入建立模型
建立一个模型,在这个模型中,我们微调并更新训练期间预先训练过的句子嵌入



我们现在可以使用上述定义的方法来训练我们的模型。

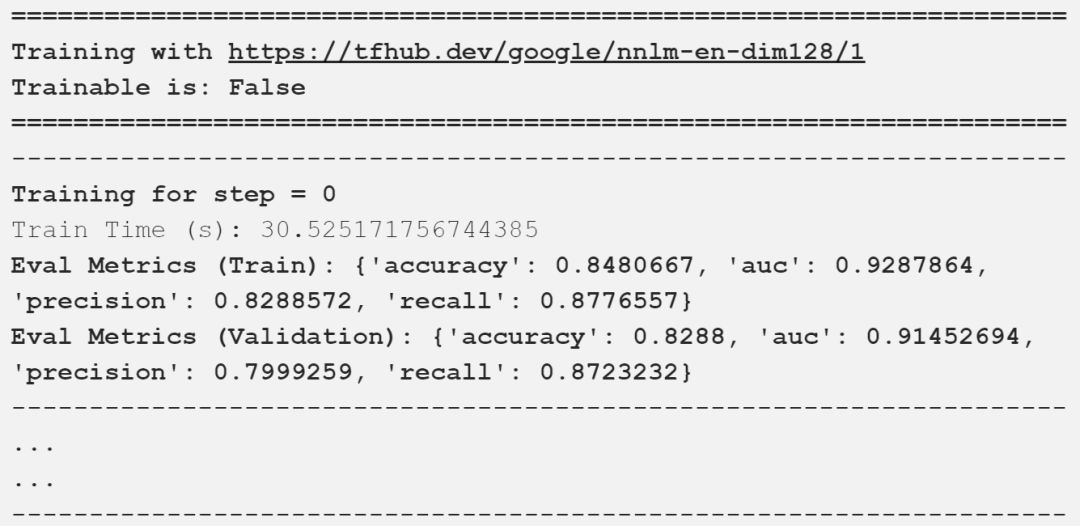
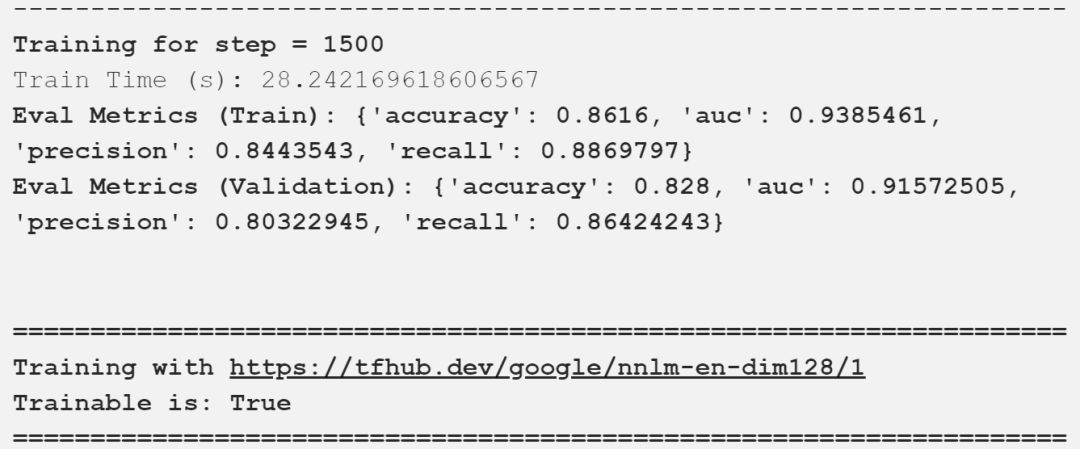
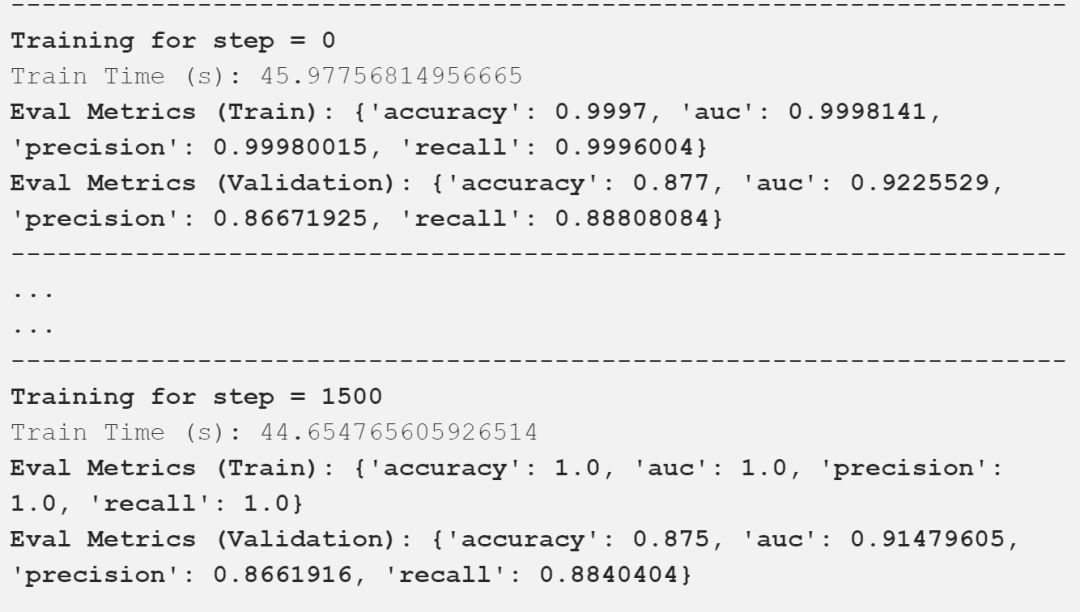
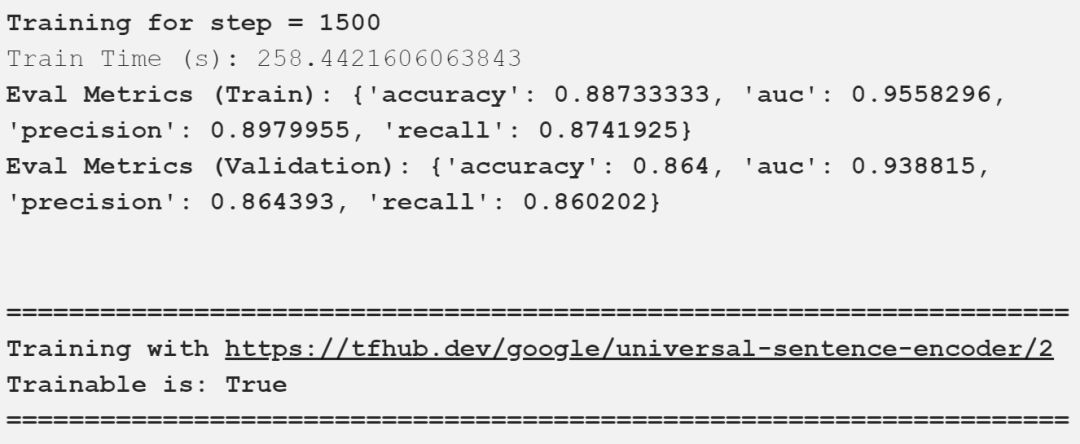
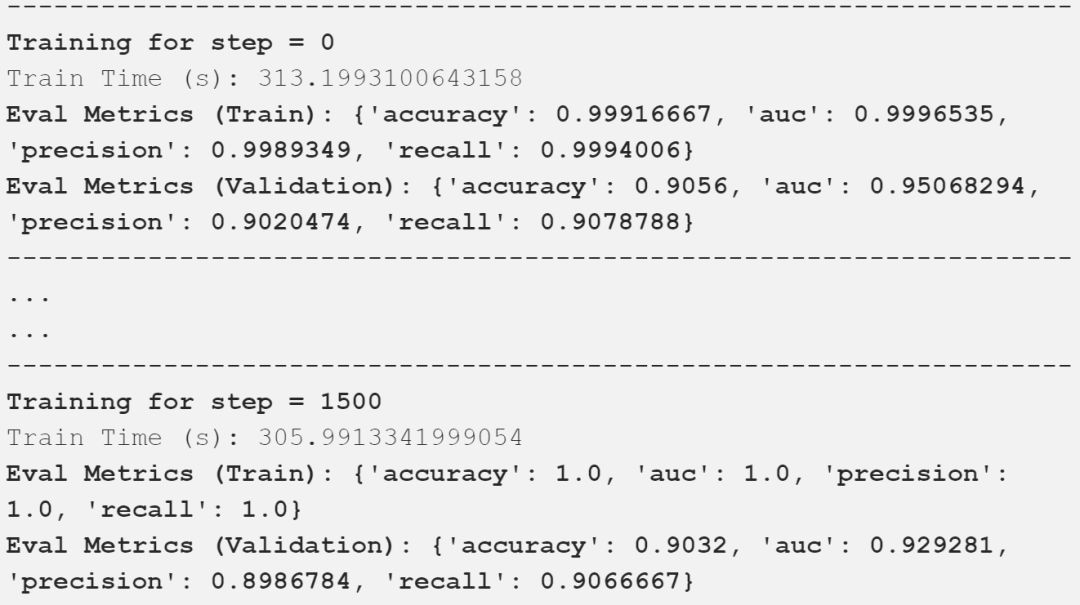
我在上面的输出中描述了重要的评估指标,可以看到,我们的模型得到了一些好的结果。下表以一种很好的方式总结了这些比较结果。


对比不同的通用句子编码器
看起来像谷歌的通用句子编码器微调给我们的测试数据最好的结果。让我们加载这个保存的模型并对测试数据进行评估。

[0, 1, 0, 1, 1, 0, 1, 1, 1, 1]
评估模型性能的最佳方法之一是以混淆矩阵的形式可视化模型预测。

从我们最好的模型预测中的混淆矩阵
我们也可以输出其他重要的指标包括准确率,召回率和F1。

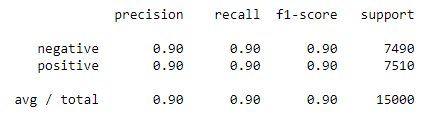
我们获得了一个整体模型的准确性和F1-分数90%的测试数据,很好。
结论
对于不同的NLP任务,通用句子嵌入无疑是在支持迁移学习方面向前迈出的一大步。事实上,我们已经看到像ELMo这样的模型,通用句子编码器,ULMFiT确实成为头条新闻,因为它展示了预先训练过的模型可以用来在NLP任务上实现最先进的结果。著名的研究科学家和博客作者塞巴斯蒂安·鲁德(SebastianRuder)在推特上提到了同样的问题。

我对NLP的进一步推广和使我们能够轻松地解决复杂任务的未来感到非常兴奋!
-
深度学习
+关注
关注
73文章
5511浏览量
121355 -
nlp
+关注
关注
1文章
489浏览量
22065
原文标题:自然语言处理中的深度迁移学习——文本预训练
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
语义理解和研究资源是自然语言处理的两大难题
什么是人工智能、机器学习、深度学习和自然语言处理?
从语言学到深度学习NLP,一文概述自然语言处理
面向自然语言处理的神经网络迁移学习的答辩PPT
斯坦福AI Lab主任、NLP大师Manning:将深度学习应用于自然语言处理领域的领军者
基于深度学习的自然语言处理对抗样本模型





 工商网监
工商网监
评论