 面向QoE的感知视频编码
面向QoE的感知视频编码
面向用户体验的感知视频编码即通过机器学习检测用户感兴趣的视觉感知区域,并重新分配以更多的码率与复杂度。本文来自北京航空航天大学副教授、博士生导师 徐迈在LiveVideoStack 线上交流分享,并由LiveVideoStack整理而成。
大家好,我是来自北京航空航天大学的徐迈。本次我将为大家分享面向QoE的感知视频编码。我们希望通过基于感知模型的视频压缩编码技术,优化产品用户体验。
本次的分享将围绕以下四个方面展开:
1.技术发展背景
用户的需求升级推动技术的不断前行,技术的进步也在不断优化产品用户体验。
十几年前,人们聚在一起庆祝新年,借助电话或短信嘘寒问暖,一起在温馨氛围中为新年到来而欢呼;而现在,人们相聚在一起庆祝新年,更多的是拿出智能手机、平板电脑等移动智能终端记录这样一个美好的瞬间。十几年的发展带来的首要影响就是数据量的激增,如何稳定高效传输大量用户随时随地采集到的音视频数据成为我们亟待解决的问题。
数据量的激增虽然为网络传输带来了巨大挑战,但也为人工智能等高新技术带来了需求与发展契机。
于是在2009年,斯坦福的李飞飞等科学家一起构筑了用于测试视觉识别性能的ImageNet数据库。初期ImageNet包含了四千多个类别的四百多万张图像,而到了2017年底其已包含两万多个类别的1400~1500万张图像。2009年ImageNet数据库的建立与当时互联网上出现的大量图像数据密切相关,直到2018年的ImageNet中已包括了5400万余张图片,不得不说这加速了机器学习在视觉识别领域的运用进程。视觉识别离不开通过大量的图片训练增强其对相似视觉元素特性的规律总结能力,我们可以将这一思路运用在编码压缩领域,通过大量的视频压缩训练使机器学习掌握洞悉视频压缩结构规律的能力,极大程度优化视频编码性能,提升用户体验。
根据统计,过去的2017年全球互联网上有1.2万亿幅图像产生,每一分钟就有几百万张图片被上传至包括Facebook、Snapchat在内的各大互联网平台;而视频的数据量则更为庞大,预计全球互联网视频数据总量将在2021年达到近2000EB。
如此庞大的数据量无疑会为图像识别与通讯网络的发展带来巨大挑战,受限于通讯资源,我们的实际传输带宽资源远没有视频数据量所要求的那么充裕;若想借助有限的带宽资源快速稳定传输大量的图像与视频数据,则离不开高效的视频编码解决方案。
讲到这里,我想我们需要回顾一下视频编码的发展历程。早期视频编码变革较快:四年间MPEG-1发展到MPEG-2,所带来的码率节省约为50%,编码效率翻倍,复杂度增长为5%左右;而H.264(AVC)发展到H.265(HEVC),虽然编码效率仍有部分提高,但其背后复杂度增长却十分显著达到了二至十倍,实测可能更高。复杂度增长是现在编码发展的一个明显趋势,而从右侧数据中我们可以看出,随着编码标准的演进,编码增益的成长也十分显著:从初期AVC的9个Modes发展到HEVC的35个Modes;除此之外,早期的MPEG-1与MPEG-2是基于8x8的DCT变换,而发展到了AVC则实现了4x4与8x8的DCT,HEVC更是实现了4x4~32x32 DCT与4x4 DST;至于H.266还引入了预测模式,60多种预测模式使得相关参数复杂程度进一步提升。从中我们不难看出,视频压缩一直基于信号处理技术并不断进行演进,而信号处理技术发展到现在已经很难再产生颠覆性革新。随着技术的发展,边际效应愈发明显,技术突破愈发困难,因此我们迫切需要一种编码压缩的新思路。
这种新思路就是结合用户感知对编码过程进行优化。用户感知与QoE紧密相关,人类视网膜大约拥有十亿视觉细胞,这使得人眼成为一台十亿像素的高清相机;大脑皮层会识别分析处理这些视觉信号,但连接人眼与大脑皮层的神经细胞仅有一万个左右,这就像一个资源十分有限的窄带带宽,那么人眼是如何利用这样一个窄带带宽传输像素高达十亿的高清视觉信号呢?这就是人作为高级动物的智慧所在:研究人的视觉感知模型我们可以发现,在人眼可感知的视角内,真正会引起大脑皮层明显兴奋的区域仅为2~3度;换句话说,人的视觉会将感知重点放在感兴趣的目标区域。由此启发,我们可通过降低感知冗余进一步提升视频压缩效率。
基于人类智慧我们提出了感知视频压缩并努力降低感知冗余。首先我们明确了如何察觉到视频感知冗余的出现,解决方案是借助机器学习与计算机视觉检测出视频画面里用户会重点关注的部分;当监测到感知冗余出现之后,我们尝试减少感知冗余与其影响,解决方案是重新分配资源,将更多码率与复杂度分配到用户感兴趣的视觉感知区域;接下来我们尝试将视频感知冗余的优化运用在全景视频之上,使得视频压缩更加契合人类的视觉习惯,也就是我们所说的面向QoE的感知视频编码。
2.基于数据驱动实现视频显著性检测
视频显著性检测是指通过计算机视觉技术推断用户观看视频时视觉感知重点集中的区域,主要借助基于机器学习的CV。其大致步骤为建库、分析与建模;我们的建库工作开始于2015年,初期主要依靠眼动仪检测志愿者观看视频时视觉关注重点的变化从而生成热点图数据库;建库之后我们对热点数据进行了特征分析,随后依据特征分析结果建立深度学习模型从而初步实现了视频显著性检测。

现在我们针对视频已建立三个包括八百多个视频的数据库,共积累七百多万个关注点。
在完成数据库的建立之后,我们对数据库进行分析,并对显著性进行可视化。上图展示的就是多位志愿者观看视频时视觉重点关注的位置变化数据,借助此数据可生成视觉热点图,偏向红色的区域代表视觉关注重点而偏向蓝色的区域则代表视觉关注程度较少,没有颜色则代表不被关注。通过上图展示的实验数据我们可以发现,人在观看视频时视觉感知系统不会过多关注视频画面的背景部分而会重点关注目标元素尤其是运动的人与物。
为了找到能够支撑上述结论的有力依据,我们尝试通过深度学习模型预测视觉关注重点。首先我们基于对目标物体的检测来构建网络,接下来针对容易吸引视觉关注的运动物体我们构建了Motion Subnet用以优化对运动物体的检测识别;在分别准确识别了物体与其运动状态之后,我们借助借助Cross-net mask实现综合分析二者数据得到运动物体的动态参数,并通过经历多次迭代的深度学习得出具备预测视觉关注重点的深度学习网络。初期此网络检测精度依旧有限只能检测识别整个运动的物体,但经过多达150K代的迭代以后,现已可实现对物体局部的某一运动部分(如汽车正在旋转的车轮)进行准确识别检测。
完成了CNN网络的构建,随后我们又将CNN网络特征输入进SS-ConvLSTM从而使得系统能够准确推测帧与帧间视觉关注重点的相关性。为了实现这样的功能,我们提出了Center-bias Dropout ,其依据在于人眼更容易将画面的中心区域作为视觉关注重点,除了人类遗传导致人的视觉系统会将视觉中央附近的物体作为感知重点之外,主要的原因还有摄影师拍摄画面时自然会把拍摄主体放在画面中央。这就使得即使系统不对视频进行内容分析,也能大致确定某视频用户的视觉关注重点会分布在画面中央附近。
除此之外我们也提出了Sparsity-weighted loss(稀疏加权损失函数),主要用于对目标物体与关注重点区域的定量分析,下图展示的是我们的定量结果,可以看到性能好于其他多种算法。
通过测试上述的分析流程我们得到了上图展示的测试数据:以人脸检测为例,“Human”行代表人类视觉实际的重点关注区域,“Ours”行代表计算机预测的视觉显著性结果,可以看到与真实区域基本重叠,而相对于下面几行代表的传统方法在准确度上优势明显。
下图展示的是我们在此研究上主要发表的论文。

3.面向一般视频的感知视频压缩编码
接下来将重点介绍有关感知视频编码在一般视频场景中的应用。
3.1 编码优化
编码优化是必不可少的优化思路。
速率失真优化
首先我们进行了速率失真优化,也就是在控制一定码率的同时尽可能降低失真或在控制失真的同时尽可能降低码率。速率失真优化主要包括借助基于感知模型的码率控制实现指标优化与基于机器学习预测压缩失真的位置与特性实现质量增强。
复杂度失真优化
复杂度失真优化主要包括以下两方面工作:首先是在保证质量的同时尽可能降低复杂度,其次是将复杂度控制在目标值之下并确保失真尽可能少。
进一步落实优化算法,我们期待通过算法尽可能减少失真与其带来的影响。
1)针对HEVC感知视频编码的闭型质量优化
根据上图展示的公式我们可以看到算法的原理是尽可能(减少第n块的码率分配)并引入Wn(Predicted Saliency)显著性预测,将其作为权重加入失真优化当中,显著性越高失真影响越大那么系统对其优化越明显。如果不引入Wn仅依赖(it模型),经过多次迭代之后客观情况下可达到5%的码率节省而在主观情况下基本可达到一半左右的码率节省。
例如上图中下半部分展示的视频画面中左侧热力图表示观众对人脸的关注重点发布,但可以比较明显地看到人物眼睛与嘴巴的位置较为模糊,严重影响观看体验;此时我们就会着重对眼睛与嘴巴区域的画面进行优化,将更多码率调整至人脸部位尤其眼睛和嘴巴的位置从而尽可能降低眼睛与嘴巴所在画面位置的失真。这种码率调整会将更多码率资源用在人脸的眼睛与嘴巴等视觉重点区域,也会同时降低背景部分的码率,这种主观保证视觉重点区域编码质量的方案可使编码效率与性能提升一倍。
2)针对视频压缩的多帧质量提升
接下来我们需要将此技术用于提升多帧画面的编码质量。通过实验我们发现,几乎所有的编码标准都会使视频质量出现明显波动,尤其HEVC编码会导致帧与帧之间的编码质量差异过大。体现在画面上的结果可能是第50、61帧质量较高画面较为清晰而到了第87帧则被遭到丢弃使其难以恢复原有质量。此时我们需要依赖87帧前后质量较高帧的帮助,进一步还原提升87帧的质量,这就是多帧质量提升操作。进行多帧质量提升之前,我们需要借助SVM对每一帧进行质量评估并选取其中质量不一的帧构造其特征并分类:ln=1代表高质量帧ln=0代表低质量帧。
在确定高质量帧与低质量帧后,系统会在处理视频的同时将低质量目标帧与其前后相邻高质量帧一并输入神经网络,借助运动补全方法使得目标帧与其前后相邻两帧像素内容一致,编码近似,凭借机器学习得到的优化算法处理这三帧从而显著提高其压缩质量。如画面当中球所在的区域,画面质量较高。
上图展示的是我们测试得到的主观指标,Ave一行代表平均测试结果。可以看到我们MFQE的质量提升平均值达到了0.5102dB,领先于前者多种算法。下图展示的是直观带来的优化体验,可以看到画面中篮球所在画面区域的质量重建提升十分明显。
3.2 复杂度降低
大家知道,H.265、H.266的最大贡献是CTU分割,并且H.266引入了二叉树与三叉树,其背后复杂程度十分惊人。例如在CU分割时,由于无法准确预判分割块的编码性能优劣,只能通过预编码也就是对RDO进行全局搜索的形式确定分割块的编码性能;由此导致的编译次数增多会使其复杂度占总体高达80%。
为了进一步降低复杂程度,我们可借助内容分析推测合适的CU分割策略。对于单帧可通过CNN挖掘其在空间上的相关性;
而对于多个相连帧可通过CNN+LSTM分析得出其在分割上的相关性与一致性。
之后我们的探索主要分为三步完成:首先是建立一个包括115个视频与两千多幅图像的数据库,接下来我们运用特征分析方法构建结构性输出,最后利用卷积神经网络预测块分割策略。
上图展示的是降低复杂度带来的性能提升。在帧间模式上我们的复杂度可降低约54%,与此同时BDBR增加约1.459%,BDPSNR损失约0.046%;对于帧内模式而言同时测试图像与视频,无论是视频还是图像其复杂度都会降低约60%,与此同时BDBR增加约2%。下图展示的是我们与此技术相关的部分技术专利。
4.面向全景视频的感知视频压缩编码
接下来将为大家介绍我们针对全景视频进行的感知压缩编码优化。
全景视频的感知压缩编码主要分为以下三个步骤:第一步进行的Model预测主要是用于判断用户观看全景视频时人眼视野关注到的画面区域;第二步进行全景视频质量评估。最后进行视频编码优化。
4.1 Model预测
人类视觉系统对全景视频的感知与普通视频存在明显区别:用户在观看全景视频时视觉不会受到画幅的限制,但人眼110度的视觉角度只占全景视频180度甚至360度广幅画面中的一部分,而人眼真正关注的视觉重点可能最多在60度左右;通俗来说用户在观看全景视频时画面中的很多内容是无法感知的。这就是我们在实现全景视频的感知压缩编码时首要解决的问题:哪些区域是用户视觉重点关注的?全景视频的视角变化与用户头部运动的状态有关,我们可从用户头部运动入手,借助机器学习对用户头部运动与设备的交互所决策的视野角度进行强化学习训练;而人类头部的运动状态与交互行为是根据全景视频内容展现的环境而改变的;这种根据环境变化得到的头部运动状态与交互反馈信息能让我们准确得到经优化构造而成的最优回报函数(Reward),让用户在自己最为感兴趣的目标画面上得到最佳的用户体验;最后我们通过深度学习进一步优化此回报函数得出其最佳策略,再将此策略运用于对用户头部运动状态的预测判断;拥有了用户头部运动状态的预测信息,我们就可以预测推断用户视野的变化并将其用于视频画面的感知压缩编码。
图中上半部分展示的是我们通过多人实验得到的可用于全景识别感知预测的DRL Network模型的架构。根据图中下半部分展示的测试结果,我们能从中得出视觉热点图。
下图同样展示了我们的定量测试结果。
4.2 全景识别与质量评估
为了实现质量评估,我们首先构建了有包括60个无失真的基准视频在内的600个全景视频的全景识别数据库。其中的基准视频采用了ERP、RCMP、TSP三种映射模式并使用27、37、42三种QP规格的压缩方式。我们请大约221个观测对象为多个全景视频集评分并使每个全景视频拥有约20个评分数据;评分同时我们也会收集被测对象头部的运动状态、视野位置、眼部运动状态等关键数据。
整理分析这些信息我们可得到多项结论:
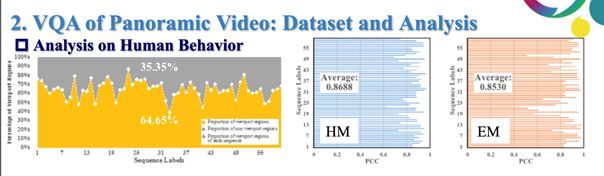
1)左侧图线代表是人们视野不关注的比例变化,平均有35%的区域是用户从未关注到的;侧图线代表头部与眼睛运动的一致性,纵坐标代表视频而横坐标代表相关系数,可以看到头部运动状态与眼部运动状态相关性保持较高,由此我们可得出结论:用户观看全景视频时的行为习惯相似,画面中有约30%的内容被视觉系统忽视。
2)用户行为与全景视频质量的关系:画面中用户看不到或者不愿意观看的非重点部分的质量变化对用户观看体验的影响微乎其微;将用户头部运动状态、视野变化、眼动状态与PSNR相结合可大幅度提升PSNR性能,即可推断出头部运动状态、眼动状态等用户行为可被用于提升全景视频质量评估性能。
基于以上研究,我们可针对全景视频提出基于深度学习的质量预测方法,也就是将头部运动状态检测与眼动状态检测得到的数据用于评估不同优化模型得出的全景视频质量并将输出的质量分数与其相关性进行比较。如传统方法得到的PCC模型预测值约为0.78,而SRCC模型则可达到0.81,从而进一步提升全景视频质量评估结果。
下图展示的是与此项研究相关的一些References。

5.总结
最后总结一下,首先我们的这些技术离不开数据的澎湃力量;其次全新的感知模型拥有非凡的编码优化潜力,最后是未来层出不穷的创新媒体渠道与应用模式离不开技术的强大力量。
-
编码技术
+关注
关注
1文章
35浏览量
11093 -
机器学习
+关注
关注
66文章
8455浏览量
133171
原文标题:编码压缩新思路:面向QoE的感知视频编码
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
处理图像和视频编码中,基于感知视频编码优化框架
面向频谱感知的传感器网络设计
Agilent N2X IPTV QoE Test Solu
基于PCI的视频编码卡的设计与实现
浅析移动通信网络中的QoE
HSDPA系统中一种感知用户终端缓存状态的QoE保障调度算法
字典学习的压缩感知视频编解码模型
AI视频编码技术创新 探索极致视觉体验
面向机器视觉的视频编码将成为5G和后5G时代的主要增量流量来源之一
什么是视频编码 常见的视频编码格式有哪些
实时互动下视频QoE端到端轻量化网络建模






 工商网监
工商网监
评论