 TensorFlow现在可以支持Unicode,这是一种标准编码系统
TensorFlow现在可以支持Unicode,这是一种标准编码系统

TensorFlow 现在可以支持 Unicode,这是一种标准编码系统,可以表示几乎所有语言的字符。处理自然语言时,了解字符的编码方式非常重要。在像英语这样的小字符集的语言中,每个字符都可以使用 ASCII 进行表示。但是这种方法对于其他语言来说并不实用,例如中文,这些语言有数千个字符。即使处理英文文本,Emojis 等特殊字符也不能用 ASCII 表示。
定义字符及其编码的最常用标准是 Unicode,它几乎支持所有语言。对于 Unicode,每个字符使用唯一的整数 code point 表示,其值介于 0 和 0x10FFFF 之间。当按顺序放置 code point 时,将形成 Unicode 字符串。
Unicode tutorial colab展示了如何在 TensorFlow 中表示 Unicode 字符串。使用 TensorFlow 时,有两种标准方式来表示 Unicode 字符串:
作为整数向量,其中每个位置包含单个 code point
作为字符串,使用字符编码将 code point 序列编码到字符串中。有许多字符编码,其中一些最常见的是 UTF-8,UTF-16 等
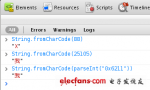
以下代码分别使用 code point、UTF-8 和 UTF-16 显示字符串 “语言处理” 的编码。
当然,您可能需要在各种表示方式之间进行转换,而 TensorFlow 1.13 已添加了执行此操作的函数:
tf.strings.unicode_decode: 将字符串标量转换为 code point 的向量(https://www.tensorflow.org/versions/r1.13/api_docs/python/tf/strings/unicode_decode)
tf.strings.unicode_encode: 将 code point 向量转换为字符串标量(https://www.tensorflow.org/versions/r1.13/api_docs/python/tf/strings/unicode_decode)
tf.strings.unicode_transcode: 将字符串标量转换为不同的编码(https://www.tensorflow.org/versions/r1.13/api_docs/python/tf/strings/unicode_transcode)
因此,如果要将上述示例中的 UTF-8 解码为 code point 向量,则可以执行以下操作:
当解码包含多个字符串的 Tensor 时,字符串可能具有不同的长度。 unicode_decode 将结果作为 RaggedTensor 返回,其中内部维度的长度根据每个字符串中的字符数而变化。
-
编码
+关注
关注
6文章
1041浏览量
57151 -
Unicode
+关注
关注
0文章
25浏览量
12950 -
tensorflow
+关注
关注
13文章
336浏览量
62388
原文标题:TensorFlow 支持 Unicode 编码
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RTT使用unicode编码,编译不通过是为什么?
一种新的IEEE 802.16系统调制编码模式切换方案
STM32是否支持汉字的Unicode码储存??
Unicode和GB2312编码互转VI
Labview GBK字符转Unicode编码 (支持混合字符)
TensorFlow常用Python扩展包
一种基于GSM和Zigbee技术的无线安防系统
一种安全的纠错网络编码
基于双向MIMO中继系统的一种预编码策略
一种实现在FPGA的编码器设计方法
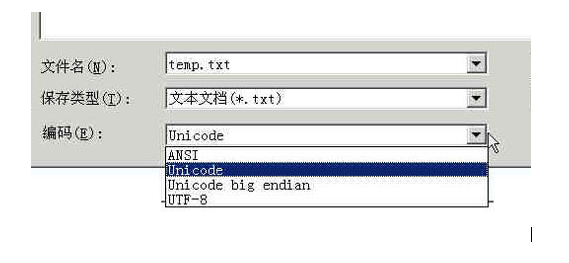
ascii和utf8的区别_ASCII编码与UTF-8的关系



评论